The fundamental problem of communication is that of reproducing at one point either exactly or approximately a message selected at another point.
Shannon
信息论是用来找出信号处理与通信操作的基本限制,涉及
要求
- 数理统计
- 概率论
- 最优化
通信系统模型
graph LR
subgraph 发信
信息-->信源编码;
信源编码-->加密;
加密-->信道编码;
信道编码-->数字调制;
end
数字调制--噪声源-->信道;
信道--噪声源-->数字调解;
subgraph 受信
数字调解-->信道译码;
信道译码-->解密;
解密-->信源译码;
信源译码-->受信者;
end
信息
信息:是事物运动状态或存在方式不确定性的描述,是对不确定性的消除
- 不确定性:接收者在收到信息之前,对它的内容是不知道的
- 信息能使认识主体对某一事物的未知性或不确定性减少
- 信息使可以量度的
不确定性大小
f(p(x))
- 必然事件:f(1)=0
- f(p(x))是单调减函数
- 独立可加性:f(p(x)p(y))=f(p(x))+f(p(y))
概率空间
[XQ]=[x1q(x1)x2q(x2)⋯⋯xnq(xn)]
- 样本空间:信源所有可能发送的消息符号
- 先验概率q(xi):选择符号xi作为发送消息的概率
香农信息定义
优点:
- 有明确的数学模型和定量计算公式
- 与日常用于中的信息含意一致
- 排除了对信息一词某些主观上的含意
局限性:
- 没有考虑收信者的主观特性和主观意义
- 定义的出发点假定事物状态可以用一个概率模型来描述
自信息
自信息量表示事件发生后,事件给予观察者的信息量(信息量:传输该信息所用的代价)。
是用来衡量单一事件发生时所包含的信息量多寡。
I(xi)=−logq(xi)=logq(xi)1
自信息量的大小取决于事件发生的概率
比如说某一随机变量的概率为1/5 , 那么它的自信息就是5比特。(自信息的单位是bite,比特)就是说这个随机变量带来5比特的信息。
- 事件发生的可能性越大,它所包含的信息量就越小
- 事件发生的概率越小,它能给与观察者的信息量就越大
性质:
- 自信息量是非负的
- 确定事件的信息量为零
- 自信息量是概率的单调递减函数
- I(x)基于随机变量X的特定取值x,不能作为整个随机变量X的信息测度
条件自信息
I(xi∣yi)=logp(xi∣yj)1
- 后验概率p(xi∣yj):接收端收到信息yj后而发送端发的是xi的概率
非平均自信息
事件x,y之间的互信息等于x的自信息减去 y条件下x的自信息,非平均互信息的最值:
I(xk:yj)=logq(xk)p(xk∣yj)=I(xk)−I(xk∣yj)=log−q(xk)1=−logq(xk)
当后验概率为1时,非平均互信息达到最大值(即无扰通信时所获取的信息最多)
离散变量的非平均自信息
对给定几何{X,q(kk)},时间xk∈X的自信息量定义为:
I(xk)=logq(xk)1
性质:集最大与最小于一身
I(xk:yj)I(xk:yj)≤I(xk)≤I(yj)
- 自信息量
- 是为了唯一(无歧义)确定事件xk的出现所必须提供的信息量
- 它也是其它任何事件所能提供的关于事件xk的最大信息量。自信息量具有非负性
- 它的另外一种解释是先验不确定性的大小
非平均条件自信息
给定联合集{U1U2,p(u1u2)}对事件u1∈U1和u2∈U2,事件u1在事件u2给定条件下的条件自信息量定义为
I(u1∣u2)=−logp(u1∣u2)
含义:
- 事件u2给定条件下关于事件u1的不确定性
- 给定事件u2时为唯一确定事件u1的出现必须提供的信息量
非平均联合自信息
联合空间XY,p(xy)中任一事件xy,x∈X和y∈Y的联合自信息量定义为:
I(xy)≜−logp(xy)
信息熵
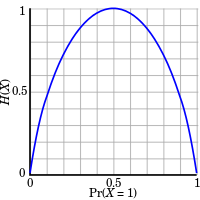
香农信息熵函数满足的三个条件:
信息熵的性质
H(p1,p2,⋯,pn)=H(pk(1),pp(2),⋯,pk(n))
H(p)≥0
H(X,Y)=H(X)+H(Y∣X)
- 条件减少性
- 知道了统计相关性的变量,则可以减少不确定性
- 统计平均意义上条件减少不确定性,但是针对具体的Y取值则不一定
H(X∣Y)≤H(X)
注意,这不是
H(X∣Y=y)≤H(X)
H(X1,X2,⋯,Xn)≤H(N1,N1,⋯,N1)=logN=log∣X∣
信息熵本质上是对我们司空见惯的不确定现象的数学化度量
离散随机变量X的信息熵
对于一个离散型随机变量X∼p(x)
H(X)=−x∈X∑p(x)logp(x)=E[logp(X)1]
- 熵实际上是随机变量X的函数logp(X)1的期望
- H的综量是随机变量的分布,而非取值
- 0log0(x→0,xlogx→0)概率为0的时间不影响信息熵
- 熵与一组信息的可压缩性紧密联系在一起
- 熵为信息的不可再降低的复杂度,即不可能再被压缩
- 约定0log0=0,因为零概率的项不改变熵的值
如果使用底为b的对数,则相应的熵记为Hb(X),当对数底为e时,熵的单位用奈特
Hb(X)=(logba)Ha(X)
唯一性:
g(MN)g(Sm)=f(MN1,⋯,MN1)=f(M1,⋯,M1)+i=1∑nM1f(N1,⋯,N1)=g(M)+g(N)=g(S⋅Sm−1)=g(S)+g(Sm−1)=mg(S)
取s,m,t,n∈N,使得sm≤tn≤sm+1,则
g(sm)mg(s)nm≤g(tn)≤ng(t)≤g(s)g(t)≤g(sm+1)≤(m+1)g(sm)<nm+1
于是∣nm−g(s)g(t)∣<n1
由
mlogS≤nlogt<(m+1)logS
得到
∣nm−logslogt∣<n1
使用∣a±b∣≤∣a∣+∣b∣,得到
∣g(s)g(t)−logslogt∣≤n2
让n趋近+∞得到
g(s)g(t)→logslogt
于是g(t)=Clogt
假设分布律X∼Px(x),令P(n)为
P(n)g(M)=∑i=1nmimn=Mmn=f(M1,⋯,M1)=f(P1,P2,⋯,PN)+i=1∑NMmng(mn)
现在看看f(P1,P2,⋯,PN)是什么形式
f(P1,P2,⋯,PN)=g(M)−i=1∑MPig(mi)=ClogM−i=1∑MPiClogmi=ClogM(∑Pi)−i=1∑MPiClogmi=−Ci=1∑MPi(logmi−logM)=−C∑PilogPi
联合熵
一对离散随机变量(X,Y)的联合熵定义为:
H(X,Y)=−x∈X∑y∈Y∑p(x,y)logp(x,y)=E[logp(x,y)1]
条件熵
若(X,Y)∼p(x,y),则条件熵H(Y∣X)定义为:
H(Y∣X)=x∈X∑p(x)H(Y∣X=x)=−x∈X∑p(x)y∈Y∑p(y∣x)logp(y∣x)=−x∈X∑y∈Y∑p(x,y)logp(y∣x)
条件熵与联合熵的关系
H(X,Y)=H(X)+H(Y∣X)=H(Y)+H(X∣Y)
由统计的公式,两边取对数再取期望
p(x,y)=p(x)p(y∣x)
可以证明出
若X,Y统计独立,则
H(X,Y)=H(X)+H(Y)
在得知某一确定信息的基础上获取另外一个信息时所获得的信息量。
定理:设随机变量X1X2⋯Xn满足分布p(x1,x2,⋯,xn),则
H(X1,X2,⋯,Xn)=i=1∑nH(Xi∣Xi−1⋯X1)
互信息
假设有以下关系
graph LR
随机变量X --某种操作和联系--> 随机变量Y;
- 单独观察X,得到的信息量是H(X)
- 已知Y之后,X的信息量变为H(X∣Y)
- 了解了Y之后,X的信息量减少了H(X)−H(X∣Y)
- 这个减少量是得知Y取值之后提供的关于X的信息
互信息I(X:Y)则表示为知道事实Y后,原来信息量减少了多少。
离散随机变量X与Y之间的互信息为
I(X:Y)=⎩⎪⎨⎪⎧H(X)−H(X∣Y)∑x∈X∑y∈Yp(x,y)logp(x)p(y)p(x,y)H(X)+H(Y)−H(X,Y)
- 若X,Y独立,则I(X,Y)=0
- 若X,Y一一映射,则I(X,Y)=H(X)
假定X是信道的输入,Y是信道的输出
graph LR
输入信道X-p --信道转移概率矩阵Q--> 信道输出Y;
- 用p和Q=[q(y∣x)]表示互信息
- I(X;Y)=I(p;Q)=∑x∈X∑y∈Yp(x)q(y∣x)logp(x)q(y∣x)q(y∣x)
- p:信道输入的条件分布
- Q:信道的噪声模型
- I(X;Y)表示了一个信道输入与输出之间的依赖关系→信道的传输能力
多变量的互信息
设有随机变量X,Y与Z之间的互信息为
I(X;Y;Z)=⎩⎪⎨⎪⎧H(X)−H(X∣Y,Z)=H(Y,Z)−H(Y,Z∣X)∑x∈X∑y∈Y∑z∈Zp(x,y,z)logp(x)p(x∣y,z)∑x∈X∑y∈Y∑z∈Zp(x,y,z)logp(x)p(y,z)p(x,y,z)
graph LR
随机变量X --某种操作或联系--> 输出;
多变量的条件互信息
设有随机变量X,Y与Z
I(X;Y∣Z)=⎩⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎧H(X∣Z)−H(X∣Y,Z)H(Y∣Z)−H(Y∣X,Z)∑x∈X∑y∈Y∑z∈Zp(x,y,z)logp(x∣z)p(y∣z)p(x,y∣z)H(X∣Z)−H(X,Y∣Z)+H(Y∣Z)H(X,Z)−H(Z)−H(X,Y,Z)+H(Z)+H(Y,Z)−H(Z)H(X,Z)+H(Y,Z)−H(X,Y,Z)−H(Z)
- 条件互信息非负:I(X;Y)≥0
- 对称性:I(X;Y)=I(Y;X)
- 极值性:I(X;Y)≤min(H(X),H(Y))
- 2个随机变量的互信息不可能提供比随机变量自身还大的信息量
- 可加性:I(X1,X2,⋯,Xn∣Y)=∑i=1n(Xi;Y∣X1,⋯,Xi−1)
信息论的证明
- Achievability:可达性
- 用某种编码或压缩的方法,证明某一个特定的指标是可以实现的
- Converse:逆
- 你不可能比某一个边界更好
- 若与Achievability相等,则证明达到最好
鉴别信息(相对熵)
两个概率密度函数p(x)和q(x)之间的鉴别信息(交叉熵,相对熵)定义为
D(p∥q)=x∈X∑p(x)logq(x)p(x)
- 两个概率密度函数的距离的度量
- p=q时,鉴别信息为0
- 鉴别信息非负
- 不是严格距离上的距离
熵,互信息,鉴别信息的关系
- 离散变量的熵与鉴别信息的关系满足(u为均匀分布)
- log∣X∣是最大熵,在分布为u的时候取得
- D(p∥u)是均匀分布与实际分布之间的差异的度量
H(X)=log∣X∣−D(p∥u)
- 香农熵是由均匀分布走向实际分布过,所减少的那部分信息量从均匀分布中所减去剩余的那一部分
- 当分布律未知时,最合理的推断的分布为均匀分布
- log∣X∣:均匀分布下的信息量
离散变量的互信息与鉴别信息的关系满足
I(X;Y)=D(p(x,y)∥p(x)p(y))
意义:当随机变量X,Y分布p(x,y)时,我们假定二者独立,上述定义给出这种假定距离实际情况差异大小
| 名字 |
公式 |
意义 |
| 熵 |
H(X)=−∑x∈Xp(x)logp(x) |
不确定现象的数学化度量 |
| 联合熵 |
H(X,Y)=−∑x∈X∑y∈Yp(x,y)logp(x,y) |
观察一个多个随机变量的随机系统获得的信息量 |
| 条件熵 |
H(Y∣X)=∑x∈Xp(x)H(Y∣X=x) |
在得知某一确定信息的基础上获取另外一个信息时所获得的信息量 |
| 自信息 |
I(xi)=−logq(xi) |
事件给予观察者的信息量 |
| 互信息 |
I(X:Y)=H(X)−H(X∣Y) |
知道事实Y后,原来信息量减少了多少 |
| 鉴别信息 |
D(p∥q)=∑x∈Xp(x)logq(x)p(x) |
某一个随机变量2种分布的距离 |

注意:H(Y∣X)=H(X∣Y),但是H(X)−H(X∣Y)=H(Y)−H(Y∣X)
Jenson不等式
如果f是下凸函数,且X是离散随机变量,则
Ef(X)≥f(EX)
并且,若f是严格下凸函数,上式的等号说明X为常数,即X与EX以概率1相等
- 统计平均可以看作是一个线性组合的操作
- 函数的统计平均大于等于统计平均的函数值
对数求和不等式
对于非负实数a1,a2,⋯,an和b1,b2,⋯,bn有
i=1∑nailogbiai≥(i=1∑nai)log∑i=1nbi∑i=1nai
等号当且仅当biai为常数的时候成立
证明:
设函数f(t)=tlogt,(t>0)是凸函数
∑aif(ti)≥f(∑aiti)
令ai=Bbi,ti=biai,b=∑bi,则
∑Bbibiailogbiai∑(ailogbiai)≥∑Bbibiailog∑Bbi≥∑ailog∑bi∑ai
鉴别信息的凸性
D(p∥u)是(p,q)的下凸函数,即若存在分布对(p1,q1)和(p2,q2),则
D(λp1+(1−λ)p2∥λq1+(1−λ)q2)≤λD(p1∥q1)+(1−λ)D(p2∥q2)
对于所有0≤λ≤1成立
上述式子的即:这两个分布对的线性组合之间的鉴别信息是小于两个鉴别信息的线性组合
证明:
设λ∈[0,1],λ=1−λ
λp1(x)+λp2(x)logλq1(x)+λq2(x)λp1(x)+λp2(x)D(λp1+λp2∥λq1+λq2)≤λp1(x)q1(x)p1(x)+λp2(x)logq2(x)p2(x)≤λD(p1∥q1)+λD(p2∥q2)
熵的上凸性
熵函数是随机分布p的上凸函数
H(px)=log∣X∣−D(px∥u)=linear−convex=concave
信源X0∼p0(x)信源编码器X′∼p0(x)
互信息的上凸性
graph LR
输入信道X-p --信道转移概率矩阵Q--> 信道输出Y;
固定Q,互信息是p的上凸函数
证明:
固定Q=[q(y∣x)]
I(X;Y)=H(Y)−H(Y∣X)=H(Y)−x∈X∑p(x)H(Y∣X=x)
我们注意到H(Y)是基于Px(x)的上凸函数
H(Y∣X)=x∑p(x)y∑q(y∣x)logq(y∣x)1
可以知道H(X∣Y)是基于Px(x)的线性函数,即I(X;Y)针对Px(x)是上凸的
Fano不等式
定义错误概率:Pe=Pr{X^=X}
随机变量X处理随机变量Y处理估计值X^
对于任意估计X^,满足X→Y→X^,且Pe=Pr{X^=X},则
H(Pe)=Pelog∣X∣≥H(X∣X^)≥H(X∣Y)
证明
定义分布E为
E={0,1,X=X^X=X^⟹H(E)=H(Pe)
观察一下等式
H(E,X∣X^)+H(X∣X^)+H(E∣X,X^)=H(X∣X^)
当X,X^取值都已知的情况下,H(E∣X,X^)=0,再观察
H(E,X∣X^)=H(E∣X^)+H(X∣E,X^)≤H(Pe)+PeH(X∣X^=X,X^)+(1−Pe)H(X∣X^=X,X^)≤H(Pe)+Pelog∣X∣
即可得出
H(X∣X^)≤H(Pe)+Pelog∣X∣
数据处理不等式
当我们有了一系列数据处理的操作,且彼此之间独立,随着处理流程的推进,处理出来的结论,它与原始的素材之间的互信息是不会增加的,只会越来越小,称为数据处理定理
p(x,y,z)=p(x)p(y∣x)p(z∣y)⇒X→Y→Z
以上称为马尔科夫链
X→Y→Z蕴含Z→Y→X
I(X;Y)I(X;YZ)I(X;Y)H(X∣Z)≥I(X;Z)=I(X;Y)+I(X;Z∣Y)=I(X:X^)+I(X;Y∣Z)≥I(X;Z)≥H(X∣Y)
连续随机变量的微分熵
定义连续随机变量
h(X)=−∫−∞+∞p(x)logp(x)dx
h(X,Y)=−∬p(x,y)logp(x,y)dxdy
h(X∣Y)=−∬p(x,y)logp(x∣y)dxdy=−∫p(y)∫p(x∣y)logp(x∣y)dxdy
h(X,Y)h(X∣Y)h(X,Y)=h(X)+h(Y∣X)=h(Y)+h(X∣Y)≤h(X),h(Y∣X)≤h(X)≤h(X)+h(Y)
正态分布的微分熵
X:p(x)=2πσ1e−2σ2(x−u)2−∞<x<∞
h(X)=−∫−∞+∞p(x)logp(x)dx=−∫−∞+∞p(x)log(2πσ1e−2σ2(x−u)2)dx=−∫−∞+∞p(x)log2πσ1dx+loge∫−∞+∞p(x)2σ2(x−u)2dx=log2πσ2+2σ2loge∫−∞+∞p(x)(x−m)2dx=log2πσ2+21loge=21log2πeσ2
h(X)=21log2πeσ2
- σ2:该随机信号的功率
- 如果一个连续随机变量服从正态分布,它带来的信息量与均值μ无关,只与功率σ2有关
- 若给定连续随机变量X的均值μ与方差σ2,则当其服从正态分布时,微分熵最大
连续随机变量的互信息
采用类似于微分熵的推广方法求随机变量变量的互信息为
I(X;Y)=Δx→0Δy→0limi=−∞∑+∞j=−∞∑+∞p(xi,yj)ΔxiΔyilogp(xi′)Δxip(yj′)Δyip(xi,yiΔxiΔyi)=∬p(x,y)logp(x)p(y)p(x,y)dxdy
信源
渐进等同分割性质
最大离散熵原理:等概分布时,离散熵最大化
问题:如何将非等概率输出的信源变成等概
一个随机变量,他是均匀分布的,我们对他进行一个定长的切割,如下图
- 每一段的长度由1→+∞
- 这样差不多所有的事件都是等概出现的
- 可以简单地由弱大数定理推出
- 对于数据压缩有贡献
- 等同分割⟶等概率⟶最大离散熵⟶定长编码定理
- 暗示了一种定长编码的方法
如果X1,X2,⋯,Xn是独立同分布的离散随机变量,分布服从p(x),则
n1logp(X1,X2,⋯,Xn)PH(X)
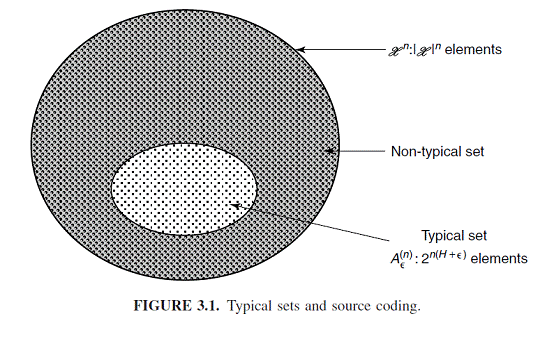
典型序列
相对于分布p(x)和序列(x1,x2,⋯,xn)∈Xn,典型序列集合Aε(n)定义为满足下列不等式约束的所有序列x的集合
2−n(H(X)+ε)≤p(x)=p(x1,x2,⋯,xn)≤2−n(H(X)−ε)
- 若x∈Aε(n),则H(X)−ε≤−n1logp(x)≤H(X)−ε
- 若n足够大,Pr{Aε(n)}>1−ε,即几乎总是看到典型序列
- ∣Aε(n)∣≤2n(H(X)+ε)
- ∣Aε(n)∣≥(1−ε)2n(H(X)+ε)
- 典型序列的集合只是所有集合的一个子集,但是几乎一定会出现,且数量大概为
2nH(X)
- 随着n的增大,所有典型序列出现的概率,几乎是一样的,几率大概是
2−nH(X)
证明:
1∣Aε(n)∣=xn∈X∑p(xn)≥xn∈Aε(n)∑p(xn)≥xn∈Aε(n)∑2−n(H(X)+ε)=2−n(H(X)+ε)∣Aε(n)∣≤2n(H(X)+ε)
1−ε∣Aε(n)∣≤P0{Aε(n)}≤xn∈Aε(n)∑2−n(H(X)−ε)=2−n(H(X)−ε)∣Aε(n)∣≥(1−ε)2n(H(X)−ε)
定长编码定理
设Xn是由独立同分布离散随机变量x∼P(x)构成的序列,对于任意正数ε,总有足够大的n,可以找到一个一一映射,将Xn
映射为二进制序列,且满足
E[n1l(Xn)]≥H(X)+ε
使用nH(X)比特足以描述n个独立同分布的随机变量
证明:
E(l(Xn))=xn∈Xn∑=xn∈Aεn∑p(xn)l(xn)+xn∈Aεn∑p(xn)l(xn)
也就是,将一段序列分为n段,每一段的长度,等于典型序列长度的期望+非典型序列长度的期望,由典型序列的性质三,我们可以得到下面的式子
E(l(Xn))≤xn∈Aεn∑p(xn)[n(H(X)+ε)+1+1]+xn∈Aεn∑p(xn)[nlog∣X∣+1+1]
其中
- 第一个+1是为了保证n(H(X)+ε)是整数
- 第二个+1是为了标识现在编码是一个(非)典型序列,而不是其他的,用来作区分
- 对于非典型(后边的式子),索性全部编码
进行化简可以得到
=Pr{Aε(n)}[n(H+ε)+2]+Pr{Aε(n)}[nlog∣X∣+2]
其中
{Pr{Aε(n)}<1Pr{Aε(n)}<ε
即可得到
≤n(H+ε)+2+nεlog∣X∣+2ε=n(H+ε′),ε′=ε+εlog∣X∣+n2ε
其中对于ε′
n→∞,ε′→0
其含义为,当n趋向∞,每一段的期望大小逼近nH
例题:设信源输出符号分布为
(Xp(x))=(a10.40a20.18a30.10a40.10a50.07a60.06a70.05a80.04)
希望编码错误概率小于10−8,且编码效率大于90%,求最小可行分组长度
解:
编码效率=用长度为n的典型序列编码后每个信源字母的平均符号数H(X)>H(X)+εH(X)>0.9
解得ε<0.28,而编码错误概率为P{Aε(n)},即非典型序列出现的概率,有
P{Aε(n)}≤Nε2D(I(X))≤10−8
计算可得
N>10−8ε2D(I(X))>10−8⋅(0.28)21.31>108
非奇异码
若一个码C可以将不同的x映射为不同的D∗中的序列,即
x=x′⇒C(x)=C(x′)
则称该码是非奇异的,类似映射的单射
- 非奇异码可以将符号唯一的恢复,但是当信源输出符号序列的时候,会失败
- 例如:C(x1)=0,C(x2)=1,C(x3)=01就会出错
- 解决的方法是再输出码字之间加入间隔符,这是低效的做法
- 解决方法是寻找自断句的码方案
唯一课译码
称码C∗是码C的扩展,当C∗是有限长X的序列到有限长D−进制序列的映射,且满足
C(x1x2⋯xn)=C(x1)C(x2)⋯C(xn)
- 例如:C(x1)=00,C(x2)=11,C(x1x2)=0011
称码C是唯一可译码,当其扩展是非奇异的
- 也就是说:没有码字是码字的组合
- 例如C(x1)=0,C(x2)=01,C(x3)=11,则序列
00110010唯一可译为x1x1x3x1x2x1
- 但是,此时译码需要"回退",即要缓存来判别
即时码
称一个码是即时码或者前缀码,当没有码字是其他码字的前缀
- 即时码可以立刻译出,而无需借助后续的码字信息
- 例如:C(1)=0,C(2)=10,C(3)=110,C(4)=111
- 则系列
01011111010可以立刻断句为0,10,111,110,10
- 前缀码是一种具有很好性质的码
前缀码约束条件 - Kraft不等式
- 欲用即时前缀码对信源进行编码
- 显然不能使用所有的最短的码字,否则前缀码的条件将无法满足
任意D−进制码前缀码其码长l1,l2,⋯,lm,满足
i∑D−li≤1
反之,若码长约束满足上述不等式,则必然可以构造出一个具有此码长的前缀码
- Kraft不等式给出了即时码(前缀码)的充要条件
- Kraft不等式是纯粹编码构造的考虑,与码是否最优无关
任意前缀码码长的约束
对随机变量X进行D−进制前缀码编码,得到的码长L满足
L≥HD(X)
等号当且仅当D−li=pi时成立
- 物理意义:平均码长不会比熵率更小
- 与由APE导出的定长编码定理结论一致
- HD(X):以D为底的熵
证明:
L−H(X)=∑pili−∑pilogpi1=∑pilogDDei+∑pilogDpi
令ri为经验分布ΔD−ei,Δ=∑D−ei,于是
L−H(X)=D(p∥r)+logΔ1≥0
- 其中鉴别信息D(p∥r)>≥0(鉴别信息的性质)
- Δ≤1⇒logΔ1≥0
即可得到
L≥H(X)
即证明了,用D−进制前缀码对于随机变量X进行编码,得到的所有的码字的平均长度都大于HD(X)
香农第一定理(最优前缀码定理)
对随机变量X进行D−进制前缀码编码,得到的最优码长L∗满足下列不等式
HD(X)≤L∗<HD(X)+1
证明:
取⌈logpi1⌉为码字长度,则
∑D−⌈logpi1⌉logDpi1HD(X)HD(X)≤∑Dlogp11=∑pi=1≤li≤logDpi1+1≤∑pili≤HD(X)+1≤L∗≤∑pili=Lshammo≤HD(X)+1
分组前缀码
对于信源X进行分组前缀编码,得到的每消息符号数Ln∗满足不等式
nH(X1,X2,⋯,Xn)≤Ln∗<nH(X1,X2,⋯,Xn)+n1
进一步,若信源稳恒,有
Ln∗→H(X)
编码效率与互信息
- 最优前缀码的编码与信源的分布密切相关
- 如果对信源分布估计出现差错,对码长也会有影响(Penalty)
对于服从p(x)信源X进行前缀编码,若码字长度取l(x)=⌈logpi1⌉,则平均码长满足
H(p)+D(p∥q)≤Epl(X)<H(p)+D(p∥q)+1
这里的意义也就是,我们认为我们知道X的分布,但是其实我们不知道,这里码长的增加量也就是我们估计错的惩罚
Shannon编码
li=⌈logpi1⌉
- Shannon编码虽然可以满足编码定理给出的
1 bite/符号的开销约束,但是一般情况下不是最优的编码
Huffman编码
- Huffman编码具有最优性
- 在给定信源符号的概率分布和码字母表的前提下,没有其他编码可以获得比Huffman编码更短的平均码长
考虑对具有以下分布的无记忆稳恒信源进行二进制Huffman编码
(10.2520.2530.240.1550.15)
- 当D≥3时,需要填充概率为零的字母进入信源字母表,以保证编码顺利进行
- 每次迭代缩减,减少的信源字母个数为D−1个,因此填充后信源字母总个数应该为1+k(D−1)个
最优码由很多,将一个最优码码字的位倒叙,交换具有相同长度的两个码字,都是另外一个最优码
对任意一个分布,必然存在满足如下性质的一个最优即时码
- 其长度序列与按概率分布列排序的次序相反
- 最长的两个码字具有相同长度
- 最长的两个码字仅在最后一位上有所差别,且对应于两个最小可能发送的字符
信道容量
- 通信是什么
- 物理实体A的作用引发了物理实体B的状态变化
- 若A与B的状态变化存在一致性,称A与B通信成功
- 从信息角度看通信本质
信息信道编码器x∗信道q(y|x)y∗信道解码器w′消息的估计
信道的分类
| 取值 |
时间 |
信道分类 |
| 离散 |
离散 |
离散信道、数字信道 |
| 连续 |
离散 |
连续信道 |
| 连续 |
连续 |
模拟信道 |
| 离散 |
连续 |
|
按照信道随机过程的特点分类
Qt1t2⋯tn={q(yt1t2⋯tn∣xt1t2⋯tn)}
- 无记忆信道
- 由输出到输出转移的行为是彼此不相关
- 信道噪声的特性是彼此不相关
q(y1y2⋯yn∣x1x2⋯xn)=i=1∏nq(yi∣xi)
q(yi∣xi)=q(y∣x)
离散无记忆信道(DMC)
XQ={q(y∣x)}Y
I(Xn;Yn)H(Yn)H(Yn∣Xn)=H(Yn)−H(Yn∣Xn)≤i=1∑nI(xi;yi)=H(Y1)+H(Y2∣Y1)+H(Y3∣Y1Y2)+⋯≤i=1∑nH(Yi)=−EX,Ylogq(yn∣xn)=−EX,Ylogi=1∏nq(yi∣xi)=−−EX,Yi=1∑nlogq(yi∣xi)=−i=1∑n−EX,Ylogq(yi∣xi)=i=1∑nH(Yi∣Xi)
信道输入和输出的互信息 ≤ 每一个时刻互信息求和
有多字母表述走向单字母表述,为了求最大
- 求等号
- 使I(xi;yi)最大
离散无记忆信道的输入和输出
设信道输入X=(X1,X2,⋯,Xm),输出为Y=(Y1,Y2,⋯,Yn),对于离散无记忆信道,有
I(X;Y)≤i=1∑nI(Xi;Yi)
信道容量的定义
对于离散无记忆信道,信道容量为:
C=p(x)maxI(X;Y)=p(x)maxI(p,Q)
- 关于信道容量
- C的量纲:比特
- 最大值:跑遍所有输入分布的条件下获得的
离散无记忆信道容量
由于信息无差错,所以每次传输都传递了1比特的无差错信息,直观的,信道容量为1bit
C=maxI(X;Y)=H(X)−H(X∣Y)=maxH(X)=1bitp(x)=(0.5,0.5)
- 信道存在噪声,因而输出不确定
- 不确定性不影响正确估计输入
- 因此,信道实际是无差错的
C=maxI(X;Y)=H(X)−H(X∣Y)=maxH(X)=1bitp(x)=(0.5,0.5)
C=p(x)maxI(X;Y)
关注
I(X;Y)CBSC=H(Y)−H(Y∣X)=H(Y)−H(p)≤1−H(p)=1−H(p)
I(X;Y)CBSC=H(Y)−H(Y∣X)=H(Y)−H(p)=H((π(1−p),p,(1−π,1−p)))−H(p)=(1−p)H(π)+H(p)−H(p)=(1−p)H(π)≤1−p=1−p
对称信道
若信道的转移概率矩阵的
- 行互为置换,列互为置换,称该信道对称
- 行互为置换,各列之和相等,称该信道弱对称
⎣⎡216131312161613121⎦⎤[313161212161]
- H(Y∣X)是不已X的分布为转移的,始终是一个常数
弱对称信道
弱对称信道Q的容量为
C=log∣Y∣−H(Q的行向量对应的分布)
容量在输入为等概率分布的时候取得
一般无记忆离散信道
由I(p,Q)是p的上凸函数,求信道容量问题可以表述成一个约束极值问题
maxs.t.I(p,Q)X∑p(x)=1p(x)≥0
对于信道矩阵为Q的离散无记忆信道,其输入分布p∗能使互信息I(p,Q)取得最大值的充要条件是
I(X=xk;Y)=CI(X=xk;Y)≤Cxk:p∗(xk)>0xk:p∗(xk)=0
其中
I(X=xk;Y)=j=1∑Jq(yj∣xk)logp(yj)q(yj∣xk)
表示的是信源字母xk传送的平均互信息,C为信道容量
可以对任何一个离散无记忆信道进行信道容量的单字母表达下的计算
Kuhn-Tucker条件
设f(x)为定义在N维无穷凸集S={x=(x1,x2,⋯,xn):xi≥0,i=1,2,⋯,N上的可微上凸函数,设x∗=(x1∗,x2∗,⋯,xn∗)∈S,则f(x)在x=x∗达到S上的极大值的充要条件是
∂xn∂f(x)∣∣x=x∗=0,if xn∗>0∂xn∂f(x)∣∣x=x∗≤0,if xn∗=0
- x∗=(x1∗,x2∗,⋯,xn∗),xn∗>0时,x∗为S的内点,∃xn∗=0时,x∗为S的边界点。
- 此条件是充要条件
信道的组合
级联的独立信道
graph LR
Start --X--> 信道Q1;
信道Q1 --Y--> 信道Q2;
信道Q2 --Z--> End;
- 数据处理定理:I(Y;Z)≥I(X;Z)
- 一般的,随着串联信道数目的增多,其容量趋近于0
- 将联级信道的Qi乘起来,得到整个级联信道的Q,即可求解级联信道的容量
- Vision:从统计的角度上看,数据处理不会带来增益,反而会丢失信息
输入并联信道
- 特点:输入相同的X,输出不同的Y1,Y2,⋯构成随即矢量Y
- 输入并联信道的容量大于任何一个单独的信道,小于max H(X)
- N个二元堆成信道输入并联之后的信道容量,N越大,CN越大,越接近H(X)
- Vision通信中的分集,就是典型的输入并联信道
graph LR
X--X1-->信道1;
X--X2-->信道2;
X--Xn-->信道n;
信道1--Y1-->Y;
信道2--Y2-->Y;
信道n--Yn-->Y;
并联信道
graph LR
X--X1-->信道1;
X--X2-->信道2;
X--Xn-->信道n;
信道1--Y1-->Y;
信道2--Y2-->Y;
信道n--Yn-->Y;
- 多输入,多输出,X和Y由彼此独立的N个信道传输
- 并用信道的容量:C=∑n=1NCn
- Vision通信中的复用,就是典型的并用信道
- 例子:ADSL拨号上网,蜂窝网络
和信道
graph LR
X-->信道1;
X-->信道2;
X-->信道n;
信道1-->Y;
信道2-->Y;
信道n-->Y;
- 随机应用N个信道中的一个,构成一输入/输出信道
- 和信道的容量是:C=log∑n=1N2Cn
- 信道的使用概率:pn(C)=2(Cn−C)
- Vision:一种新型的通信技术
⎝⎜⎜⎜⎜⎛1−ε1ε1−−−00ε11−ε1−−−00∣∣−−−∣∣00−−−ε21−ε100−−−1−ε2ε2⎠⎟⎟⎟⎟⎞
graph LR
X-->BSC1;
X-->BSC2;
BSC1-->Y;
BSC2-->Y;
C=log2(2C1+2C2)ε1=0,C1=1;ε2=0.5,C2=0C=log(21+20)=log23>1
连续信道的容量
- 连续信道
- 时间依旧连续
- 但是取值:离散 → 连续
- 引发的问题
- 离散随机变量的互信息非负,有限
- 取I(p,Q)最大值得到离散信道的容量
- 连续随机变量互信息非负,但不一定有限
- 这样互信息的最大值为信道容量的定义就失去了意义
- 因此我们需要一个费用的限制,在这个限制下,进行讨论
设对于连续无记忆信道{X,q(y∣x),Y},有一个函数b(.),称b为x的费用。设随机矢量x=x1x2⋯xn的联合分布为p(x),则平均费用为
E(b(X))≜x∑p(x)b(x)
连续信道的"容量-费用函数"
在费用约束的前提下,求输入输出互信息的最大值,得到容量-费用函数
设连续信道的N维联合输入输出分别为X和Y,则其容量-费用函数定义为:
C(β)=N→∞limN1p(x)max{I(X;Y):E(b(X)≥Nβ)}
可以理解为功率,在给定功率的情况下,去讨论信道的容量
加性噪声信道
X⟶Z⇓+⟶Y
maxs.t.C(Ps)=maxI(X;Y)p(x):Ex(x2)≤Ps
q(y∣x)=Pz(y−x)=Pz(Z)
当X确定的时,Y的分布仅和Z的分布相关
h(Y∣X)=−∬XYPx(x)q(y∣x)logq(y∣x)dxdy=−∬XYPx(X)Pz(y−x)logPz(y−x)dxdy=−∬Px(X)Pz(Z)logPz(Z)dxdz=−∫zP(Z)logP(Z)dz=h(Z)
加性高斯信道
看看加性高斯信道
X⟶Z∼N(0,Pz)⇓+⟶Y
我们先看Y的功率,X和Z相互独立
E(Y2)=E((X+Z)2)=E(X2)+E(Z2)=Ps+Ps
当我们让Y取得一个正态分布,则h(Y)可以取得最大值
也就是Y的功率在服从Ps+Ps的情况下,正态分布的微分熵取最大
p(x):E(X2)≤Psmax=21log2πe(Ps+Pz)
两个独立的正态分布,依旧是正态分布
C(Ps)=h∗(Y)−h(Z)=21log2πe(Ps+Pz)−21log2πe(Pz)=21logPzPs+Pz=21log(1+PzPs)
PzPs实际就是:信噪比 =噪声的功率信号的功率
对于无记忆记忆加性噪声信道,若输入信号X具有高斯分布,加性噪声功率为Pn,则当噪声具有高斯分布的时候,输入输出的互信息达到最小
- 高斯噪声其实是对信道噪声最大的噪声,即相同功率下,高斯噪声使得信道容量最小
- 高斯噪声提供最大的微分熵
一般无记忆加性噪声信道的容量
让噪声为任意分布时,无法获得信道容量的解析解,但是我们给出其上界和下界
C(Ps)=p(x)max{I(X;Y):E(X2)=Ps}≥I(XG;Y)≥I(XG;YG)=21log(1+PNPs)
E(X2)h(Y)C(Ps)Pe=Ps,E(Z2)=PN,E(Y2)=Ps+PN=21log(2πe(Ps+PN))≥21log(2πe(Ps+PN))−h(Z)=21log(2πePePs+PN)≜2πe1exp(2h(Z))
并联的加性噪声信道
- 输入:Xn,Ps
- 噪声:Zn,PN
- 在总功率限定的情况下,求信道容量-费用函数
- 信道之间相互独立
C(Ps)=p(X)sup{I(X;Y):n=1∑NPsn=Ps}
graph LR
X-->信道1;
X-->信道2;
X-->信道n;
信道1-->Y;
信道2-->Y;
信道n-->Y;
如何分配每一个加性高斯噪声子信道的功率,使得整体信道的功率之和达到最大值
maxs.t.I(Xn;Yn)=∑21log(1+PNiPsi)i=1∑nPsi=PsPsi≥0,1≤1≤n
利用拉格朗日求解的方法,对每个信道进行下列操作,λ是拉格朗日乘子
∂Psi∂[21log(1+PNiPsi−λ(i=1∑nPsi−Ps))]21PSi+PNiPNi⋅PNi1=λPsi+PNiPsi=0=0for i≤i≤n=2λ1λ=2(Ps+Pn)n=nPs+PN−PNifor i and Psi>0
当Psi小于0,说明噪声太大,信道太糟糕,则弃之不用,再重新计算一次n−1个信道,直到所有信道非负时,则完成
注水功率分配
- 为了达到信道的容量,有些噪声很大的信道需要弃之不用
模拟信道
在时间和取值熵都连续的信道
AWGN:加性白色高斯噪声信道
- 带宽有限:W
- 加性噪声:y(t)=x(t)+z(t)
- 白色噪声:平稳遍历随机过程,功率谱密度均匀分布于整个频域,即功率谱密度(单位带宽噪声功率)为一个常数
- 高斯噪声:平稳遍历随机过程,瞬时值的概率密度函数服从高斯分布
模拟信道容量
- 输入信号:x(t)
- 带宽有限:输入信号带宽限制在[−W,W]内
- 时间有限:T
- 输出信号:y(t)
- 噪声信号:z(t)
- 加性白色高斯噪声
- 零均值
- 两边功率谱密度:N(f)={2N00∣f∣≤W∣f∣>w
- 信道费用:输入信号的功率
莱菲斯特采样定理
信号的正交分解(信息论没有时间概念)
- 由于信道频道首先,信号时长受限,所以,仅需要N=2WT个采样点就可以表示
- 因此信道再时间熵可以被离散化为2WT个点,每个点上取值连续
- 变成了并联2WT个AWGN的连续信道
- 高斯分布独立就等于不相关
- N个信道独立
- 噪声功率:N0/2
并联信道总容量费用函数:
21n=1∑2WTlog(1+PNnPSn)
噪声约束
PNn=2N0⇒PN=NPNn=2WT2N0=WTN0
功率约束:(类似注水功率分配)
PSn=NPsT+PN−PNn=2WTPsT+2WT2N0−2N0=2WPs
香农公式
AWGN信道容量费用函数为
C=Wlog(1+N0WPs)
当输入功率为:Ps,单位时间可以传输的信息量:C
- C:bps
- W:这个带线的信道的带宽,Hz或s−1
- Ps:输入信号的功率,Watt
- N0:带线内,噪声功率谱密度,Watt/Hz
提升容量的各种手段
W→∞limC(Ps)=W→∞limN0Pslog2(1+N0WPs)PsN0W=N0Pslog2e≈1.44NPs
Ps→∞limC(Ps)≈Wln(N0WPs)
- 因此,对于同样的容量的传输要求,可以采用两种方式
- 减小带宽:发送较大功率的信号
- 增大带宽:用较小的功率的信号传输
信息与热力学的关系
定义达到传输容量时,每比特能耗为
Eb=CPs
每比特传输需要的能量与噪声谱密度有关,γ(带线范围内的信噪比)
N0Eb=N0CPs=N0Wlog(1+N0WPs)Ps=log(1+γ)γ
- 信噪比γ趋于0时,上述公式取得极限值0.693称为香农限
- 香农限表示传递1bit信息所需要的最小能量
- 热力学告诉我们N0=kT
- 所以,从物理学角度上看Ebmin=0.693kT
信道编码
对于信道(X,q(y∣x),Y)(输入字幕集,概率转移矩阵,输出字母集)的信道编码包含以下要素
- 输入符号集合:{1,1,⋯,2nR}
- 编码函数xn:{1,1,⋯,2nR}→xn,该函数为每一个输入符号产生了相应的信道编码码字Xn(1),Xn(2),⋯,Xn(m),这些码字构成的集合称为"码本"
- 解码函数g:Yn→{1,1,⋯,2nR},该函数为一个确定性判决函数,它将每一个可能的接受向量映射到一个输入符号
W消息信道编码器Xn信道q(y∣x)Yn信道解码器W^消息的估计
信道编码的码率
(M,n)码的码率R定义为
R=nlogM比特/传输
信道码的每个码字母所能携带的最大信息量
- 通过n次传输
- 每次信道需要承受R个比特的传输
称这样的信道编码为(2nR,n)码,这样的编码的码率为R
信道编码的错误概率
λi=Pr{g(Yn)=i ∣ Xn=xn(i)}=yn∑q(yn∣xn(i))I(g(yn)=i)
其中I(x)为指示函数
- 定义(M,n)码的最大错误概率为
λ(n)=i∈{1,2,⋯,M}maxλi
- 定义(M,n)码的算数平均错误概率为
Pe(n)=M1i=1∑Mλi
- 称一个码率R是可达的,若存在一个信道编码(⌈2nR⌉,n),其最大差错概率在n→∞时趋近0
- 这个R就是这个信道的可达速率
- 可达:无差错的,渐进达到的
信道的操作容量
一个信道的容量时该信道上所有可达码率的上确界,即
C=supR
可达:找到一个信道编解码器对,当n→∞,可以获得码率为R无差错的信道传输方案
重复码
提高抗干扰能力的方法
- 增加功率(提高信噪比)
- 加大带宽(信号变化剧烈)
- 延长时间(降低速率)
最直观的纠错方式就是:重复,增加冗余
误差概率关系
假定信道为二进制对称信道,出错概率为e
W={1,2,⋯,2k}EncoderXnBSC(p)YnDecoderW^
由信息论容量C,在所有互信息上取最大值,得到以下不等式
nCR≥nI(X;Y)≥I(Xn;Yn)≥I(W;W^)=H(W)−H(W∣W^)≥k−kH(Pe)=nk≤1−H(Pe)1−H(P)=1−H(Pe)C
通过变形
Pe=H−1(1−RC)
- 若R>C,Pe严格大于零,代表不可能进行无差错传输,即不可能进行可靠通信
- 若R<C或R=C,Pe可以等于0
- 信源功率:Ps
- 噪声功率:PN
- 对这个信道使用N次,每一次都会从X映射到Y
- 需要求得在Y下最大个数的映射,且不同映射之间的面积不重叠
M=(PN)n(Ps+PN)n=(1+PNPs)2n
这个数值代表我们最大能够实现的信道码率R
R=21log(1+PNPs)
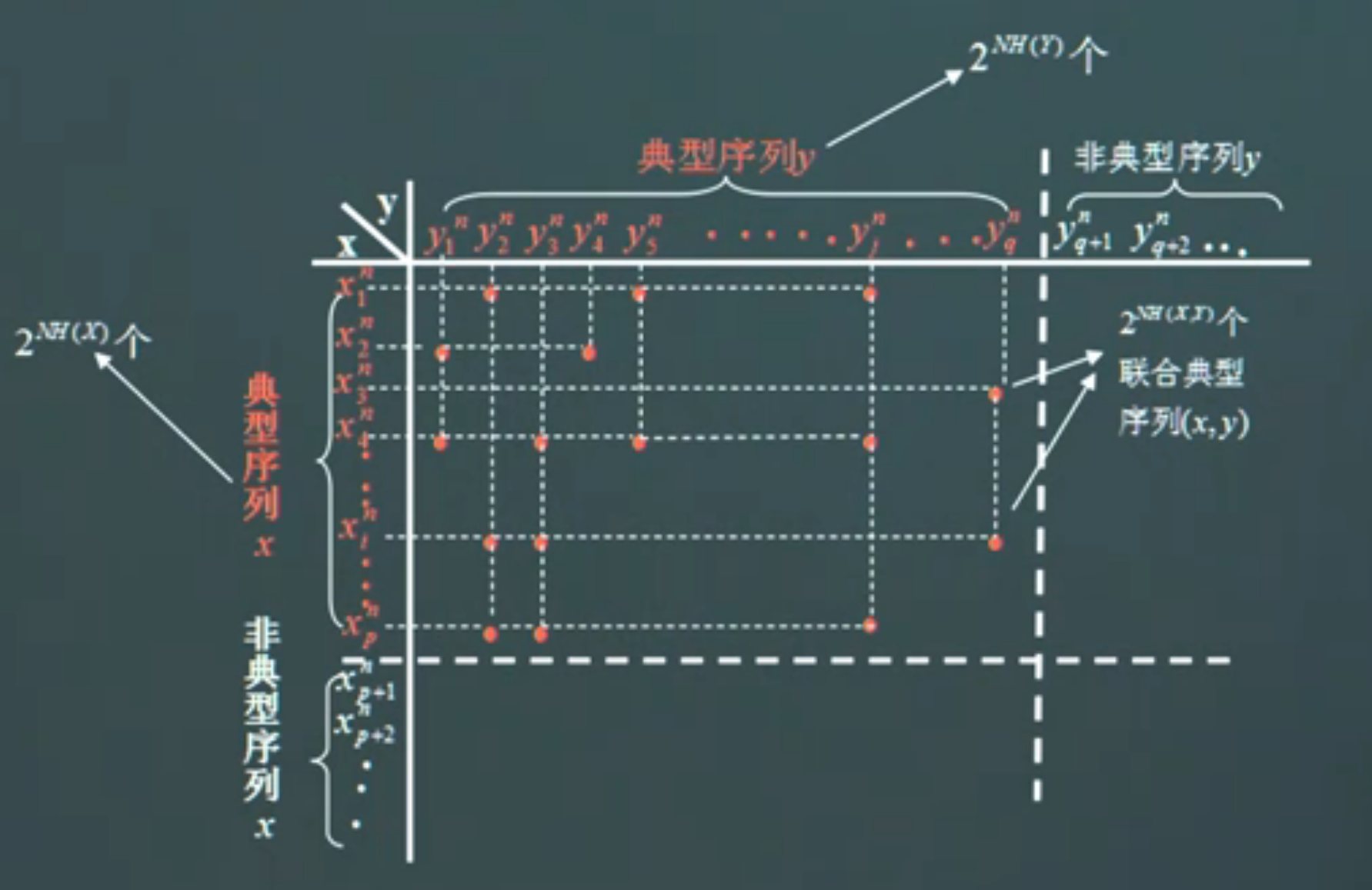
联合典型性
设(Xn,Yn)是长为n的随机序列对,其概率分布满足
p(xn,yn)=i=1∏np(xi,yi)
若(xn,yn)满足以下条件,则称其为联合典型序列
∣−n1logp(xn)−H(X)∣∣−n1logp(yn)−H(Y)∣∣−n1logp(xn,yn)−H(X,Y)∣<ϵ<ϵ<ϵ
联合典型序列构成的集合记为Aε(n)
联合渐进等同分割定理(Joint AEP)
设(Xn,Yn)是长度为n的随机序列对,其分布满足
p(xn,yn)=i=1∏np(xi,yi)
则以下性质成立
- 当n→∞时,Pr((Xn,Yn)∈Aε(n)→1
- (1−ε)2n(H(X,Y)−ε)≤∣Aε(n)∣≤2n(H(X,Y)+ε)
- 设(X~n,Y~n)∼p(xn)p(yn),即X~n,Y~n统计独立且具有与p(xn,yn)一致的边缘分布
- 则Pr((X~n,Y~n)∈Aϵ(n))≤2−n(I(X;Y)−3ϵ)
- 若n足够大,则Pr((X~n,Y~n)∈Aϵ(n))≥(1−ϵ)2−n(I(X;Y)+3ϵ)
设随机变量X~n∼Px(xn),Y~n∼Py(yn)相互独立
Pr((Xn,Yn)∈Aε(n))=(xn,yn)∈Aε(n)∑p(xn)p(xn)≤2n(H(X,Y)+ε)⋅2−n(H(x)−ε)⋅2−n(H(Y)−ε)=2−n(I(X;Y)−3ϵ)
- 联合分布中,大约有2nH(X)个典型X序列和2xH(Y)个典型Y序列
- 其组合共有2nH(X)⋅2nH(Y)=2nH(X)+nH(Y)
- 但是其中联合典型的只有2nH(X,Y)个
- 随机选择而出现联合典型序列的概率为2−nI(X;Y)
- 对于典型输入序列xn,存在大约2nH(Y∣X)个可能的输出,且他们等概
- 所有可能的典型输出序列大约由2nH(Y)个,这些序列被分为若干个不相交的子集
- 子集个数为2n(H(Y)−H(Y∣X))=2nI(X;Y),表示信道可以无误传递的最大字母序列个数
香农第二定理
- 构造阶段
- 假定被信道编码的消息大小为:2nR
- 消息:w∈[1:2nR]
- 由信道编码器,变换为Xn∼Px(x)
- 噪声污染:q(y∣x)
- 输出结果:Yn
- 由信道解码器进行估计:w^
w∈[1:2nR]⟶Xn∼Px(x)q(y∣x)Yn⟶w^
随机编码
- 码字生成的过程是随机的
- 如果需要对2nR个字符进行编码,就要生成2nR个长度为n的信道(进行编码)的输入序列
通过随机生成器,生成
e=⎝⎜⎜⎜⎛xn(1)xn(2)⋮xn(2nR)⎠⎟⎟⎟⎞
其中xn(k)是根据独立同分布的乘积Px(xn(k))=∏i=1nPx(xi(k))生成出来的
这样发送字符k,信道编码器将其查表编码为xn(k),当解码器收到之后,进行判断,其方法为
如果能够找到一个k^,它是唯一能够使得(xn(k^),yn)∈Aε(n)联合典型的话,则k^为传输的符号,反之解码出错
香农第二定理-可达性证明
出错分2种
- P(E1):解码失败
- P(E2):解码重叠
P(E)=P(E1∪E2)=P(E1)+P(E2)≤ε+i=2∑2nT2n(I(X;Y)−3ε)≤ε+23nε2−n(I(X;Y)−R)
要使P(E)趋近于0,则需要I(X;Y)−R≥0,当编码为Xn∼Px∗(x)时,I(X;Y)=C,不等式变为
C−RR≥0≤C
只要上述条件成立
P(E)n→∞0
即我们可以找到一个码率为R的编码,当n→∞时,出错概率≈0
任何一个使得错误概率趋向0的编码方案,其码率R<C
nRnR≤nC=H(W)=H(W∣W^)+I(W;W^)=I(W;W^)≤I(Xn(W);Y)=H(Yn)−H(Yn∣Xn)≤H(Yi)−∑H(Yi∣Xi)=∑I(Xi;Yi)≤nC
Lempel-Ziv编码
也叫做字典式压缩算法,LZ编码,其算法分为2种不同的版本
- LZ77或滑动窗Lempel-Ziv算法
- LZ78或树结构Lempel-Ziv算法
- Lempel-Ziv算法的关键思想时将字符串解析成一个个词组并利用指针替换词组
- 两种算法的区别在于各算法允许的可能匹配位置和匹配长度集合之间的差别
滑动窗Lempel-Ziv算法(LZ77)
树结构Lempel-Ziv算法(LZ78)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| abracadabrarray
a|b|r|ac|ad|ab|ra|rr|ay
(0, a)(0, b)(0, c)(1, c)(1, d)(1, b)(3, a)(3, r)(1, y)
======================================================
1 2 3 4 5 6 7 8 9
0a 0b 0c 1c 1d 1b 3a 3r 1y
======================================================
a = 00
b = 10
c = 10
d = 11
r = 000
y = 001
======================================================
00|0,10|00,10|01,10|001,11|001,10|011,000|0001,001
000100010011000111001100110000001001
|
- 第k=0对的序号一定是0,所以在编码中省略
- 编码(i,x)对时,编码i需要的比特数为⌈log2k⌉,k为第几个
汉明码
参考文献