NoSQL
非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写
MongoDB
MongoDB是一个通用的,基于文档的,基于分布式文件存储的开源数据库系统。
推荐阅读官方文档,这里仅仅是为了方便随时看看整理的而成的
ACID规则
关系型数据库遵循ACID规则
- 原子性(Atomicity):事务里的所有操作要么全部做完,要么都不做,只要有一个操作失败,整个事务就失败,需要回滚
- 一致性(Consistency):数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束
- 独立性(Isolation):并发的事务之间不会互相影响
- 持久性(Durability):一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
CAP定理
指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency):所有节点在同一时间具有相同的数据
- 可用性(Availability):保证每个请求不管成功或者失败都有响应
- 分隔容忍(tolerance):系统中任意信息的丢失或失败不会影响系统的继续运作
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。因此,根据CAP原理将NoSQL数据库分成了三大类
- 满足CA原则:单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大
- 满足CP原则:满足一致性,分区容忍性的系统,通常性能不是特别高
- 满足AP原则:满足可用性,分区容忍性的系统,通常可能对一致性要求低一些
BASE规则
BASE是NoSQL数据库通常对可用性及一致性的弱要求原则:
- Basically Availble:基本可用
- Soft-state:软状态/柔性事务。无连接的
- Eventual Consistency:最终一致性,也是ACID的最终目的
NoSQL 数据库分类
| 类型 | 部分代表 | 特点 |
|---|---|---|
| 列存储 | Hbase,Cassandra,Hypertable | 顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势。 |
| 文档存储 | MongoDB,CouchDB | 文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有机会对某些字段建立索引,实现关系数据库的某些功能。 |
| key-value存储 | Tokyo Cabinet / Tyrant,Berkeley DB,MemcacheDB,Redis | 可以通过key快速查询到其value。一般来说,存储不管value的格式,照单全收。(Redis包含了其他功能) |
| 图存储 | Neo4J,FlockDB | 图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便。 |
| 对象存储 | db4o,Versant | 通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 |
| xml数据库 | Berkeley DB XML,BaseX | 高效的存储XML数据,并支持XML的内部查询语法,比如XQuery,Xpath。 |
MongoDB概念
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | $lookup, 嵌入式文档 |
表连接,MongoDB不支持 |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
| Mysqld/Oracle | mongod | 数据库服务 |
| mysql/sqlplus | mongo | 客户端 |
BSON文档
在MongoDB里一条记录类似于文档,数据结构由键值(key, value)对组成,类似Python里的Dict对象,在值里可以是任何BSON类型和其他文档、数组和文档数组。
- 文档中的键/值对是有序的
- MongoDB区分类型和大小写
- MongoDB的文档不能有重复的键
MongoDB将数据储存为BSON文档,BSON是JSON的二进制表现,而且比JSON包含更多数据类型

1 | { |
BSON文档最大16MB,不能在单个文档中储存持续增持的数据,如:评论
ObjectId
ObjectId很小,且不重复,可以快速生成,且有序的,ObjectId的值为12 bytes
1 | ---------------------------------------------------------------------------------- |
在MongoDB,每一个储存在collection里的文档都需要一个_id作为primary key,如果新插入的文档没有_id,则MongoDB的驱动会自动的生成一个ObjectId给_id赋值
MongoDB的客户端最好提供一个不重复的_id字段,用ObjectId作为_id字段有如下好处
- 在
mongo终端里,可以调用ObjectId.getTimestamp()获取ObjectId的创建时间 - 对
ObjectId排序就等于对创建日期进行排序
虽然ObjectId会随着时间增长,但是它们不一定是单调的
- 只包含秒级的时间分辨力,在同一时间创建的
ObjectId不保证其创建顺序 ObjectId由客户端产生,它们可能有不同的系统时间
BSON键
BSON的键是字符串,文档对于键有以下要求:
_id字段是主键的存在,其值在collection里必须唯一,不可修改- 键不能包含
null字母 - 顶级键不能以
$字母开始- 自从MongoDB 3.6开始,键允许从
.和$符号开始
- 自从MongoDB 3.6开始,键允许从
MongoDB Query语言不能很好的解析有.和$的句子,除非.和$在Query被支持。使用.和$作为键名是不推荐的
BSON类型
BSON是二进制化的一种格式用于储存文档,每一种BSON类型都有数字和字符串的ID
| Type | Number | Alias | Notes |
|---|---|---|---|
| Double | 1 | double |
|
| String | 2 | string |
|
| Object | 3 | object |
|
| Array | 4 | array |
|
| Binary data | 5 | binData |
|
| Undefined | 6 | undefined |
Deprecated. |
| ObjectId | 7 | objectId |
|
| Boolean | 8 | bool |
|
| Date | 9 | date |
|
| Null | 10 | null |
|
| Regular Expression | 11 | regex |
|
| DBPointer | 12 | dbPointer |
Deprecated. |
| JavaScript | 13 | javascript |
|
| Symbol | 14 | symbol |
Deprecated. |
| JavaScript (with scope) | 15 | javascriptWithScope |
Deprecated in MongoDB 4.4. |
| 32-bit integer | 16 | int |
|
| Timestamp | 17 | timestamp |
|
| 64-bit integer | 18 | long |
|
| Decimal128 | 19 | decimal |
New in version 3.4. |
| Min key | -1 | minKey |
|
| Max key | 127 | maxKey |
BSON字符串
BSON字符串都是UTF-8,通常MongoDB的驱动会将来自所有编程语言的字符串在serializing和deserializing的操作时都编码为UTF-8。
BSON Timestamps
BSON有一个特殊的时间戳类型用于MongoDB内部使用,与普通的日期类型不相关。 时间戳值是一个64位的值。其中:
- 前32位是一个
time_t值(与Unix新纪元相差的秒数) - 后32位是在某秒中操作的一个递增的序数
在单个mongod实例中,时间戳值通常是唯一的。
在复制集中,oplog有一个ts字段。这个字段中的值使用BSON时间戳表示了操作时间。
BSON Date
表示当前距离Unix新纪元(1970年1月1日)的毫秒数。日期类型是有符号的,负数表示1970年之前的日期
这样可以表示过去到未来大约290万年的时间
数据库
在MongoDB中,databases是包含文档的一系列collections
- 选择一个数据库:
use myDB - 创建一个数据库
如果数据库不存在,那么MongoDB将会在你第一次储存数据的时候创建数据库
1 | use myNewDB |
如果数据库和collection不存在,insertOne()操作会创建数据库myNewDB和集合myNewCollection1
Collections

MongoDB将文档储存在Collections里
- 创建一个
Collections
若collections不存在,MongoDB会在第一次插入数据的时候创建
1 | db.myNewCollection2.insertOne( { x: 1 } ) |
- 显式创建
可以通过db.createCollection()的方法显式创建collections,前提是如果你需要设定一些参数,例如:最大的大小,或者一些文档的验证规则,如果不需要设置这些,隐式的创建就足够了
Capped collection
Capped collection的长度是有限制的。支持高吞吐量的插入,同时内部文档按照插入顺序排序。类似一个环状缓存。当用完所有长度后,会覆盖最老的文档。
- 默认拥有
_id字段,且_id字段有索引 - 保证插入的顺序,因此不需要管理索引,达到高插入率
- 原子性的移除旧文档
- 插入到capped collection的速度和写入到文件系统的速度几乎一致,且保持顺序
- 可用于缓存少量数据
- 如果需要更新,请加上索引,否则会扫描整个表
- 不能删除单个文档,只能删除整个collection
- 不能使用分片
- 不能对写使用事务,对读可用使用(4.2)
- 必须使用
db.createCollection()显示创建
视图
Mongodb的视图和SQL里的视图没有多大区别,MongoDB并不会将视图里面的数据保存在硬盘里,视图只会在需要使用时,计算出来。MongoDB不支持对视图进行写操作。
1 | db.createCollection( |
- 只能在同一个数据库里创建视图
- 视图创建里的
pipeline不能包含$out或merge - 不能基于视图创建, 删除或重建索引, 也不能获取视图的索引列表
- 不能重命名视图
- 视图会使用索引进行查
物化视图
从4.2版开始,MongoDB为聚合管道(aggregation pipeline)添加了$merge阶段(stage)。此阶段可以将管道结果合并到现有集合中,而不是完全替换该集合。此功能允许用户创建物化视图(on-demand materialized views),在该视图中,每次运行管道时都可以更新输出集合的内容
1 | updateMonthlySales = function(startDate) { |
updateMonthlySales函数定义了monthlybakesales的物化视图包含累积每月销售信息。在该示例中,该函数以日期作为参数,从特定日期开始更新每月销售信息$match阶段仅处理大于或等于startDate的销售数据$group阶段按年份将销售信息分组。此阶段输出的文档具有以下形式{ "_id" : "<YYYY-mm>", "sales_quantity" : <num>, "sales_amount" : <NumberDecimal> }
$merge阶段将输出写入 monthlybakesales集合- 基于在_id字段(默认为没有分片的输出集合),该节点阶段检查聚集结果的文档是否和现有文档想匹配
- 存在匹配项(即集合中已经存在具有相同年份月份的文档),则该阶段将使用汇总结果中的文档替换现有文档
- 没有匹配项,那么阶段会将聚合结果中的文档插入到集合中(不匹配时的默认行为)
- 基于在_id字段(默认为没有分片的输出集合),该节点阶段检查聚集结果的文档是否和现有文档想匹配
$merge阶段- 可以输出到相同或不同数据库的集合中;
- 如果输出集合尚不存在,则创建一个新集合;
- 可以将结果(插入新文档,合并文档,替换文档,保留现有文档,操作失败,使用定制的更新管道处理文档)合并到现有集合中。
- 可以输出到分片集合。输入集合也可以分片
文档验证
默认一个collections不要求其中的文档有一样的格式(schema)。
从version 3.2开始可以添加对文档在插入和更新时的验证,验证的规则时基于每个collections的
JSON Schema
从version 3.6开始,MongoDB支持使用JSON Schema的验证规则,为了使用JSON Schema,需要在验证器中指定$jsonSchema操作符,后增加的验证规则并不会对已经存在的文档生效
1 | db.createCollection("students", { |
推荐使用JSON Schema进行验证的设定
只读视图
MongoDB支持从已经存在的collections和其他视图上创建只读视图。
为了创建一个视图,可以使用以下指令
1 | db.runCommand( { create: <view>, viewOn: <source>, pipeline: <pipeline> } ) |
具体参见官方文档create
索引
索引可以提高queries语句执行的效率,如果没有索引,MongoDB需要执行collections的扫描,并扫描所有在collection里的文档来匹配满足query语句的文档。如果拥有适当的索引,MongoDB可以利用索引来限制需要扫描的文档数。
索引是一种特殊的数据结构(B树),它以易于遍历的形式存储部分集合数据集。索引存储特定字段或字段集的值,按字段值排序。索引条目的排序支持高效的等值匹配和基于范围的查询操作。此外,MongoDB可以使用索引中的顺序返回排序后结果。

MongoDB的所有类似其他数据库的索引,索引定义在collections级别之上,支持所有字段和子字段。
创建索引
1 | db.collection.createIndex( <key and index type specification>, <options> ) |
- 升序:
1 - 降序:
-1
索引的分类
- 复合索引
MongoDB支持用户在多个字段上定义索引,即复合索引。
复合索引中字段的顺序很重要。例如,如果复合索引为{ userid: 1, score: -1 },则索引首先以userid字段进行排序,然后在每个userid值以score字段进行排序。
- 多键索引
MongoDB使用多键索引来索引存储在数组中的内容。如果索引字段包含数组值,MongoDB会为数组的每个元素创建单独的索引条目。这些多键索引允许查询通过匹配数组中的元素来获取包含数组的文档。如果索引字段包含数组值,MongoDB会自动决定是否需要创建多键索引; 不需要显式指定多键类型。
- 地理空间索引
为了支持对地理空间坐标数据的高效查询,MongoDB提供了两个特殊索引:返回结果时使用平面几何的2d索引和使用球面几何的2dphere索引。
- 文本索引
MongoDB提供了一种text索引类型,支持在集合中搜索字符串内容。这些文本索引不存储特定于语言的停用词(例如“the”,“a”,“or”),并且集合中的词干均仅存储词根。用于提供文本搜索功能,一个collection只能拥有一个搜索文本索引(此索引可跨多个字段)
- 哈希索引
为了支持基于哈希的分片,MongoDB提供了哈希索引类型,索引字段值的哈希值。这些索引在其范围内具有更随机的值分布,但仅支持等值匹配且不支持范围查询。
索引的属性
- Unique Indexes
索引的唯一属性会导致MongoDB拒绝索引字段的重复值。除了唯一约束之外,唯一索引在功能上可与其他MongoDB索引互换。
- Partial Indexes
部分索引仅索引符合特定的过滤表达式的集合中的文档。通过索引集合中的文档子集,部分索引具有较低的存储要求,减少索引创建和维护的性能成本
- Sparse Indexes
索引的稀疏属性可确保索引仅包含具有索引字段的文档的条目。索引会跳过没有索引字段的文档。
将稀疏索引与唯一索引组合,以拒绝具有字段重复值的文档,但忽略没有索引键的文档。
- TTL Indexes
TTL索引是MongoDB在指定时间后自动从集合中删除文档的特殊索引。这是某些类型的信息理想选择,例如机器生成的事件数据,日志和会话信息,这些信息只需要在数据库中保存有限的时间。
索引问题
- 每个索引至少需要数据空间为8kb
- 添加索引会对写入操作会产生一些性能影响
- 索引对于具有高读取率的集合Collections很有利
- 索引处于action状态时,每个索引都会占用磁盘空间和内存
索引限制
- 索引名称长度不能超过128字段
- 复合索引不能超过32个属性
- 每个集合Collection不能超过64个索引
- 不同类型索引还具有各自的限制条件
mongo终端
mongo终端是JavaScript对MongoDB的一个交互的接口,可以使用mongo对数据库进行操作
- 默认链接:
mongo(如果本地运行且为默认端口27017) - 设置端口:
mongo --port 27017 - 远程链接:
mongo "mongodb://mongodb0.example.com:27017"mongo --host mongodb0.example.com:27017mongo --host mongodb0.example.com --port 27017
- 身份验证
mongo "mongodb://[email protected]:27017/?authSource=admin"mongo --username alice --password --authenticationDatabase admin --host mongodb0.examples.com --port 27017
mongo终端指令
- 列出数据库:
db - 根据权限列出数据库:
show dbs - 切换数据库:
use <database>- 从其他数据库切换数据库:
db.getSiblingDB()
- 从其他数据库切换数据库:
- 删除数据库:
db.dropDatabase()
- 创建
collections:db.createCollection(name, options) - 获取
collections:db.getCollection() - 删除
collections:db.COLLECTION_NAME.drop() - 列出
collections:show collections或show tables - 插入数据
MongoDB CRUD操作
- 对单个文档的写操作都是原子级别的
创建操作
- 插入文档:
db.COLLECTION_NAME.insert(document) - 插入单条文档:
db.COLLECTION_NAME.insertOne(document) - 插入多条文档:
db.COLLECTION_NAME.insertMany(document,[document...])

搜索操作
- 查找:
db.COLLECTION_NAME.find() - 查找全部:
db.COLLECTION_NAME.find({}) - 过滤:
db.COLLECTION_NAME.find({ <field1>: <value1>, ... })db.COLLECTION_NAME.find({ <field1>: { <operator1>: <value1> }, ... })
- 限制数量:
db.COLLECTION_NAME.find().limit(NUMBER) - 跳过数量:
db.COLLECTION_NAME.find().skip(NUMBER) - 排序:
- 升序:
db.COLLECTION_NAME.find().sort({KEY:1}) - 降序:
db.COLLECTION_NAME.find().sort({KEY:-1})
- 升序:

搜索操作符
| 选择操作符 | 说明 |
|---|---|
$eq |
等于 |
$gt |
大于 |
$gte |
大于等于 |
$in |
数组包含 |
$lt |
小于 |
$lte |
小于等于 |
$ne |
不等于 |
$nin |
不包含 |
| 逻辑操作符 | 说明 |
|---|---|
$and |
与 条件查询 |
$not |
查询与表达式不匹配的文档 |
$nor |
查询与任一表达式都不匹配的文档 |
$or |
或 条件查询 |
| 元素操作符 | 说明 |
|---|---|
$exists |
查询存在指定字段的文档 |
$type |
查询指定字段类型的文档 |
| 评估操作符 | 说明 |
|---|---|
$expr |
允许在query里使用聚合表达式 |
$jsonSchema |
通过jsonSchema进行过滤 |
$mod |
取余条件查询 |
$regex |
正则表达式查询 |
$text |
文本索引查询 |
$where |
使用JavaScript 表达式匹配 |
| 数组操作符 | 说明 |
|---|---|
$all |
匹配文档的数组字段中包含所有指定元素的文档 |
$elemMatch |
匹配内嵌文档或数组中的部分field |
$size |
匹配数组长度为指定大小的文档 |
| 比特操作符 | 说明 |
|---|---|
$bitsAllClear |
匹配数字或者比特全部都是0 |
$bitsAllSet |
匹配数字或者比特全部都是1 |
$bitsAnyClear |
匹配数字或者比特含有0 |
$bitsAnySet |
匹配数字或者比特含有1 |
| 投影操作符 | 说明 |
|---|---|
$ |
查询数组中首个匹配条件的元素,相当于findOne()方法 |
$elemMatch |
用于数组或内嵌文档中的元素匹配(子元素匹配),只会返回匹配的第一个元素 |
$meta |
Projects the document’s score assigned during $text operation. |
$slice |
在查询中将数组进行切片(类似于分页) |
更新操作
- 更新:
db.collection.update(<filter>, <update>, <options>) - 更新一个:
db.collection.updateOne(<filter>, <update>, <options>) - 更新多个:
db.collection.updateMany(<filter>, <update>, <options>) - 替换一个:
db.collection.replaceOne(<filter>, <update>, <options>)

更新操作符
| 更新操作符 | 说明 |
|---|---|
$inc |
将文档中的某个field对应的value自增/减某个数字amount |
$mul |
将文档中的某个field对于的value做乘法操作 |
$rename |
重命名文档中的指定字段的名 |
$setOnInsert |
配合upsert操作,在作为insert时可以为新文档扩展更多的field |
$set |
更新文档中的某一个字段,而不是全部替换 |
$unset |
删除文档中的指定字段,若字段不存在则不操作 |
$min |
将文档中的某字段与指定值作比较,如果原值小于指定值,则不更新;若大于指定值,则更新 |
$max |
与$min功能相反 |
$currentDate |
设置指定字段为当前时间 |
| 数组更新操作符 | 说明 |
|---|---|
$addToSet |
用于添加一个元素到array中,一般用于update |
$pop |
删除数组中的第一个或最后一个元素,-1表示第一个,1表示最后一个 |
$pullAll |
删除数组或内嵌文档字段中所有指定的元素 |
$pull |
删除满足条件的元素 |
$pushAll |
自v2.4开始,方法弃用,请使用each来配合实现 |
$push |
往数组中追加指定的元素,若文档中数组不存在,则创建并添加指定元素,自v2.4起,添加了对$each的支持 |
$each |
需要搭配$addToSet或$push方可使用 |
$sort |
自v2.4加,配合$push使用,表示给文档中的指定数组元素排序,1是升序,-1是降序 |
$positon |
自v2.6加,配合$push使用表示往数组元素中的指定位置插入元素 |
删除操作
- 删除:
db.collection.remove() - 删除一个:
db.collection.deleteOne(<filter>, <options>) - 删除多个:
db.collection.deleteMany(<filter>, <options>)

聚合操作
聚合操作能够将来自多个document的value组合在一起,并通过对分组数据进行各种操作处理,并返回计算后的数据结果
- 聚合管道(aggregation pipeline)
- Map-Reduce函数
- 单一的聚合命令(count、distinct、group)
聚合管道
聚合管道是由aggregation framework将文档进入一个由多个阶段(stage)组成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理,输出相应的聚合结果。
1 | db.orders.aggregate([ |
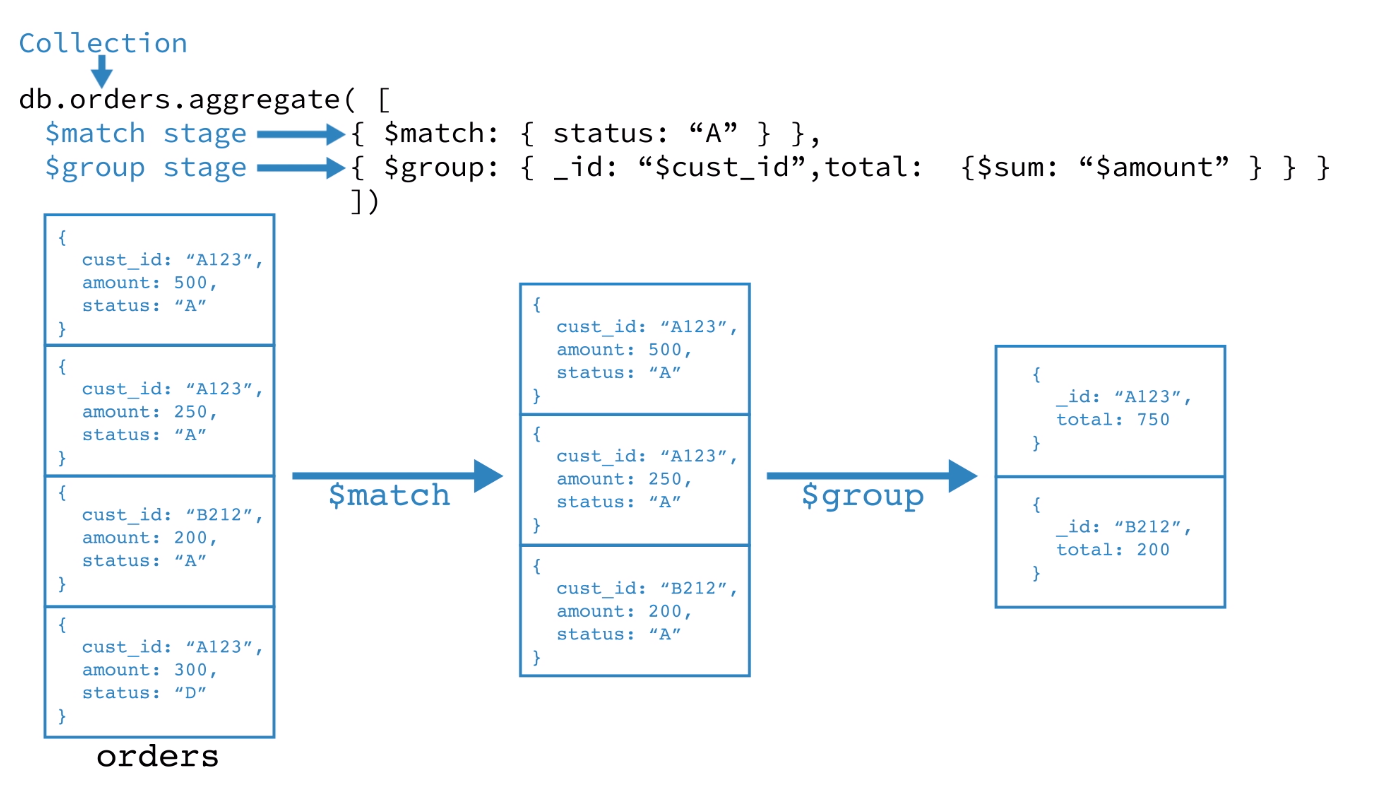
- 第一阶段:
$match通过status过滤文档,将过滤的文档给第二阶段 - 第二阶段:
$group使用cust_id来将文档分组,然后计算每个组amount之和
管道
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
最基本的管道功能提供过滤器filter,其操作类似于查询和文档转换,可以修改输出文档的形式。
其他管道操作提供了按特定字段或字段对文档进行分组和排序的工具,以及用于聚合数组内容(包括文档数组)的工具。 此外,管道阶段可以使用运算符执行任务,例如计算平均值或连接字符串。总结如下:
- 管道操作符
| 常用管道 | 解析 |
|---|---|
$group |
将collection中的document分组,可用于统计结果 |
$match |
过滤数据,只输出符合结果的文档 |
$project |
修改输入文档的结构(例如重命名,增加、删除字段,创建结算结果等) |
$sort |
将结果进行排序后输出 |
$limit |
限制管道输出的结果个数 |
$skip |
跳过制定数量的结果,并且返回剩下的结果 |
$unwind |
将数组类型的字段进行拆分 |
- 表达式操作符
| 常用表达式 | 含义 |
|---|---|
$sum |
计算总和 |
$avg |
求平均值 |
$min |
求min值 |
$max |
求max值 |
$push |
将结果文档中插入值到一个数组中 |
$first |
根据文档的排序获取第一个文档数据 |
$last |
同理,获取最后一个数据 |
Map-Reduce函数
map-reduce操作有两个阶段
- map阶段:处理每个文档并为每个输入文档发出一个或多个对象
- reduce阶段:组合map操作的输出
map-reduce使用自定义JavaScript函数来进行map和reduce操作
1 | db.orders.mapReduce(map, reduce, {query, output}) |

单一的聚合命令
单一的聚合命令。提供了对常见聚合过程的简单访问操作,但缺乏聚合管道和map-reduce的灵活性和功能
db.collection.estimatedDocumentCount():计数,但只能告诉您集合中的文档总数db.collection.countDocuments():计数,可以进行过滤计数db.collection.count():计数(已弃用)db.collection.distinct():字段去重
读取偏好
readPreference主要控制客户端Driver从复制集的哪个节点读取数据,这个特性可方便的实现读写分离、就近读取等策略。
primary:只从Primary节点读数据,这个是默认设置primaryPreferred:优先从Primary读取,Primary不可服务,从Secondary读secondary:只从Scondary节点读数据secondaryPreferred:优先从Secondary读取,没有Secondary成员时,从Primary读取nearest:根据网络距离就近读取
使用场景
- 用户下单后马上跳转到订单详情页:
primary/primaryPerferred,因为此时从节点可能还没复制到新的订单数据 - 用户查询自己下过的订单:
secondary/secondaryPerferred,查询历史订单对时效性通常没有太高要求 - 生成报表:
secondary,报表对时效性要求不高,但资源需求大,可以在从节点单独处理,避免影响主节点操作 - 将用户上传的图片分发到全世界,让各地用户就近读取:
nearest,每个地区的应用选择最近的节点读取数据
- 指定
readPerference时也应该注意高可用问题。例如将readPerference指定primary,则发生故障转移不存在primary期间将没有节点可读。如果业务允许,则应选择primaryPerference
读取策略
| 事务属性 | 支持程度 |
|---|---|
| Atomocity 原子性 | 单表单文档:1.x就支持,复制集多表多行:4.0复制集,分片集群多表多行:4.2 |
| Consistency 一致性 | writeConcern、readConcern(3.2) |
| Isolation 隔离性 | readConcern(3.2) |
| Durability 持久性 | Journal and Replication |
在读取数据的过程中我们需要关注以下问题
- 从哪里读?关注数据节点的位置(由readPerference解决)
- 什么样的数据可以读?关注数据的隔离性(由readConcern解决)
readConcern的初衷在于解决脏读的问题,readConcern决定这个节点上的数据哪些是可读的
用户从MongoDB的Primary上读取了某一条数据,但这条数据并没有同步到大多数节点,然后Primary就故障了,重新恢复后这个Primary节点会将未同步到大多数节点的数据回滚掉,导致用户读到了脏数据
local:返回的数据不能保证在大多数复制集承认available:- 非shard:和
local一样 - shard:在chunk迁移的过程中,mongod实例异常宕机,导致迁移过程失败或者部分完成,会产生孤儿文件,而available可能会返回孤儿文件查询,
- 非shard:和
majority:返回的数据能保证在大多数复制集都承认,即使发生过失败- 能保证用户读到的数据『已经写入到大多数节点』,并不能保证读到的数据是最新的
linearizable:和majority类似。和majority最大差别是保证绝对的操作线性顺序(在写操作自然时间后面发生的读,一定可以读到之前的写),但是更耗性能,更慢- 只对读取单个文档时有效
snapshot:- 如果事务不是因果一致的会话的一部分,则在使用写策略"majority"提交事务时,事务的操作将确保从多数提交的数据快照中读取数据。
- 如果事务是因果一致的会话的一部分,则在在使用读策略"majority"提交事务时,则可以保证事务操作从多数提交数据的快照中读取数据,该快照提供了与紧接事务开始之前的操作的因果一致性。
- 只在多文档事务中生效。
- 保证没有脏读,不可重复读,幻读
无论何种级别的 readConcern,客户端都只会从『某一个确定的节点』(具体是哪个节点由 readPreference 决定)读取数据,该节点根据自己看到的同步状态视图,只会返回已经同步到大多数节点的数据。
写操作到达大多数节点之前都是不安全的,一旦主节点崩溃,而从节点还没复制到该次操作,刚才的写操作就丢失了
如果在一次写操作到达大多数节点前读取了这个写操作,然后因为系统故障该操作回滚了,则发生脏读问题,使用{readConcern:"majority"}可以有效避免脏读
available与迁移
在复制集中local和available是没有区别的,两者的区别主要体现在分片集上,有以下场景:
- 一个chunk x正在从shard1向shard2迁移
- 整个迁移过程中chunk x 中的部分数据会在shard1和shard2中同时存在,但源分片shard1仍然是chunk x的负责方
- 所有对chunk x的读操作仍然进入shard1
- config中记录的信息chunk x仍然属于shard1
此时如果读shard2,则会体现出local和available的区别
local:只取应该由shard2负责的数据(不包括x)available:shard2上有什么就读什么(包括x)
写入策略
默认情况下,Primary完成写操作即返回。写入策略(Write Concern)有多种级别。
writeConcern决定一个写操作落到多少个节点上才算成功,这决定了MongoDB是否成功写入数据。
写入策略是指当客户端发起写入请求后,数据库什么时候给应答,mongodb有三种处理策略:客户端发出去的时候,服务器收到请求的时候,服务器写入磁盘的时候
写入策略包含以下策略
1 | { w: <value>, j: <boolean>, wtimeout: <number> } |
w:数据写入到number个节点才向用客户端确认{w: 0}对客户端的写入不需要发送任何确认,适用于性能要求高,但不关注正确性的场景{w: 1}默认的writeConcern,数据写入到Primary就向客户端发送确认{w: "majority"}数据写入到副本集大多数成员后向客户端发送确认,适用于对数据安全性要求比较高的场景,该选项会降低写入性能
j: 写入操作的journal持久化后才向客户端确认wtimeout: 写入超时时间,仅w的值大于1时有效。- 数据需要成功写入number个节点才算成功,如果写入过程中有节点故障,可能导致这个条件一直不能满足,从而一直不能向客户端发送确认结果,针对这种情况,客户端可设置wtimeout选项来指定超时时间,当写入过程持续超过该时间仍未结束,则认为写入失败。
{w: 0} |
{w: "majority"} |
{w: "all"} |
{j: "true"} |
|---|---|---|---|
 |
 |
 |
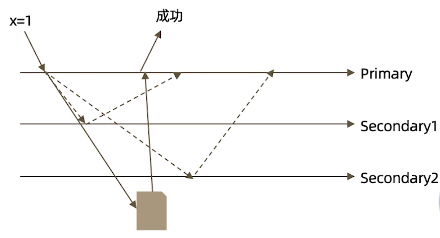 |
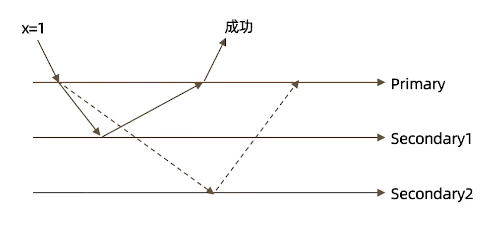
如果复制集是3台机器,写入两台机器,流程如下

- 虽然多半数的 writeConcern都是安全的,但通常只会设置 majority,因为这是等待写入延迟时间最短的选择
- 不要设置 writeConcern 等于总节点数,因为一旦有一个节点故障,所有写操作都会失败
- writeConcern 虽然会增加写操作的延迟时间,但并不会显著增加集群的压力,因此无论是否等待,写操作最终都会复制到所有节点上。但设置 writeConcern只是让写操作等待复制后在返回而已
- 应对重要数据(订单、金融有关的)应用 {w:“majority”},普通数据(日志)可以应用{w:1}以确保最佳性能
复制集
复制集(Replication)由一组Mongod实例(进程)组成,包含一个Primary节点和多个Secondary节点,提供冗余和高可用性。复制集的成员有
- 一个Primary节点:接受所有写操作
- 多个Secondary节点:保持和Primary节点一样的数据集。
Mongodb Driver(客户端)的所有数据都写入Primary,Secondary从Primary同步写入的数据,以保持复制集内所有成员存储相同的数据集,提供数据的高可用。
一组复制集就是一组mongod实例掌管同一个数据集,实例可以在不同的机器上面
复制集推荐最低成员数量是3个:一个Primary节点,二个Secondary节点。在某些情况,每个复制集还有一个仲裁者,仲裁者不存储数据,只是负责通过心跳包来确认集群中集合的数量,并在主服务器选举的时候作为仲裁决定结果。
一个复制集可以包含50个成员,但是只能有7个可投票成员
复制集成员
Primary节点
Primary节点是整个复制集里唯一一个接受写操作的成员。MongoDB在Primary节点上实行写操作,并记录操作到Primary节点的oplog里。Secondary节点会复制这个log,从中复现操作到自己的数据集里

复制集里所有的成员都可以接受读操作。但是默认上,一个应用会直接对Primary节点进行读操作。
一个复制集只能拥有一个Primary节点,如果Primary节点变为不可用,则会进行选举决定新的Primary节点

Secondary节点
Secondary节点包含Primary节点的所有的数据集。Secondary节点从Primary节点的oplog里异步获取操作来同步数据。一个复制集可以有多个Secondary节点

客户端不能对Secondary节点写数据,但是可以从Secondary节点读数据。
如果Primary节点变得不可用了,则Secondary节点会进行选举来决定Primary节点。我们可以对Secondary节点进行一些配置
- 阻止它成为Primary节点,从而使之成为一个冷备份。设置其优先度为0
- 组织应用从它这里读取数据,从而使之与普通流量分离
- 用于紧急备份或从一些错误中进行复原,比如:删库
仲裁者
仲裁者(Arbiter)不复制数据,也不会成为Primary节点,但仲裁者会参与选举,Primary节点有一点投票额度。

尽可能在副本集中使用奇数个数据成员,而不要使用仲裁者。
优先级0复制集成员
优先级为0的成员不能成为主节点,也不能触发选举。优先级0的成员可以确认w的写操作。对于“多数”写关心,优先0成员也必须是一个投票成员(即members[n].votes大于0)以确认写入。非投票副本集成员(即members[n].votes为0)不能帮助确认具有“多数”写关心的写操作。
除了上述限制之外,优先级为0的次要设备作为普通次要设备运行:它们维护数据集的副本,接受读取操作,并在选举中投票。将辅助节点配置为优先级为0以防止它成为主节点,这在多数据中心部署中特别有用。
例如,在下图中,一个数据中心承载主和次要成员。 第二个数据中心托管优先级为0的次要数据库。只有数据中心1中的成员才能成为主数据库。

优先级为0的辅助设备可以用作备用设备。 在某些副本集中,可能无法在合理的时间内添加新成员。 备用成员保留数据的当前副本以便能够替换不可用的成员。
在许多情况下,您无需将备用数据库设置为优先级0。但是,在具有不同硬件或地理分布的副本集中,优先级为0的备用数据库可确保仅某些成员成为主数据库。
对于具有不同硬件或工作负载配置文件的集合中的某些成员,优先级0待机也可能是有价值的。 在这些情况下,请部署优先级为0的成员,以使其不能成为主要成员。 另外考虑使用隐藏成员来实现此目的。
如果集合中已有七个投票成员,则还要将该成员配置为非投票。
隐藏副本集成员
隐藏成员维护主数据集的副本,但对客户端应用程序不可见。 隐藏成员适用于具有与副本集中其他成员不同的使用模式的工作负载。 隐藏成员必须始终优先为0成员,因此不能成为主要成员。db.isMaster()方法不显示隐藏的成员。 然而,隐藏的成员可能会在选举中投票。

读操作:客户端不会将具有适当读取首选项的读分发给隐藏成员。 因此,除基本复制外,这些成员不会收到任何流量。使用隐藏成员执行报告和备份等专用任务。延迟成员应当被隐藏。
在分片群集中,mongos不与隐藏成员交互。
隐藏的成员可以在副本集选举中投票。如果你停止了一个隐藏成员进行投票请确保primary有足够活跃的优先度,以免被罢职。
隐藏副本集成员可参与写入策略的确认,前提是它是投票成员
延迟副本集成员
延迟副本集成员包含复制集里指定的数据的复制。延迟副本集成员有一个早期的,或者说是延迟了的复制集的副本。通俗的讲就是过去某个时间点的数据快照,比如现在时间是09:52,然后有一个成员延迟了1个小时,延迟成员没有任何多余08:52的操作记录。
延迟成员可用于数据恢复

- 优先级:必须设置为0,防止成为Primary节点
- 应该设置为隐藏节点
- 可以作为投票节点
- 可以参与写入策略
在分片中,在负载均衡器启用的时候,延迟成员只有有限的作用。因为在延时的时间段内进行过数据段迁移的话,复制集中的延时节点就无法为还原分片集群提供有效的帮助。
复制集Oplog
Oplog是用于存储MongoDB数据库所有数据的操作记录的,是一个capped collection(固定长度的collection)
Oplog的存在极大地方便了MongoDB副本集的各节点的数据同步,MongoDB的主节点接收请求操作,然后在Oplog中记录操作,次节点异步地复制并应用这些操作。
| Storage Engine | Default Oplog Size | Lower Bound | Upper Bound |
|---|---|---|---|
| In-Memory Storage Engine | 5% of physical memory | 50 MB | 50 GB |
| WiredTiger Storage Engine | 5% of free disk space | 990 MB | 50 GB |
| MMAPv1 Storage Engine | 5% of free disk space | 990 MB | 50 GB |
但是我们系统中如果存在以下操作的话,那么我们就可能需要设置更大的 Oplog 值来避免数据的丢失
- 一次更新多个文件
- 删除与插入同样数量的数据
- 大量地更新现有的数据
oplog中每个操作都是幂等性,无论是对目标数据库应用一次还是多次,oplog操作都会产生相同的结果
复制集数据同步
初始同步
初始同步(Initial Sync)会将完整的数据集复制到各个节点上。当一个节点没有数据的时候,就会进行初始同步,比如,当它是新加的节点,或者它的数据已经无法通过复制追上最新的数据了,也会进行初始同步。
当你进行一次初始同步,MongoDB会
- 克隆除本地以外所有的数据库,mongod会扫描每一个源数据库的所有collection,然后把所有数据都插入到这些表的备份中。同时也会建立索引
- 从源的oplog中,恢复所有改动到数据集,mongod会将自己的数据更新到和当前复制集一样的状态
如果在初始同步的时候出错,则Secondary节点会重新执行初始复制。从MongoDB 4.4版本起,能够进行恢复的尝试
初始同步资源选举
initialSyncSourceReadPreferenceprimary:选择primary节点作为同步节点,不可用则间隔定时重试primaryPreferred:选择primary节点作为同步节点,不可用则选择其他可用节点- 其他模式:选择成员里其他节点
初始同步会执行下面2个选择进行同步源选择,若First Pass不通过,则执行Second Pass,还不通过重启选择流程
- Sync Source Selection (First Pass)
- Sync Source Selection (Second Pass)
Replication
在初始同步之后,Secondary节点继续复制数据,它会从源那里复制oplog来异步的同步数据。Secondary节点可能会基于ping等因素改变源。
流Replication
从MongoDB 4.4开始,从源复制数据会以oplog的流的形式同步到Secondary节点。在高负载和高延迟的网络里不好用。
- 减少无效的读
- 减少因为
w: >1的写操作丢失
多进程Replication
使用多进程复制来改善并发度
复制集选举
选举决定谁是Primary节点,当发生以下事件的时候,复制集会发生选举
- 增加一个新节点到复制集
- 初始化一个复制集
- 使用
rs.stepDown()或rs.reconfig() - Secondary节点们和Primary节点连接超时
复制集在选举结束之前不能执行写操作。一个集群选举Primary节点不能超过12秒(默认配置),这个时间包括标记Primary不可用和整个选举流程。这个时间可以修改以防止因为网络原因加长选举时间的而导致失败。具体取决于你的架构
心跳包
复制集成员会相互之间间隔2秒发送心跳包。如果超过10s没有回复,则其他成员标识这个成员不可访问
成员优先度
当复制集有一个稳定的Primary节点后,选举算法会做一个“best-effort”的尝试来优先级最高的Secondary节点有选举的权限。成员优先度影响选举的步骤和结果。优先度越高的成员会比优先度更低的成员更早的发起选举,同时更可能的获胜。但是,低优先度的成员同意可能被短时间选举成为Primary节点,即使其他更高优先级节点可用,此时复制集会继续玄机,直到高优先度成员成为Primary
- 每个节点都倾向于投票给优先级最高的节点
- 优先级为0的节点不会主动发起Primary选举
- 当Primary发现有优先级更高Secondary,并且该Secondary的数据落后在10s内,则Primary会主动降级,让优先级更高的Secondary有成为Primary的机会。
拥有最新optime(最近一条oplog的时间戳)的节点才能被选为Primary。
MongoDB分片
分片是将数据水平切分到不同的物理节点的方法。当应用数据越来越大的时候,数据量也会越来越大。当数据量增长时,单台机器有可能无法存储数据或可接受的读取写入吞吐量。当工作集的大小大于系统内存大小的时候,对磁盘的I/O就会有很大的压力。利用分片技术可以添加更多的机器来应对数据量增加以及读写操作的要求。
- sharding:分片
- shard:单个mongod实例或复制集,保存了一部分分片集群的数据
- shard key:分片键
- sharded data:分片数据
- sharded cluster:分片集群
MongoDB分片几乎能自动完成所有事情,只要告诉MongoDB要分配数据,它就能自动维护数据在不同服务器之间的均衡。
- 一个shard包含集群里的分片数据的一个子集。集群分片包含所有数据。
- 分片必须被部署为一个复制集来保证冗余性和高可用性。
- 用户,客户端,应用只能直接连接到一个分片执行本地的管理和维护操作
- 在单个shard上执行查询只会返回本地的数据,通过mongos才能执行集群级别的操作
分片集群
一个MongoDB的分片集群包含以下组件
- shard:每个shard包含分片数据的一个子集。每个shard都可以部署为一个复制集(replica set)
- mongos:mongos作为一个查询路由器,给客户端应用和分片集群之间提供一个接口,所有操作均通过mongos执行
- 一个读写操作,mongos需要知道应该将其路由到哪个复制集上,mongos通过将片键空间划分为若干个区间,计算出一个操作的片键的所属区间对应的复制集来实现路由。
- config servers:配置服务器储存metadata和一些集群的配置文件
- 配置服务器至少由3个MongoDB实例组成的集群
- 提供metadata的增删改查,和Etcd功能相似
在collection级别上的分片数据,将会在整个分片集群里分布式储存
 |
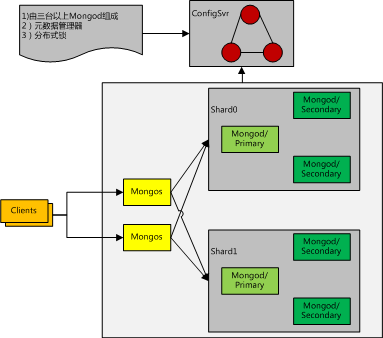 |
mongodb集群是一个典型的去中心化分布式集群。Mongos本身并不持久化数据,Sharded cluster所有的元数据都会存储到Config Server,而用户的数据会分散存储到各个shard。Mongos启动后,会从配置服务器加载元数据,开始提供服务,将用户的请求正确路由到对应的碎片。
- 元数据的一致性与高可用
- 业务数据的多备份容灾
- 动态自动分片
- 动态自动数据均衡
Primary Shard
每一个在分片集群里数据库都有一个Primary Shard,保存着所有没有被分片的数据。每个数据库都有自己的Primary Shard。Primary Shard和Primary复制集没有任何关系
在创建新的数据库的时候,mongos会在集群里选在一个拥有最少数据的shard成为Primary Shard。

Config Servers
配置服务器储存metadata和一些集群的配置文件。metadata反映了集群里所有数据和组件的状态和组织。metadata还包含了在每个shard的chunks的列表,和定义那些chunks的范围。
mongos实例们将缓存这些数据然后用于路由读和写的操作到正确的shard上。在集群有变化的时候,mongos会更新缓存,比如chunk splits或新增一个shard,shard也从配置服务器会读取chunk的metadata
- 配置服务器同意储存认证信息,比如RBAC或一些集群的内部验证配置
- MongoDB同时使用配置服务器来管理分布式锁
- 每个分区集群必须有自己的配置服务器集群,不要对不同分片集群使用同一个配置服务器集群。
mongos
MongoDB的mongos实例帮助查询和写操作路由到集群里正确的分片上,mongos是操作和查询集群的唯一入口。应用程序不应该直接连接到分片上进行操作
mongos通过config server缓存的metadata来追迹数据在哪个分片上。同样使用这些缓存的数据来路由操作到mongod实例上,mongos没有一个不变的状态,而且消耗很小的系统的资源
mongos本身属于轻量级的服务
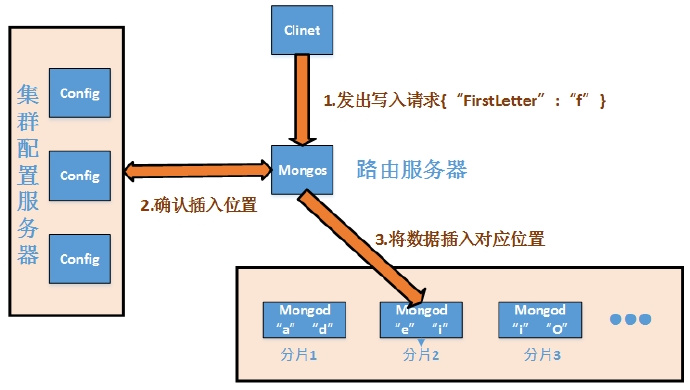
路由和结果处理
mongos实例通过下面的操作路由查询到集群
- 决定哪些分片必须收到查询请求
- 在所有目标分布上使用游标
mongos会把目标分布上的所有数据都结合起来,然后返回结果。有些操作比如:排序,会在每个分片上执行,而不是在mongos拿到所有数据后执行
有2种情况的pipeline是不适合在mongos上运行的
- 第一种情况是:当需要合并的部分,包含一个必须在Primary分片节点执行的步骤,比如
$lookup要求同一数据库种非分片collection时候,这样的合成需要在Primary分片节点上运行 - 第二种情况是:当合成部分其中一个步骤需要在磁盘上写入一些临时数据时候,比如:
$group,并且客户端指定了allowDiskUse:true。在这样的情况,假设其他步骤不需要Primary分片节点。那么merge操作将会随机地选择一个分片节点。
Sorting:Limit:mongos会传递limit参数,同时从分片获取数据后会再使用一次limit后再返回数据skips:mongos不会传递skips参数,而是全部获取,然后再执行skip
单节点操作 vs 广播操作
通常,在分片中最快的操作是在单个分片上能够执行的操作,mongos用分片键可以准确的从配置服务器的metadata里面找到对应的分片。而对于不包含分片键的操作,mongos需要查询所有分片,等待所有回复然后返回结果,所以scatter/gatter的查询会运行很长时间
- 广播操作:mongos实例会广播操作到所有分片节点上,除非它已经可以决定哪个分片或分片子集储存了需要的数据。
- 单节点操作:mongos通过分片键找到对应
chunk然后执行操作
| 广播操作 | 单节点操作 |
|---|---|
| sharded-cluster-scatter-gather-query.bakedsvg.svg | sharded-cluster-targeted-query.bakedsvg.svg |
比如,如果分片键是:{ a: 1, b: 1, c: 1 },则可单节点操作的分片键为以下
{ a: 1, b: 1, c: 1 }{ a: 1, b: 1 }{ a: 1 }
分片键
分片键必须是一个索引字段或几个一起复合索引字段,用来决定如何文档将储存在哪个节点上
特别的,MongoDB将分片键切割为多个不互相重叠的几段,每一段都和一个chunk联合起来,然后MongoDB尝试将这个chunk平均地分配到分片集群中。

- 使用
chunk来存储数据 - 进群搭建完成之后,默认开启一个
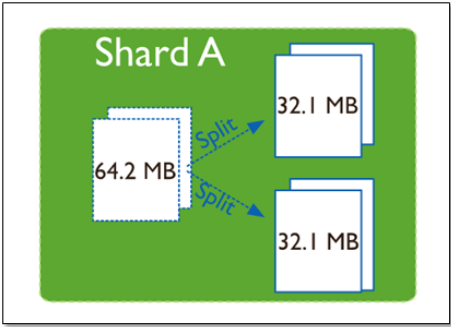
chunk,大小是64M - 存储需求超过64M,
chunk会进行分裂,如果单位时间存储需求很大,设置更大的chunk chunk会被自动均衡迁移
chunk代表shard server内部一部分数据
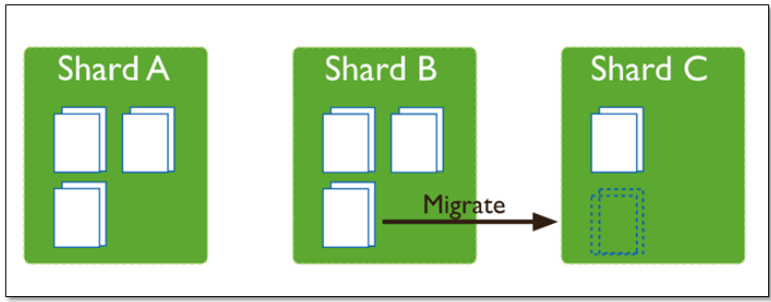
Splitting:当一个chunk的大小超过配置中的chunk size时,MongoDB的后台进程会把这个chunk切分成更小的chunk,从而避免chunk过大的情况Balancing:在MongoDB中,balancer是一个后台进程,负责chunk的迁移,从而均衡各个shard server的负载,系统初始1个chunk,chunk size默认值64M,生产库上选择适合业务的chunk size是最好的。MongoDB会自动拆分和迁移chunks。
| Splitting | Balancing |
|---|---|
 |
 |
chunk的分裂和迁移非常消耗IO资源;chunk分裂的时机:在插入和更新,读数据不会分裂
分片键的创建
在对collection进行分片时,必须指定分片键
1 | sh.shardCollection(<namespace>, <key>) |
- namespace: i.e.
<database>.<collection> - key:
{ <shard key field1>: <1|"hashed">, ... }
对于分片键的选择将影响分片集群的性能,效率和可扩展性。还可能成为性能瓶颈
At minimum, consider the consequences of the cardinality, frequency, and monotonicity of a potential shard key.
- Cardinality:基数,也就是chunk的最多数量,如果cardinality过小,则能够有的chunk就会很少,比如分片键(字段)的值只有2种情况,就只有2个chunk
- Frequency:频率尽量越平均越好,不然数据会集中储存再某个
chunk里 - Monotonicity:单调性,分片键最好不要是单调的,不然会集中路由到最大或最小分片键的那个
chunk
理想的分片键允许MongoDB在整个集群中均匀地分布所有文档。
| Cardinality | Frequency | Monotonicity |
|---|---|---|
| sharded-cluster-ranged-distribution-low-cardinal.bakedsvg.svg | sharded-cluster-ranged-distribution-frequency.bakedsvg.svg | sharded-cluster-monotonic-distribution.bakedsvg.svg |
分片键索引
所有被分片的collection都必须有一个支持分片键的索引。这个索引必须是在分片键上或者是一个分片键为首的复合索引
- 如果collection为空,且分片键的索引不存在,
sh.shardCollection()将会创建一个分片键的索引 - 如果collection不为空,必须创建一个索引才能使用
sh.shardCollection()
改变分片键值
- 你必须再mongos上执行,不要再分片节点上执行
- 你必须通过事务或者可重写操作执行
- 你必须加上一个能过完全过滤出分片键的等于条件。
{ activityid: 1, userid : 1 } -> activityid: <value>, userid: <value>
哈希分片
哈希分片使用哈希索引在被分片群集中分区数据。 哈希索引计算单个字段的哈希值或者多个字段哈希作为索引值; 此值用作分片键

哈希分片在分片群集中提供更均匀的数据分布,但代价是减少了单目标操作。后散列,值相近的分片键的文档不太可能在同一块或分片上 - mongos更有可能执行广播操作以满足给定的范围查询。mongos可以将具有相等匹配的查询定位到单个分片。
哈希分片可以更好的把分片键均匀的分布输出
Ranged Sharding
Ranged Sharding更倾向把值相近的分片键分配在一起,这对一定范围的内的查询很有效率,但是也有可能因为分片键的选择不加而降低效率
- Large Shard Key Cardinality:大基数
- Low Shard Key Frequency:平均的频率
- Non-Shard Key Monotonicity:非单调性的
分配集群均衡器
均衡器是一个监视着每个分片上有多少chunk的后台进程。当一个分片上的shard数量达到一个阈值时,均衡器会尝试自动地在分片之间迁移chunk从而使每个分片的chunk数量相同。为了解决分片集合的不均匀区块分布问题,平衡器将块从具有更多区块的分片迁移到具有较少区块数的分片。平衡器迁移区块,直到在分片上为集合均衡分布。
- 只有当
chunk数量差异达到迁移阈值时,才启动操作。 - 在任何给定时间最多将分片限制为最多一个迁移,一次迁移一个
chunk

- 均衡器是默认开启的
chunk迁移可能会带来一些性能问题或过载(I/O 100%)- 考虑到数据迁移会降低系统性能,可以配置均衡器在只在特定时间段运行
- 比如夜里系统负载比较小的时候
孤儿文档
以下是对迁移过程描述:
- balancer向源shard发送moveChunk命令;
- 源shard内部执行moveChunk命令,并保证在迁移的过程中,新插入的document还是写入源shard;
- 如果需要的话,目标shard创建需要的索引;
- 目标shard从源shard请求数据;注意,这里是一个copy操作,而不是move操作;
- 在接收完
chunk的最后一个文档后,目标shard启动一个同步拷贝进程,保证拷贝到在迁移过程中又写入源shard上的相关文档; - 完全同步之后,目标shard向config server报告新的metadata(
chunk的新位置信息); - 在上一步完成之后,源shard开始删除旧的document。
如果能保证以上操作的原子性,在任何步骤出问题应该都没问题;如果不能保证,那么在第4,5,6,7步出现机器宕机,都有可能出问题。
先将shard1节点的chunk拷贝到shard2节点去,当chunk完全拷贝完成后,再将shard1节点的chunk删了。
解决方法:找出不属于config节点记录的数据标识范围,并将其删除。
1 | var nextKey = { }; |
建立模型
- 考虑字段
- 引用 vs 嵌入
Mongodb优势
- 面向集合(Collection)和文档(document)的存储,以JSON格式的文档保存数据
- 适合互联网应用
- 不需要转化/映射应用对象到数据库对象
- 高效的传统存储方式:支持二进制数据及大型对象
- 高可用性,数据复制集,MongoDB 数据库支持服务器之间的数据复制来提供自动故障转移
- 架构简单
- 没有复杂的连接
- 深度查询能力
Mysql区别
| 形式 | MongoDB | MySQL |
|---|---|---|
| 数据库模型 | 非关系型 | 关系型 |
| 存储方式 | 虚拟内存+持久化 | |
| 查询语句 | 独特的MongoDB查询方式 | SQL语句 |
| 架构特点 | 副本集,分片 | 单点、M-S、MHA、MMM等架构 |
| 数据处理方式 | 基于内存,将热数据存在物理内存中 | 根据引擎不同而不同 |
| 使用场景 | 日志,数据大且非结构化数据的场景 | 数据量少且很多结构化数据 |
传统SQL数据库从标准范式的数据开始,但是因为业务发展,数据库的表可能变得复杂,从而性能下降