随机样本
总体:实验的全部可能的观察值
个体:每一个可能观察值
容量:中体中所包含的分体的个数
有限总体:容量为有限
无限总体:容量为无限
这里主要是探讨样本与总体的区别和联系等等
|
总体 |
样本 |
样本观察值 |
| 期望 |
μ |
X |
x |
| 方差 |
σ2 |
S2 |
s2 |
- 所谓从总体抽取一个个体,就是对总体X进行一次观察并记录其结果
- 在相同的条件下对总体X进行n次重复的独立的观察,则n的结果记为X1,X2,⋯,Xn,它们相互独立
- 它们都是与X具有相同分布的随机变量,一组这样的数据称为来自总体X的一个简单随机样本
定义:设X是具有分布函数F的随机变量,若
X1,X2,⋯,Xn
是具有同一分布函数F的,相互独立的随机变量,则称X1,X2,⋯,Xn为从分布函数F(或总体F,或总体X)得到的容量为n的简单随机样本,简称样本,他们的观察值
x1,x2,⋯,xn
称为样本值,又称为X的n个独立的观察值
抽样方法
- 简单随机抽样
- 分层抽样:按比例分层,各层取样合并
- 整群抽样:分集合,在群里取全部的样
- 多阶段抽样:先抽几组,再在其中之一继续抽几组,以此循环到最后的单体样本
- 系统抽样:标号,间隔取样
实验方法
- 随机对照实验
- 将研究对象随机分组,对不同组实施不同的干预,在这种严格的条件下对照效果的不同
- 在研究对象数量足够的情况下,这种方法可以抵消已知和未知的混杂因素对各组的影响
- ===========
- 完全随机设计
- 是用随机化的方式来控制误差变异,认为经过随机化处理后,样本间的变异在各个处理水平上随机分布,这样就可将实验结果的差异归于不同处理的影响
- 这种设计假设通过随机化能平衡被试间的差异,但实际上在实验结果当中常常会包括个体差异。如果我们可以将这些个体差异排除,实验结果才会更加精确
- 随机区组设计
- 通常是将受试对象(样本)按性质相同或相近者分成若干组,每个组中的受试对象分别随机分配到不同的处理组中去
- 做到区组内尽量同质,使得实验结果的差异更好地归于不同处理的影响
- 分层随机法
- 简易的区组随机法是面向所有受试对象进行分组,只能保证将受试对象按照总体样本大小分成两组
- 分组随机法可以实现平衡两组受试对象的生理特征
- 交叉研究
- 将研究对象分为2组,对A组进行X实验,对B组进行Y实验,然后过一定期间,交换实验方法再进行一次
- 观察研究
- 横向研究
- 队列研究(纵向研究)
- 病例对照研究
- 选出一组病例,和对照组,调查这个病的特性,如:比较患某病群体与正常人的DNS的变异程度
Fisher试验设计三原则
- 重复:评价偶然误差的大小
- 分区组:将一部分系统误差通过分组的区别去除
- 随机化:将其他意料之外的系统误差转换为偶然误差
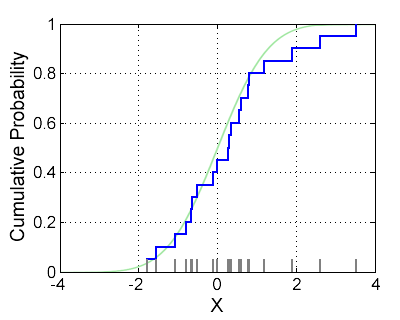
经验分布函数
又称样本分布函数,可以将其看作,以等概率1/n取值X1,X2,⋯,Xn的离散型随机变量的分布函数
- 该函数的图形呈现跳跃式台阶形折现
- 如果观测值不重复,则每一跳跃为1/n
- 如果观测值重复,则每一跳跃为1/n的倍数

Fn(x)=n1S(x)=n1i=1∑n1xi≤t
对于经验分布函数Fn(x),有以下结论:对于∀x,n→∞时,Fn(n)以概率1一致收敛于分布函数F(x),即
P(n→∞lim−∞<x<∞sup∣Fn(x)−F(x)∣=0)=1
当n充分大的时候,经验分布函数的任一个观察值Fn(x)与总体分布函数F(x)只有微小的差别
抽样分布
定义:设
X1,X2,⋯,Xn
是来自总体X的一个样本,
g(X1,X2,⋯,Xn)
是X1,X2,⋯,Xn的函数,若g中不含未知参数,则称g(X1,X2,⋯,Xn)是一统计量(统计量指的是样本的函数,比如一个可以算期望值的函数E(X)),因为X1,X2,⋯,Xn都是随机变量,所以统计量也是一个随机变量,设
x1,x2,⋯,xn
是相对于样本X1,X2,⋯,Xn的样本值,则
g(x1,x2,⋯,xn)
是g(X1,X2,⋯,Xn)的观察值(也就是带入函数的实际的参数)
| 名称 |
统计量 |
观察值 |
| 样本平均值 |
X=n1∑i=1nXi |
x=n1∑i=1nxi |
| 样本方差 |
S2=n−11∑i=1n(Xi−X)2 |
s2=n−11∑i=1n(xi−x)2 |
| 样品标准差 |
S=S2 |
s=s2 |
| 样本k阶原点矩 |
Ak=n1∑i=1nXikk=1,2,⋯ |
ak=n1∑i=1nxikk=1,2,⋯ |
| 样本k阶中心距 |
Bk=n1∑i=1n(Xi−X)kk=2,3,⋯ |
bk=n1∑i=1n(xi−x)kk=2,3,⋯ |
统计量的分布称为抽样分布,在使用统计量机性统计推断的时候需要知道它的分布,当总体的分布函数已知时,抽样分布时确定的,打赏要求出统计量的精确分布,一般是很困难的,所以我们采用一些常用的统计量分布进行估计。
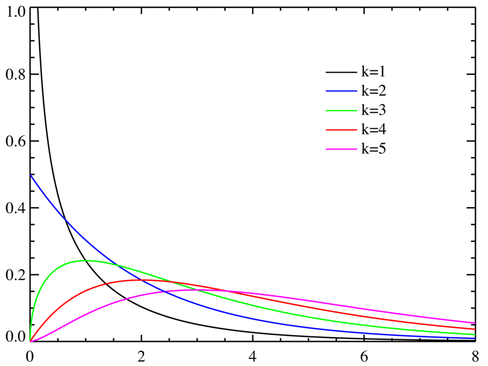
χ2分布(卡方分布)
设X1,X2,⋯,Xn是来自总体N(0,1)的样本,则称统计量
χ2=X12+X22+⋯+Xn2
服从自由度为n的χ2分布,记为χ2∼χ2(n),其中自由度为右端包含的独立变量的个数
χ2分布概率密度函数
f(y)={2n/2Γ(n/2)1yn/2−1e−y/20y>0其他
χ2分布累积分布函数
Fk(x)=2kγ(2k,2x)
χ2分布的性质
- 可加性:设χ12∼χ2(n1),χ22∼χ2(n2),并且χ12,χ22相互独立,则χ12+χ22∼χ2(n1+n2)
χ2分布的数学期望和方差
E(χ2)D(χ2)=n=2n
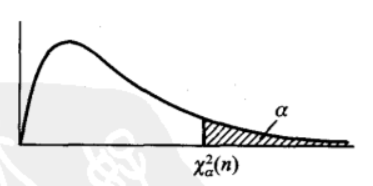
χ2分布的分位点
对于给定的正数a,称满足条件
P(χ2>χa2(n))=∫χa2(n)∞f(y)dy=aa∈(0,1)
的点χa2(n)为χ2(n)分布的上a分位点
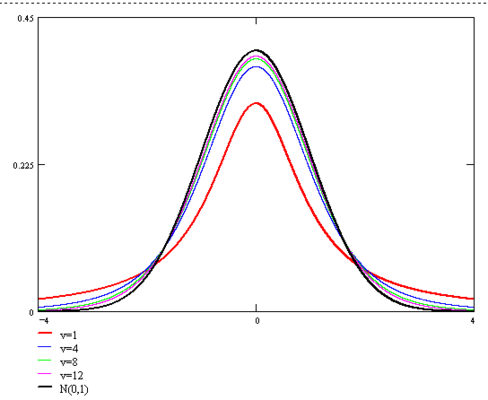
t分布
设X∼N(0,1),Y∼χ2(n),且X,Y相互独立,则称随机变量
t=Y/nX
服从自由度为n的t分布,记为t∼t(n)
t分布概率密度函数
h(t)=πnΓ(n/2)Γ[(n+1)/2](1+nt2)−(n+1/2)−∞<t<∞
- 关于t=0对称
- 当n充分大的时候类似于标准正态变量概率密度的图形
n→∞limh(t)=2π1e−t2/2
t分布累积分布函数
Fk(x)=21+πnΓ(n/2)xΓ((n+1)/2)2F1(21,(n+1)/2;23;−nx2)
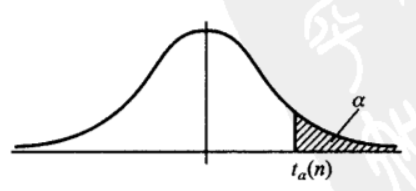
t分布的分位点
对于给定的正数a,称满足条件
P(t>ta(n))=∫ta(n)∞h(t)dt=a,a∈(0,1)
的点ta(n)为t(n)分布的上a分位点
由t分布上a分位点的定义及h(t)图形的对称性知
t1−a(n)=−ta(n)
F分布
设U∼χ2(n1),V∼χ2(n2),且U,V相互独立,则称随机变量
F=V/n2U/n1
服从自由度为(n1,n2)的F分布,记为F∼F(n1,n2)
F分布概率密度函数
ψ(y)={Γ(n1/2)Γ(n2/2)[1+(n1y/n2)](n1+n2)/2Γ[(n1+n2)/2](n1/n2)n1/2yn1/2−1,0,y>0其他
由定义可知,若F∼F(n1,n2),则
F1∼F(n2,n1)
F分布的分位点
对于给定的a∈(0,1),满足条件
P(F>Fa(n1,n2))=∫Fa(n1,n2)∞ψ(y)dy=a
的点Fa(n1,n2)为F(n1,n2)分布上的上a分位点
F分布是上a分位点有如下的重要性质
F1−a(n1,n2)=Fa(n2,n1)1
正态总体的样本均值与样本方差的分布
设总体(不管服从什么分布,只要均值和方差存在)的均值为μ,方差为σ2,X1,X2,⋯,Xn是来自X的一个样本,X,S2分别是样本均值和样本方差,则
E(X)=μ,D(X)=σ2/nE(S2)=σ2
定理一:设X1,X2,⋯,Xn是来自正态总体N(μ,σ2)的一个样本,X是样本均值,则有
X∼N(μ,σ2/n)
定理二:设X1,X2,⋯,Xn是来自正态总体N(μ,σ2)的一个样本,X,S2是样本均值和样本方差,则有
- σ2(n−1)S2∼χ2(n−1)
- X与S2相互独立
定理三:设X1,X2,⋯,Xn是来自正态总体N(μ,σ2)的一个样本,X,S2是样本均值和样本方差,则有
S/nX−μ∼t(n−1)
及自由度为n−1的t分布
定理四:设X1,X2,⋯,Xn与Y1,Y2,⋯,Yn是来自正态总体N(μ1,σ12)和N(μ2,σ22)的样本,它们相互独立,X1,S12和X2,S22分别是样本均值和样本方差,则有
- σ12/σ22S12/S22∼F(n1−1,n2−1)
- 当σ12=σ12=σ时
Swx11+n21(X−Y)−(μ1−μ2)∼t(n1+n2−2)
其中
Sw2=n1+n2−2(n1−1)S12+(n2−1)S22,Sw=Sw2
总结
|
公式 |
| 样本均值,方差已知 |
X∼N(μ,σ2/n) |
| 含有样本方差 |
σ2(n−1)S2∼χ2(n−1) |
| 含有样本均值 |
S/nX−μ∼t(n−1) |
| 2个样本 |
σ12/σ22S12/S22∼F(n1−1,n2−1) |
这里的分布主要供接下来的置信区间,假设检验使用
分布的特点:
- t分布:对称性
- F分布:F1−a(n1,n2)=Fa(n1,n2)1