
容器的管理
graph LR
传统部署时代 --> 虚拟化部署时代 --> 容器部署时代
当我们运行普通的云服务器,我们可以通过他们的IP和端口进行关联,但是当多台服务器里面的服务都容器化后,他们的关联会变得非常复杂,所以我们需要一个资源管理器一样的东西。
- 服务发现与负载均衡
- 容器自动装箱
- 存储编排
- 自动容器恢复
- 自动发布与回滚
- 配置与密文管理
- 批量执行
- 水平伸缩
K8s Overview
如果你使用过Docker,应该可以发现Docker是在一台机器上将资源进行虚拟化,如果你使用纯Docker会发现配置起来非常麻烦,需要输入大量的指令,而且可能会忘记自己做过什么,而且不好同时管理多个容器,于是就有了docker-compose,通过它,我们就可以通过配置文件进行配置。
那么K8s简单来说就是在许多太机器上将资源进行虚拟化,可以看作虚拟成一台一台服务器(Pod),虽说虚拟化了,但是毕竟底层是实体机器,所以需要有对每一台Node的配置,就像docker-compose一样,如果没有docker-compose你只靠Docker一样是可以使用的,但是单靠docker-compose也是可以使用的,同时更方便,那么K8s就相当于多台机器的docker-compose。
至于为什么多了那么多概念,单台机器不需要考虑什么这个容器放哪的问题,而多台就需要,而且多台机器的IP也不同,也不可能单纯的绑定路径添加Volume,而且多台机器扩容什么的,网络管理什么的,Pods之间交互,启动顺序。对应的,你在docker-compose可以配置volume,network什么的,你在k8s上也可以,同时是集群级别的。这就是为什么会多那么多东西。
K8s麻烦的地方在于,对于整体概念难以像Docker一下清晰掌握,同时大量的配置文件难以区分,而且个人或者小公司基本上对集群没有需求,这里我们不对K8s进行详细的讲解,你可以看过一遍K8s后,在这里进行一遍查询。
要想着本质是程序员写的东西,不可能往复杂方向写,在能重用的地方肯定重用,基本不会有不同的规格(配置文件)
K8s整体架构

Docker操作的对象是容器,K8s操作是cluster集群
K8s组件
- client
- kubectl
- master
- kube-api-server
- controller-manager
- replication-controller
- namespace-controller
- service-controller
- node-controller
- service-account-controller
- endpoint-controller
- resource-quota-controller
- token-controller
- kube-scheduler
- etcd-cluster
- worker
- kubelet
- kube-proxy
- container-runtime-engine
K8s通过controller进行实质的操作,通过etcd储存cluster的所有信息
K8s核心概念
- Pods
- Static Pods
- Multi-Container Pods
- Init-Container
- ReplicaSets
- DaemonSets
- StatefulSets
- Service
- ClusterIP
- NodePort
- LoadBalancer
- ExternalName
- Label
- Label Selectors
- Deployment
- Namespaces
- Taints
- Tolerations
- Node Affinity
- Resource Limits
- Rolling Updates
- Rollbacks
- Commands and Arguments
- Configure
- Env Variables
- ConfigMap
- Secrets
- Maintenance
- OS upgrade
- Cluster Upgrade
- Kubectl Upgrade
- Backup and Restore
- Security
- Authentication
- TLS
- Certificate Creation
- Certificate API
- KubeConfig
- API Group
- Authorization
- Role Based Access Controls
- Cluster Roles
- Image Security
- Security Context
- Network Policies
- Storage
- Container Storage Interface
- Volumes
- Persistent Volumes
- Persistent Volumes Claims
- Storage Class
- Networking
- Network Namespace
- Container Network Interface
- Cluster Network
- Pod Network
- Service Network
- CNI weave
- ipam weave
- DNS
- CoreDNS
- Ingress
总的来看可以分为
- Pods
- ReplicaSets
- Service
- Deployment
- Namespaces
- Label
- 机器管理
- 更新备份
- 安全
- 维护
- 储存
- 网络
实际上就是在之前物理机的基础上进行虚拟化,将实体资源虚拟化,然后就需要自己对这全部的虚拟化资源进行管理,如果要像实体机那样随自己配置,就需要这么多东西
K8s流程
graph TD
Ingress --> Service --> Deployment --> ReplicaSets --> Pods --> Container
对于Docker我们很容易理解,我们需要一个应用,放在容器里运行,需要储存就给他volume,需要访问就给他绑定端口,需要它出错重启就always,需要开启多个就给他scale。
那么在K8s上,其实也是一样的流程,但是K8s的基础对象是Pods,其实可以吧Pods理解为一台机器,所以在这台机器(Pods)的容器(Host network类型)可以直接互相访问,因为我们虚拟化了资源,我们可以有任意台机器,我们创建了许多Pods,但是我们需要保证Pods的数量位置在一定数量,不多不少,这个时候就使用ReplicaSets

Deployment和ReplicaSets功能上基本相似,在Deployment里可以设置ReplicaSets,同时增加了
- Pod Rolling Update
- 更新的历史记录
- Rollback
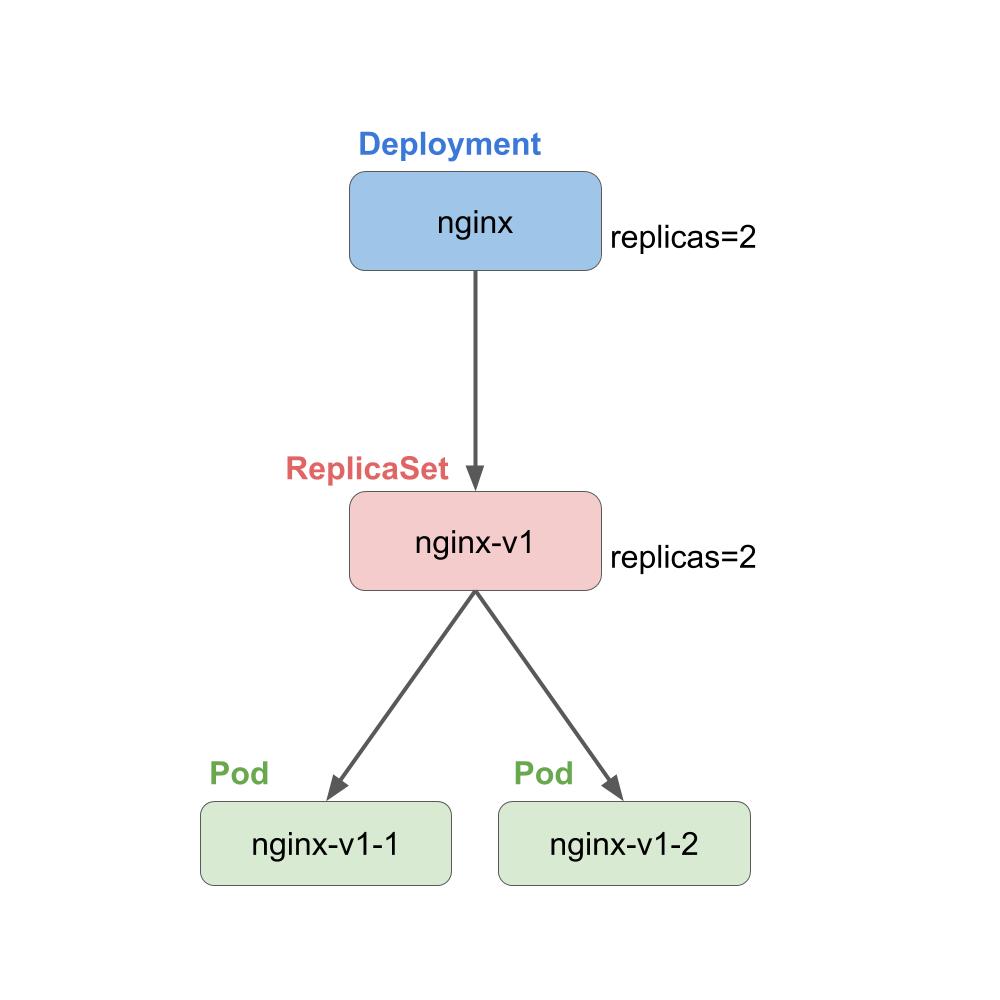
既然基本的部署都运行好了,就需要让他可以访问,因为是多台机器,单纯的绑定端口什么的是不好用的,需要在集群层次上考虑。Deployment里面基本上部署的是一类东西,所以对于一个Deployment,我们需要一个集群层次的IP,也就是Service里面ClusterIP
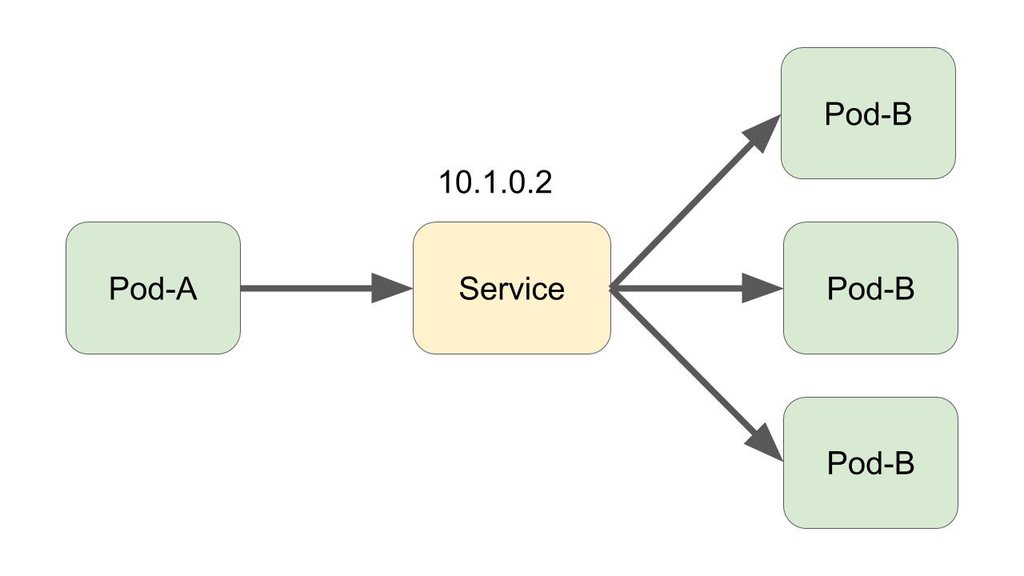
ClusterIP只是集群层次的IP,也就是集群内可以通过他访问一个Deployment(你想问访问哪一个?负载均衡随机一个幸运的Pod),也就是只能内部访问,这时候NodePort就来了,需要注意的是,NodePort是在所有Node上都开一个端口,这个端口会访问到刚刚Service里面ClusterIP。

既然所有Node都开了一个Port,我们访问哪一个呢,这个的确不好解决,怎么个不好解决,这可以说不属于K8s的范围了,所以我们的解决方法是加一个代理服务器,负载均衡到每一个NodePort上(这在云服务上基本上是帮忙实现了的,也就是为什么K8s是云的解决方案)
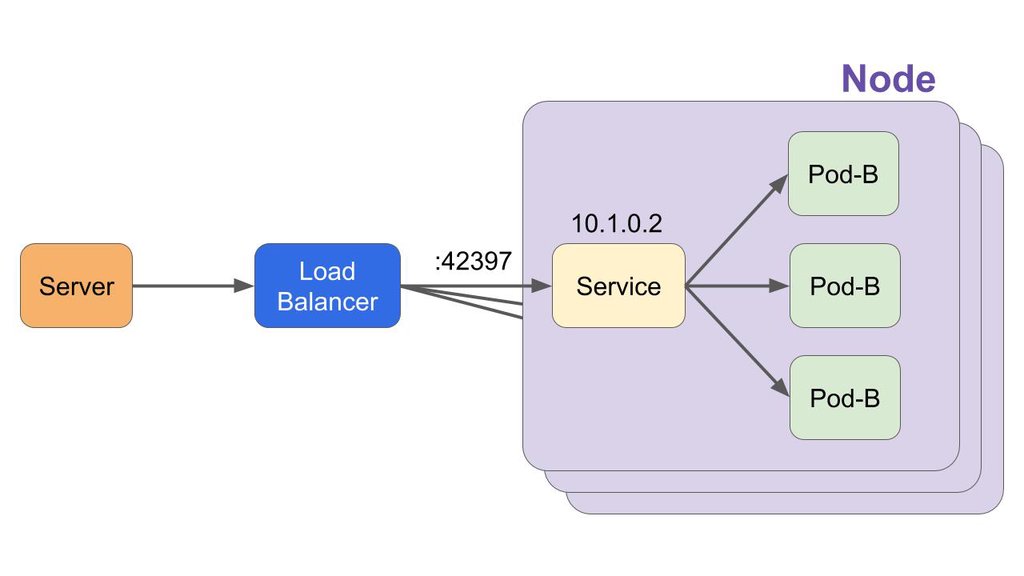
好了,现在可以访问到了,还忘了什么呢?对,加https,这个可以在很多地方加,在应用程序里面加,在代理服务器环境加啥的,麻烦不?肯定麻烦,更别说你可能不只一个网站在这个集群里,那么就需要解决方案,Ingress就来干这事了。Ingress差不多是替代NodePort,他是一个在集群层次上,Services的负载均衡,然后加上https
以上就差不多是部署一个服务的全部流程,细节部分肯定省略了,所以相对Docker,K8s就需要设置更多的东西,但是本质流程是一样的。
开放接口
- CRI(Container Runtime Interface):容器运行时接口,提供计算资源
- CNI(Container Network Interface):容器网络接口,提供网络资源
- CSI(Container Storage Interface):容器存储接口,提供存储资源
组件
配置文件
可能有人会说kubectl不是还有那么多指令吗,docker也有那么多指令,但是我们最后都变为了什么?docker-compose up -d,对,遵循
Infrasturcture as Code
最好的方法就是把一切都变为配置文件,至于指令需要的时候再用。K8s里面配置文件都是这样的格式
应该只使用一种技术来管理 Kubernetes 对象。混合和匹配技术作用在同一对象上将导致未定义行为。
1 | apiVersion: |
在想要创建的 Kubernetes 对象对应的 .yaml 文件中,需要配置如下的字段:
- apiVersion: 创建该对象所使用的 Kubernetes API 的版本
- kind: 想要创建的对象的类别
- metadata: 帮助唯一性标识对象的一些数据,包括一个 name 字符串、UID 和可选的 namespace
对象 spec 的精确格式对每个 Kubernetes 对象来说是不同的,包含了特定于该对象的嵌套字段
Kubernetes API 参考能够帮助我们找到任何我们想创建的对象的 spec 格式。当创建 Kubernetes 对象时,必须提供对象的 spec,用来描述该对象的期望状态
Pod
Pod是kubernetes中你可以创建和部署的最小也是最简的单位。Pod代表着集群中运行的进程。
- 一个 Pod 中运行一个容器
- 在一个 Pod 中同时运行多个容器
每个 Pod 都会被分配一个唯一的IP地址。可以为一个Pod指定多个共享的Volume。Pod中的所有容器都可以访问共享的Volume。Volume也可以用来持久化Pod中的存储资源,以防容器重启后文件丢失。
1 | apiVersion: v1 |
Pod生命周期
Pod的status字段是一个PodStatus对象,PodStatus中有一个phase字段。
phase- 挂起(Pending)
- 运行中(Running)
- 成功(Succeeded)
- 失败(Failed)
- 未知(Unknown)

Pod有一个PodStatus对象,其中包含一个PodCondition数组。PodCondition数组的每个元素都有一个type字段和一个status字段。
type- PodScheduled
- Ready
- Initialized
- Unschedulable
- ContainersReady
status- True
- False
- Unknown
Pod业务类型
- 长期伺服型(long-running)
- Deployment
- 批处理型(batch)
- Job
- 节点后台支撑型(node-daemon)
- DaemonSet
- 有状态应用型(stateful application)
- StatefulSet
Container
我们对于一个容器,那可以干的事情就多了,什么卷,什么环境变量,什么指令,那么就有以下的东西
1 | apiVersion: v1 |
容器状态
- Waiting
- Running
- Terminated
initContainer
-
Init 容器总是运行到成功完成为止。
-
每个 Init 容器都必须在下一个 Init 容器启动之前成功完成。
-
作用
- 等待一个 Service 创建完成
- 将 Pod 注册到远程服务器
- 克隆 Git 仓库到数据卷
- 将配置值放到配置文件中
1 | apiVersion: v1 |
initContainer生命周期
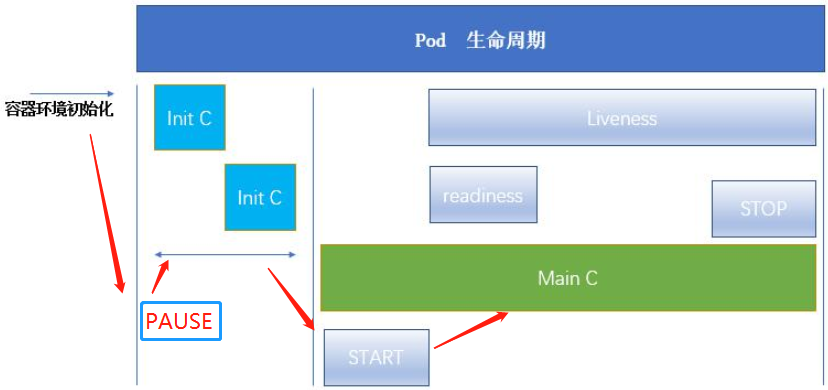
- Init容器会按顺序在网络和数据卷初始化之后启动
- 每个容器必须在下一个容器启动之前成功退出。如果由于运行时或失败退出,将导致容器启动失败
- 它会根据Pod的restartPolicy指定的策略进行重试
- 在所有的 Init 容器没有成功之前,Pod 将不会变成 Ready 状态
- 如果 Pod 重启,所有 Init 容器必须重新执行
- Init 容器的代码应该是幂等的
- Init 容器的名称必须唯一
- 与任何其它容器共享同一个名称,会在验证时抛出错误。
Pause容器
- 镜像非常小,目前在700KB左右
- 永远处于Pause(暂停)状态
容器之间原本是被 Linux Namespace 和 cgroups 隔开,要让容器之间共享网络和存储,Pause容器就是为解决Pod中的网络问题而生的。
在每个 Pod 里,额外起一个 Infra container 小容器来共享整个 Pod 的 Network Namespace。其他所有容器都会通过 Join Namespace 的方式加入到 Infra container 的 Network Namespace 中。所以说一个 Pod 里面的所有容器,它们看到的网络视图是完全一样的。即:它们看到的网络设备、IP地址、Mac地址等等,跟网络相关的信息,其实全是一份,这一份都来自于 Pod 第一次创建的这个 Infra container。这就是 Pod 解决网络共享的一个解法。
容器探针
探针是由 kubelet 对容器执行的定期诊断。要执行诊断,kubelet 调用由容器实现的 Handler。有三种类型的处理程序:
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为
0则认为诊断成功。 - TCPSocketAction:对指定端口上的容器的IP地址进行TCP检查。如果端口打开,则诊断被认为是成功的
- HTTPGetAction:对指定的端口和路径上的容器的IP地址执行HTTP Get请求。如果响应的状态码大于等于200且小于400,则诊断被认为是成功的
探针类型
- livenessProbe:指示容器是否正在运行
- 如果容器中的进程能够在遇到问题或不健康的情况下自行崩溃,则不一定需要存活探针
- readinessProbe:指示容器是否准备好服务请求
- startupProbe:
- 判断容器内的应用程序是否已启动。如果提供了启动探测,则禁用所有其他探测,直到它成功为止。
- 如果启动探测失败,kubelet将杀死容器,容器将服从其重启策略。如果容器没有提供启动探测,则默认状态为成功。
- startupProbe探测成功后再交给livenessProbe,防止无限炸
readinessGates
又被称为pod “ready++”,在这之前,我们通过设置readiness probe 来决定是否Pod可以开始提供服务,但是此时可能相关联的其他基础服务并没有真正准备就绪。readinessGates给与了Pod之外组件控制Pod 就绪的能力。
Pod Preset
Preset 就是预设,有时候想要让一批容器在启动的时候就注入一些信息,比如 secret、volume、volume mount 和环境变量,而又不想一个一个的改这些 Pod 的 template,这时候就可以用到 PodPreset 这个资源对象了。
Pod Preset 是用来在 Pod 被创建的时候向其中注入额外的运行时需求的 API 资源。
Node
Node 是 Kubernetes 集群的工作节点,可以是物理机也可以是虚拟机
- Node包括如下状态信息
- Address
- HostName:可以被 kubelet 中的 --hostname-override 参数替代。
- ExternalIP:可以被集群外部路由到的 IP 地址。
- InternalIP:集群内部使用的 IP,集群外部无法访问。
- Condition
- OutOfDisk:磁盘空间不足时为 True
- Ready:Node controller 40 秒内没有收到 node 的状态报告为 Unknown,健康为 True,否则为 False。
- MemoryPressure:当 node 有内存压力时为 True,否则为 False。
- DiskPressure:当 node 有磁盘压力时为 True,否则为 False。
- Capacity
- CPU
- 内存
- 可运行的最大 Pod 个数
- Info:节点的一些版本信息,如 OS、kubernetes、docker 等
- Address
Secret
Secret解决了密码、token、密钥等敏感数据的配置问题,而不需要把这些敏感数据暴露到镜像或者Pod Spec中。Secret可以以Volume或者环境变量的方式使用。
- Service Account:用来访问Kubernetes API,由Kubernetes自动创建
- 自动挂载到Pod的
/run/secrets/kubernetes.io/serviceaccount
- 自动挂载到Pod的
- Opaque:base64编码格式的Secret,用来存储密码、密钥
- kubernetes.io/dockerconfigjson :用来存储私有docker registry的认证信息
1 | apiVersion: v1 |
ConfigMap
许多应用程序会从配置文件、命令行参数或环境变量中读取配置信息。这些配置信息需要与docker image解耦。ConfigMap跟Secrets类似,但是ConfigMap更方便的处理不含敏感信息的字符串。ConfigMap可以被用来保存单个属性,也可以用来保存整个配置文件或者JSON二进制大对象。
- 设置环境变量的值
- 在容器里设置命令行参数
- 在数据卷里面创建config文件
ConfigMaps不是属性配置文件的替代品。ConfigMaps只是作为多个properties文件的引用
1 | kind: ConfigMap |
- 使用ConfigMap挂载的Env不会同步更新
- 使用ConfigMap挂载的Volume中的数据需要一段时间(实测大概10秒)才能同步更新
StatefulSet
如果pod模版里描述了一个关联到特定持久卷声明的数据卷,那么ReplicaSet的所有副本都将共享这个持久卷声明。StatefulSet是为了解决有状态服务的问题(对应Deployments和ReplicaSets是为无状态服务而设计),其应用场景包括:
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
- 稳定的网络标志,即Pod重新调度后其PodName和HostName不变
- 有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行
- 有序收缩,有序删除
StatefulSet 适用于有以下某个或多个需求的应用:
- 稳定,唯一的网络标志。
- 稳定,持久化存储。
- 有序,优雅地部署和 scale。
- 有序,优雅地删除和终止。
- 有序,自动的滚动升级。
StatefulSet 中的 Pod 拥有一个唯一的顺序索引和稳定的网络身份标识。
这类应用中每一个实例都是不可替代的个体,都拥有稳定的名字和状态。
1 | apiVersion: v1 |
- 扩容/缩容:
kubectl scalekubectl patch
DaemonSet
DaemonSet 确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个 Pod 。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
- 运行集群存储 daemon,例如在每个 Node 上运行 glusterd、ceph
- 在每个 Node 上运行日志收集 daemon,例如fluentd、logstash
- 在每个 Node 上运行监控 daemon
Deployment
Deployment 为 Pod 和 ReplicaSet 提供了一个声明式定义(declarative)方法
- 定义Deployment来创建Pod和ReplicaSet
- 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续Deployment
1 | apiVersion: extensions/v1beta1 |
应用回滚
kubectl apply 每次更新应用时 Kubernetes 都会记录下当前的配置,保存为一个 revision(版次),这样就可以回滚到某个特定 revision。
1 | # 记录版本 |
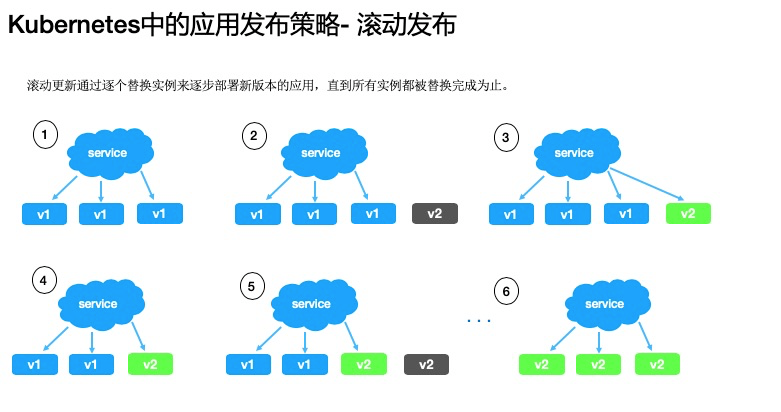
滚动发布
通过逐个替换实例来逐步部署新版本的应用,直到所有实例都被替换完成为止。
go-demo-v1.yaml
1 | apiVersion: apps/v1 |
1 | # 部署版本 v1 |
- 版本在实例之间缓慢替换
- 这个滚动发布可能需要一定时间
- 无法控制流量
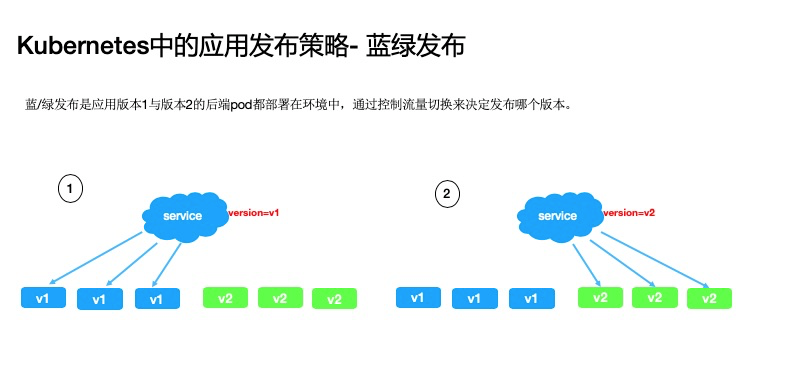
蓝绿发布
通过控制流量切换来决定发布哪个版本。与滚动发布相比,蓝绿发布策略下的应用终态,是可以同时存在版本 1 和版本 2 两种 pod 的,我们可以通过 service 流量的切换来决定当前服务使用哪个版本的后端。
go-demo-v1.yaml
1 | apiVersion: apps/v1 |
go-demo-v2.yaml
1 | apiVersion: apps/v1 |
service.yaml
1 | apiVersion: v1 |
1 | $ kubectl apply -f go-demo-v1.yaml -f go-demo-v2.yaml -f service.yaml |
蓝绿发布的策略可以快速在 v1 和 v2 两个版本之前切流量
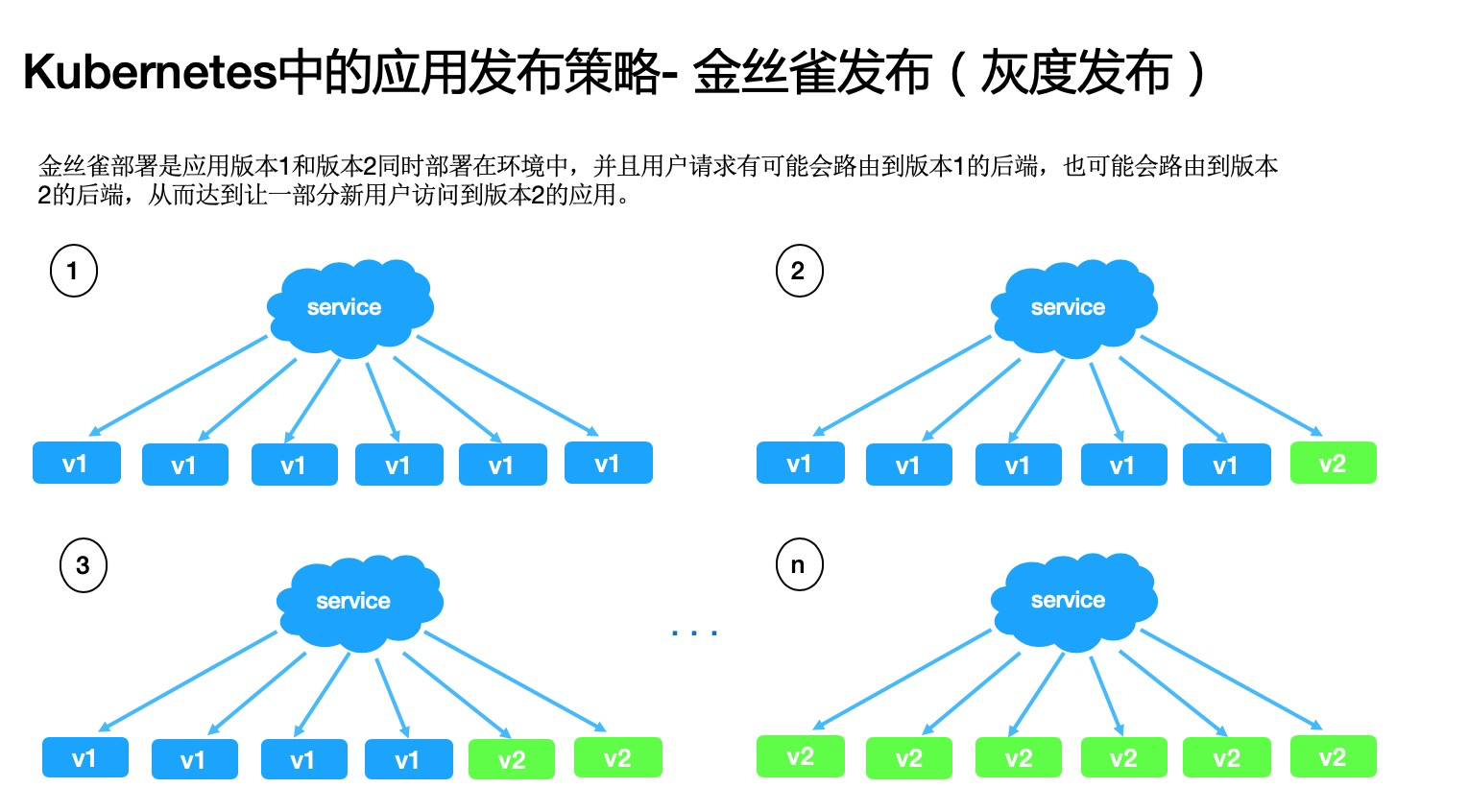
金丝雀发布
金丝雀部署是应用版本 1 和版本 2 同时部署在环境中,并且用户请求有可能会路由到版本 1 的后端,也可能会路由到版本 2 的后端,从而达到让一部分新用户访问到版本 2 的应用。 这种发布策略下,我们可以通过调整流量百分比来逐步控制应用向新的版本切换,它与蓝绿部署相比,不仅继承了蓝绿部署的优点,而且占用资源优于蓝绿部署所需要的 2 倍资源,在新版本有缺陷的情况下只影响少部分用户,把损失降到最低。
go-demo-v1.yaml:设定副本数为 9
1 | apiVersion: apps/v1 |
go-demo-v2.yaml:设定副本数为 1
1 | apiVersion: apps/v1 |
service-v1.yaml
1 | apiVersion: v1 |
service-v2.yaml
1 | apiVersion: v1 |
ingress.yaml:流量比例9:1
1 | apiVersion: extensions/v1beta1 |
1 | # 部署以上 5 个资源 |
缺点就是发布周期相对来说要慢很多。
Job
Job负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。
1 | apiVersion: batch/v1 |
Federation
Service
Kubernetes Service 定义了这样一种抽象:一个Pod的逻辑分组,一种可以访问它们的策略 —— 通常称为微服务。这一组Pod能够被Service访问到,通过Label Selector
- userspace 代理模式
- 默认的策略是,通过 round-robin 算法来选择 backend Pod
- iptables 代理模式
- 默认的策略是,随机选择一个 backend
- ipvs 代理模式
- rr:轮询调度
- lc:最小连接数
- dh:目标哈希
- sh:源哈希
- sed:最短期望延迟
- nq: 不排队调度
1 | kind: Service |
Headless Service
有时不需要或不想要负载均衡,以及单独的 Service IP。遇到这种情况,可以通过指定 Cluster IP(spec.clusterIP)的值为 “None” 来创建 Headless Service。
对这类 Service 并不会分配 Cluster IP,kube-proxy 不会处理它们,而且平台也不会为它们进行负载均衡和路由。DNS 如何实现自动配置,依赖于 Service 是否定义了 selector。
Volume
默认情况下容器中的磁盘文件是非持久化的,容器中的磁盘的生命周期是短暂的
- Kubernetes中的卷有明确的寿命——与封装它的Pod相同
- 当Pod不再存在时,卷也将不复存在
- 容器重启,卷还存在
- 一个volume就是一个目录
存储卷常用类型
- 非持久性存储
emptyDir- 暂存空间,例如用于基于磁盘的合并排序
- 用作长时间计算崩溃恢复时的检查点
- Web服务器容器提供数据时,保存内容管理器容器提取的文件
hostPath网络连接性存储分布式存储云端存储
Persistent Volume
PersistentVolume(PV)是由管理员设置的存储,它是群集的一部分。就像节点是集群中的资源一样,PV 也是集群中的资源。PV是Volume之类的卷插件,但具有独立于使用PV的Pod的生命周期。
PV 属于集群中的资源。PVC 是对这些资源的请求,也作为对资源的请求的检查。 PV 和 PVC 之间的相互作用遵循这样的生命周期
用户进行了声明,并且该声明是绑定的,则只要用户需要,绑定的 PV 就属于该用户。用户通过在 Pod 的 volume 配置中包含 persistentVolumeClaim 来调度 Pod 并访问用户声明的PV。
PVC 保护的目的是确保由 pod 正在使用的 PVC 不会从系统中移除,因为如果被移除的话可能会导致数据丢失。
Persistent Volume Claim
PersistentVolumeClaim(PVC)是用户存储的请求。它与 Pod 相似。Pod 消耗节点资源,PVC 消耗 PV 资源。Pod 可以请求特定级别的资源(CPU 和内存)。声明可以请求特定的大小和访问模式(例如,可以以读/写一次或 只读多次模式挂载)。
使用PVC的流程:
- 配置存储空间 — 由存储管理员配置存储设备(如NFS,iSCSI,Ceph RBD,Glusterfs),并且划割好了很多可被独立使用的存储空间;
- 定义PV — K8S集群管理员将配置好的那些存储空间引入至K8S集群中,定义成PV (Persistent Volume,持久化卷);
- 定义PVC — K8S用户在创建Pod时如果要用到PVC时,必须先创建PVC( 在K8S集群中找一个能符合条件的存储卷PV来用)。注意:PV和PVC是一一对应关系,一旦某个PV被一个PVC占用,那么这个PV就不能再被其他PVC占用,被占用的PV的状态会显示为Bound。PVC创建以后,就相当于一个存储卷,可以被多个 Pod所使用。
- 使用PVC — 在Pod中去使用PVC,如果符合PVC条件的PV不存在,而这时去使用这个PVC,则Pod这时会显示Pending(挂起)状态。
StorageClass
使用上述PVC时,有一个弊端:当K8S用户创建要使用PVC时,必须确保K8S集群中已经存在符合PVC条件的PV,否则Pod就会处于Pending(挂起)状态。存储类(StorageClass)就是来解决这个问题的。动态创建PV供PVC绑定。
定义好存储类以后,PVC再去申请PV时,不再直接针对PV进行绑定,而是通过存储类去动态创建符合PVC条件的PV,再进行绑定。
Etcd
Ingress网络
Ingress网络是一组规则,充当Kubernetes集群的入口点。这允许入站连接,可以将其配置为通过可访问的URL,负载平衡流量或通过提供基于名称的虚拟主机从外部提供服务。因此,Ingress是一个API对象,通常通过HTTP管理集群中服务的外部访问,是暴露服务的最有效方式。
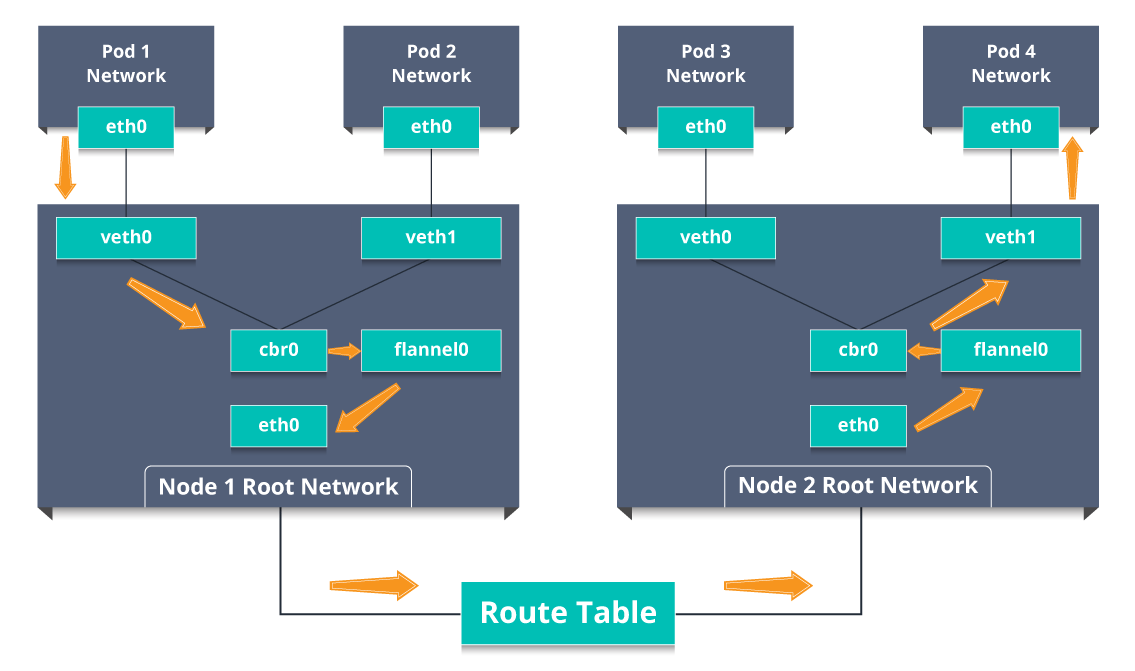
- 因此,数据包将pod1的网络保留在eth0,并进入veth0的根网络。
- 然后它被传递给cbr0,这使得ARP请求找到目的地,并且发现该节点上没有人具有目的地IP地址。
- 因此,桥接器将数据包发送到flannel0,因为节点的路由表配置了flannel0。
- 现在,flannel守护程序与Kubernetes的API服务器通信,以了解所有pod IP及其各自的节点,以创建pods IP到节点IP的映射。
- 网络插件将此数据包封装在UDP数据包中,其中额外的标头将源和目标IP更改为各自的节点,并通过eth0发送此数据包。
- 现在,由于路由表已经知道如何在节点之间路由流量,因此它将数据包发送到目标节点2。
- 数据包到达node2的eth0并返回到flannel0以解封装并在根网络命名空间中将其发回。
- 同样,数据包被转发到Linux网桥以发出ARP请求以找出属于veth1的IP。
- 数据包最终穿过根网络并到达目标Pod4。
通常情况下,service和pod仅可在集群内部网络中通过IP地址访问。所有到达边界路由器的流量或被丢弃或被转发到其他地方。
1 | internet |
Ingress是授权入站连接到达集群服务的规则集合。可以给Ingress配置提供外部可访问的URL、负载均衡、SSL、基于名称的虚拟主机等
1 | internet |
1 | apiVersion: extensions/v1beta1 |
Namespace
- 一个集群内部的逻辑隔离机制(鉴权,资源额度)
- 每个资源都属于一个Namespace
- 同一个Namespace中资源命名唯一
- 不同Namespace中的资源可重名
在一个Kubernetes集群中可以使用namespace创建多个虚拟集群,这些namespace之间可以完全隔离。也可以通过某种方式,让一个namespace中的service可以访问到其他的namespace中的服务
例如生产、测试、开发划分不同的 namespace。
default:没有指明使用其它命名空间的对象所使用的默认命名空间kube-system:系统创建对象所使用的命名空间kube-public: 公共资源使用。但实际上现在并不常用。
并非所有对象都在命名空间中
<hostname>.<subdomain>.<namespace>.svc.<cluster domain><hostname>.<namespace>.svc.cluster.local
切换Namespace
1 | kubectl configset-context $(kubectl config current-context) --namespace=dev |