为了能让机器执行和完成识别任务,必须对分类识别对象进行科学的抽象,建立它的数学模型,用以描述和代替识别对象,这种对象的描述即为模式。
graph TD
学习训练-->分类识别
模式识别的核心问题
graph LR
特征提取与选择-->训练学习
训练学习-->分类识别
- 统计模式识别
- 模糊模式识别
- 线性分类器
- 贝叶斯分类器
- 最近邻分类器
- 神经网络分类器
- 统计聚类算法
- 结构模式识别
基本原则
绪论
特征矢量
一个分析对象的n个特征量测值分别为x1,x2,⋯,xn,它们构成一个n维特征矢量x
x=(x1,x2,⋯,xn)
x是原对象(样本)的一种数学抽象,用来表示原对象,即为原对象的模式
特征空间
对某对象的分类识别是对其模式,即它的特征矢量进行分类识别。
各种不同取值的x的全体构成了n维空间,这个n维空间称为特征空间,不同的场合的特征空间可以记为Xn,Rn。特征矢量x便是特征空间中的一个点,所以也称特征点
随机变量
由于测量系统随机因素的影响及不同对象的特征本身就是在特征空间散布的,同一个对象或同一类对象的某特征量测值是随机变量,由随机分量构成的矢量称为随机矢量,同一类对象的特征矢量在特征空间中是按照某种统计规律随机散布的
随机矢量的分布函数
设
- 随机矢量:X=(X1,X2,⋯,Xn)T
- 确定型矢量:x=(x1,x2,⋯,xn)T
随机矢量X的联合概率分布函数定义为
F(x1,x2,⋯,xn)=P(X1≤x1,X2≤x2,⋯,Xn≤xn)
写成矢量形式
F(x)=P(X<x)
联合概率密度函数
设
- 随机矢量:X=(X1,X2,⋯,Xn)T
- 确定型矢量:x=(x1,x2,⋯,xn)T
随机矢量X的联合概率密度函数定义为
p(x1,x2,⋯,xn)=∂x1,∂x2,⋯,∂xn∂nF(x1,x2,⋯,xn)
类概率密度函数
设集合由c类模式组成,第i类记为ωi,ω类模式特征矢量有自己的分布函数和密度函数
F(x∣ωi)p(x∣ωi)=P(X≤x∣ωi)=∂x1,∂x2,⋯,∂xn∂nF(x1,x2,⋯,xn∣ωi)
随机矢量的数学特征
随机矢量数学期望
n维随机矢量X的数学期望μ定义为
μ=E[X]=X=⎣⎢⎢⎡E[X1]E[X2]⋯E[Xn]⎦⎥⎥⎤=∫Xnxp(x)dx
随机矢量条件期望
在模式识别中,经常以类别ωi作为条件,在这种情况下随机矢量X的条件期望矢量定义为
μi=E[X∣ωi]=∫Xnxp(x∣ωi)dx
协方差矩阵
给定n元的多维随机变量X和m元的多维随机变量Y,则它们的协方差矩阵为
Cov(X,Y)=Σ=⎣⎢⎢⎢⎡Cov(x1,y1)Cov(x2,y1)⋮Cov(xn,y1)Cov(x1,y2)Cov(x2,y2)⋮Cov(xn,y2)⋯⋯⋱⋯Cov(x1,ym)Cov(x2,ym)⋮Cov(xn,ym)⎦⎥⎥⎥⎤=E(XYT)−E(X)E(Y)T
其中Cov(X,X)为X自身的协方差矩阵可以写作
Cov(X,X)=E((X−μ)(X−μ)T)=E(XXT)−μμT=(σij2)n×n
自相关矩阵
随机矢量X的自相关矩阵定义为
R=E[XXT]
由定义可知,X的协方差矩阵和自相关矩阵间的关系是
Σ=R−XXT=R−μμT
相关系数
rij=σiiσjjσij2
由布尼亚科夫斯基不等式知道
∣σij2∣≤σiiσjj
所以
−1≤rij≤1
相关系数矩阵定义为
Rc=(rij)n×n
对称非负定矩阵
协方差矩阵和自相关矩阵都是对称矩阵,设A为对称矩阵,对任意的矢量x,由二次型xTAx,若对任意的x恒有
xTAx≥0
则称A为非负定矩阵
不相关
随机矢量X的第i分量Xi,和第j个分量Xj,若有σij2=0(i=j),则称它们不相关
等价条件:
E[XiXj]=E[Xi]E[Xj]
随机矢量X和Y不相关的充要条件是互协方差矩阵Cov(X,Y)=0,即
E[XYT]=E[X]E[YT]
正交
若随机矢量X和Y满足
E[XTY]=0
则称X和Y正交
独立
若随机矢量X和Y的联合概率密度函数p(x,y),若满足p(x,y)=p(x)p(y),则称它们独立
随机矢量的变换
设随机矢量Y是另一个随机矢量X的连续函数,即
Y=⎣⎢⎢⎢⎡Y1Y2⋮Yn⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡g1(X1,X2,⋯,Xn)g2(X1,X2,⋯,Xn)⋮gn(X1,X2,⋯,Xn)⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡g1(X)g2(X)⋮gn(X)⎦⎥⎥⎥⎤=g(X)
若它们的函数关系是一一对应的,则两个随机矢量的概率密度函数之间有关系
p(y)J=Jp(x)=∣∣∣∣∣∣∣∣∣∣∂x1∂g1∂x1∂g2⋮∂x1∂gn∂x2∂g1∂x2∂g2⋮∂x2∂gn⋯⋯⋱⋯∂xn∂g1∂xn∂g2⋮∂xn∂gn∣∣∣∣∣∣∣∣∣∣
J为雅可比行列式,表示变换后体积微元的变化,Yn坐标系中体积微元
dy1dy2⋯dyn=∣J∣dx1dx2⋯dxn
Y=⎣⎢⎢⎢⎡Y1Y2⋮Yn⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡a11X1,a12X2,⋯,a1nXn)a21X1,a22X2,⋯,a2nXn)⋮an1X1,an2X2,⋯,annXn)⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡a11a21⋮an1a12a22⋮an2⋯⋯⋱⋯a1na2n⋮ann⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡XX⋮X⎦⎥⎥⎥⎤=AX
此时J=∣A∣,则随机矢量Y的概率密度函数
p(y)=∣∣A∣∣p(x)
设X的均值矢量为μx,协方差矩阵为Σx,则
- Y均值矢量:μy=E[Y]=AE[X]=Aμx
- Y协方差矩阵:Σy=AE[(X−μx)(X−μx)T]AT=AΣxAT
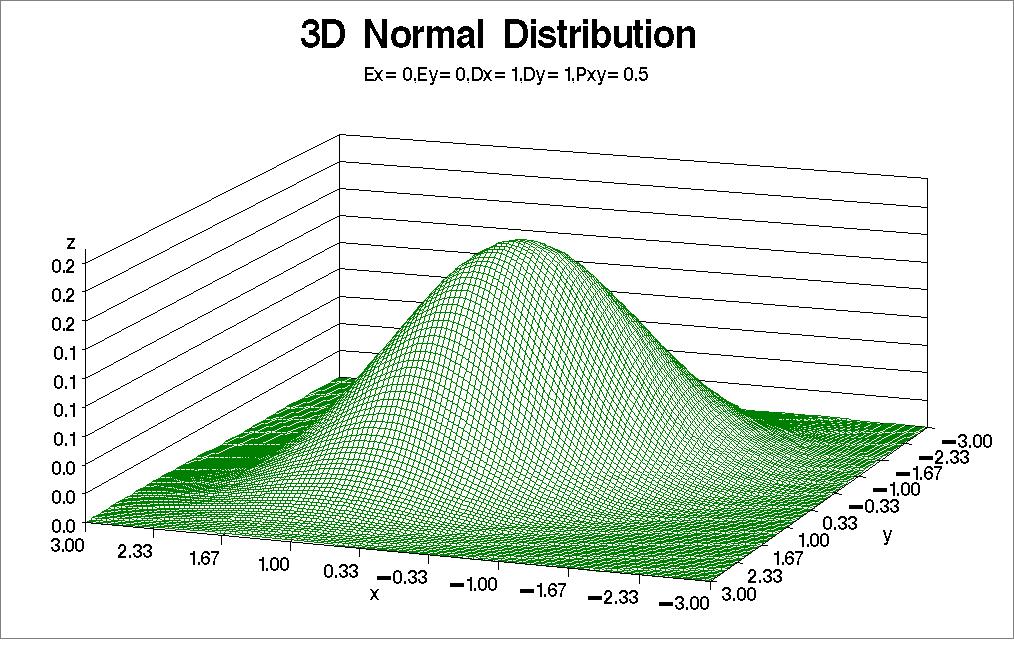
正态分布
- 许多随机变量近似服从正太分布
- 是许多重要概率分布的极限分布
p(x)=2πσ1exp[−2σ2(x−μ)2]
多变量正态分布
n元正态分布的随机矢量X=(X1,X2,⋯,Xn)T的概率密度函数定义为
p(x1,x2,⋯,xn)=p(x)=(2π)2n∣Σ∣211exp[−21(x−μ)TΣ−1(x−μ)]
- 完全由x和Σ确定:X∼N(μ,Σ)
- 等概率密度点的轨迹为超椭球面
- 不相关与独立式等价的
- 多元正态随机矢量X的边缘概率密度的条件概率密度仍是正态分布
- X的线性变换仍为多元正态随机矢量
- X的分量的线性组合式一多元正态随机变量

聚类分析
假设:对象集客观存在着若干个自然类,每个自然类中个体的某些属性具有较强的相似性
原理:将给定的模式分成若干组,每组内的模式是相似的,而组内各模式差别较大
基本思想:
- 相似的归为一类
- 模型相似性的度量和聚类算法
- 无监督分类
特征量的类型
- 物理量 - (重量,长度,速度)
- 次序量 - (等级,技能,学识)
- 名义量 - (性别,状态,种类)
方法的有效性:取决于分类算法和特征点分布情况的匹配
- 特征选取不当使分类无效
- 特征选取不足可能使不同类别判为一类
- 特征选取过多可能无益反而有害,增加负担,效果变差
- 量纲选取不当
聚类分析的基本思想
- 特征提取
- 模式相似度量
- 点与类间的距离
- 类与类间的距离
- 聚类准则及聚类算法
- 有效性分析
模式相似性测度
用于描述个模式之间特征的相似程度
距离测度
- 测度基础:两个矢量矢端的距离
- 测度数值:两矢量各相应分量之差的函数
设矢量x和y的距离为d(x,y)
- d(x,y)≥0,当且仅当y=x时,等号成立
- d(x,y)=d(y,x)
- d(x,y)≤d(x,z)+d(z,y)
欧式距离
d(x,y)=∣∣x−y∣∣=i=1∑n(xi−yi)2
绝对值距离
d(x,y)=i=1∑n∣xi−yi∣
切氏距离
d(x,y)=imax∣xi−yi∣
明氏距离
d(x,y)=[i=1∑n∣xi−yi∣m]m1
马氏距离
设n维矢量xi和xj是矢量集{x1,x2,⋯,xm}中的两个矢量,马氏距离为
d2(xi,xj)=(xi−xj)TV−1(xi−xj)
其中
Vx=m−11i=1∑m(x1−x)T(xi−x)=m1i=1∑mxi
与量纲无关,对一切非奇异线性变换都是不变的,具有坐标系比例,选择,平移不变性,从统计意义上尽量去掉了分量间的相关性
相似测度
测度基础:两个矢量的方向是否相近作为考虑的基础,矢量长度并不重要
角度相似系数
cos(x,y)=∣∣x∣∣⋅∣∣y∣∣∣xy
对坐标系的旋转和尺度的缩放具有不变性
相关系数
数据中心化后的矢量夹角余弦
r(x,y)=[(x−x)T(x−x)(y−y)T(y−y)]21(x−x)T(y−y)
指数相似系数
e(x,y)=n1i=1∑nexp[−43σi2(xi−yi)2]
- σi2:相应分量的协方差
- n:矢量维数
匹配测度
当特征只有两个状态(0,1)时,常用匹配测度,0表示无此特征,1表示有此特征,故称之为二值特征,对于给定的x和y中的某两个相应的分量xi与yj
x=0,1,0,1,1,0y=0,0,1,1,0,1
- 若xi=1,yi=1,则称xi与yi是(1−1)匹配
- 若xi=1,yi=0,则称xi与yi是(1−0)匹配
- 若xi=0,yi=1,则称xi与yi是(0−1)匹配
- 若xi=0,yi=0,则称xi与yi是(0−0)匹配
对于二值n维特征矢量可定义如下相似性测度
- a=∑ixiyi:为x,y的(1−1)匹配的特征数目
- b=∑iyi(1−xi):为x,y的(0−1)匹配的特征数目
- a=∑ixi(1−yi):为x,y的(1−0)匹配的特征数目
- a=∑i(1−xi)(1−yi):为x,y的(0−0)匹配的特征数目
Tanimoto测度
s(x,y)=a+b+ca=xTx+yTy−xTyxTy
它等于共同具有的特征数目与分别具有的特征种类总数之比
Rao测度
s(x,y)=a+b+c+ea=nxTy
为(1−1)匹配特征数目和所选用的特征数目之比
简单匹配系数
(x,y)=na+e
上式分子为(1−1)匹配特征数目与(0−0)匹配特征数目之和,分母为所考虑的特征数目
Dice系数
m(x,y)=2a+b+ca=xTx+yTyxTy=两矢量中1的个数(1−1)匹配个数
Kulzinsky系数
m(x,y)=b+ca=xTx+yTy−2xTyxTy=(0−1)+(1−0)匹配个数(1−1)匹配个数
类的定义与类间距离
类的约束:对于一个待分类的集合S,要求分类后的各类S1,S2,⋯,Sc满足
- Si=∅
- ∪i=1cSi=S
- Si∪Sj=∅,i=j
类的定义
定义:若集合S中任两个元素xi,xj的距离dij有
dij≤h
则称S相对于阈值h组成一类
定义:若集合S中任一元素xi与其他各元素xj间的距离dij均满足
k−11xj∈S∑dij≤h
则称S相对于阈值h组成一类(k为集合元素个数)
定义:若集合S中任一元素xi与其他各元素xj间的距离dij均满足
k(k−1)1xi∈S∑xj∈S∑dij≤h,dij≤r
则称S相对于阈值h,r组成一类
定义:若集合S中任一元素xi,都存在某元素xj∈S使它们的距离dij满足
dij≤h
则称S相对于阈值h组成一类
类的距离定义
最近距离法
Dkl=i,jmin⌊dij⌋
最远距离法
Dkl=i,jmax⌊dij⌋
中心距离法
Dkl2=21Dkp2+21Dkp2−41Dpq2
重心距离法
中心距离法考虑样本数量之后(权重)
Dkl2=np+nqnpDkp2+np+nqnqDkp2−(np+nq)2npnqDpq2
平均距离法
Dpq2=npnq1∑dij2
所有点的距离的平均
离差平方和距离法
Dkl2stDpq2=nk+nlnk+npDkp2+nk+nlnk+nqDkq2−nk+nlnkDpq2=xi∈ω∑(xi−xt)T(xi−xt)=sl−sp−sq=np+nqnpnq(xp−xq)T(xp−xq)
xp,xq,xt分布为对应类的重心
准则函数
点和集合的距离
- 第一类:对集合的分布没有先验知识时,可采用类间距离计算
- 第二类:当知道集合的中点分布的先验知识时,可用相应的模型进行计算
聚类的准则函数
标准:内间距离小,类间距离大
设有待分类的模式集{x1,x2,⋯,xn}在某种相似性测度基础上被划分为c类,类内距离准则函数jw定义为
jw=j=i∑ci=1∑nj(xi(j)−mj)2mj表示ωj类的模式均值矢量
加权聚类的准则函数
jww=j=1∑cNnjdj2dj2=nj(nj−2)2∑∣∣xj(j)−xk(j)∣∣
- ∑∣∣xi(j)−xk(j)∣∣:表示ωj类内任意两个模式距离平方和
- dj2:表示类内两模式间的均方距离
- N:待分类模式总数
- Nnj:表示ωj类先验概率的估计-频率
类间距离准则函数
JB=maxj=1∑c(mj−m)T(mj−m)
- mj:为ωj类的模式平均矢量
- m:为总的模式平均矢量
加权类间距离准则函数
JWB=maxj=1∑cNnj(mj−m)T(mj−m)
对于两类问题,类间距离有时取
JB2=(m1−m2)T(m1−m2)
JB2和JWB的关系是:JWB=Nn1Nn2JB2
聚类的准则函数+类间距离准则函数
我们希望内间距离小,类间距离大,所以构造出能够同时反映出它们的类间距离的准则函数最好
设待分类{x1,x2,⋯,xn},分为c类,每个类含nj和模式xi(j)
ωj的类内离差阵(样本协方差矩阵但是没有减1)定义为
Sw(j)=nj1i=1∑nj(xi(j)−mj)(xi(j)−mj)Tj=1,2,⋯,c
- mj:为ωj类的模式平均矢量
- 总的类内离差阵:Sw=∑j=1cNnjSw(j)
- 类间离差阵:SB=∑j=1cNnj(mj−m)(mj−m)T
- 总的离差阵:Sr=N1∑i=1NNnj(mi−m)(mi−m)T
Sr=Sw+SB
聚类的基本目的是maxtr(SB)或mintr(Sw),利用线性代数有关矩阵的迹和行列式的性质,可以定义如下4个聚类的准则函数
J1J2J3J4=tr(Sw−1SB)=∣Sw−1SB∣=tr(Sw−1ST)=∣Sw−1ST∣
为了得到更好的聚类结果,应该使它们尽量的大
聚类的算法
- 按最小距离原则简单聚类方法
- 按最小距离原则进行两类合并的方法
- 依据准则函数动态聚类方法
简单聚类方法
确定一个相似性阈值,将模式到各聚类中心间的距离与阈值比较
- 当大于阈值就作为另一类的类心
- 当小于阈值就按最小距离原则将其划分到某一类中
模式的类别及类的中心一旦确定将不会改变,聚类结果很大程度依赖T的选取,初始值的选取,和选模式的顺序也会造成不同
设待分类{x1,x2,⋯,xn},选定类间距离阈值T
计算模式特征矢量到聚类中心的距离并合并门限T比较,决定归属该类或作为新的一类中心,通常选择欧式距离
- 任取一个模式特征矢量作为第一个聚类中心z1
- 计算下一个模式特征矢量计算x2到z1的距离
- 若大于T,则新建一类并作为中心
- 若小于T,则属于这一类
- 对于尚未确定类别的模式,计算到各聚类中心的聚类进行判断
最小距离两类合并
首先全部作为一类,然后将距离最小的两类合并为一类,不断重复,直到分为2类位置
类心不断修正,单模式类别一旦确定后就不再改变,称为谱系聚类法
依据准则函数动态聚类方法
设定一些分类的控制参数,定义一个表征聚类结构优劣的准则函数,聚类过程就是最优化函数取极值的优化过程
最大最小距离算法
设待分类{x1,x2,⋯,xn},选定比例系数θ
在模式特征矢量中以最大距离原则选取新的聚类中心,以最小距离原则进行模式归类,通常选择欧式距离
- 选任一模式特征矢量作为第一个聚类中心z1
- 从待分类矢量集中选距离z1最远的特征矢量作为第二个聚类中心
- 计算未被作为聚类中心的各模式特征矢量分别与z1,z2之间的距离,对每一个模式计算一个当前距离聚类中心的最小值
- 在上方所有最小值中取一个最大值,判断是否大于θ∣∣z1−z2∣∣
- 若大于,则作为第三个聚类中心
- 如果等于,转第5步
- 如果小于,转第6步
- 设存在k个聚类中心,计算未被作为聚类中心的各特征矢量到各聚类中心的距离
- 同理按照第4步进行计算
- 当判断不再有新的聚类中心之后,将剩余的模式按最小距离原则分到各类中去
谱系聚类法
- 初始分类,每个模式自成一类
- 计算各类间的距离,生成一个对称的距离矩阵
- 找出最小的元素,合并为一类,产生新的聚类
- 重复上述步骤直到只有一类
动态聚类法
不是采用贪心算法等,被分类后的模式还可以继续改变
- 采用欧式距离:单纯计算距离
- 采用马氏距离:能反映出类的模式分布结构
- 建立初始聚类中心,进行初始聚类
- 计算模式和类的距离,调整模式的类别
- 计算各聚类的参数,删除,合并或分裂一些聚类
- 从初始聚类开始,运用迭代算法动态地改变模式的类别和聚类的中心使准则函数取得极值或设定的参数达到设计要求
graph LR
待分类模式-->产生初始聚类中心
产生初始聚类中心-->聚类
聚类-->检验聚类合理性
检验聚类合理性--不合理-->再迭代丨修改参数
再迭代丨修改参数-->聚类
检验聚类合理性--合理-->分类结果
C-均值法
取定C个类别和选取C个初始聚类中心,按最小距离原则将各模式分配到C类中的某一类,之后不断地计算类心和调整各模式的类别,最终使各模式到其判属类别中心的距离平方之和最小。
- 任选C个模式特征向量作为初始聚类中心
- 将待分类的模式特征矢量集中的模式逐个按最小距离原则划分给C类中的某一类
- 计算重新分类后的各类心
- 判断与上次计算类心是否相同,相同则结束,否则转到第2步
C-均值法分类结果容易受到类别数和初始聚类中心的影响,通常结果只是局部最优的,但是方法简单,结果差强人意,所以应用较多
- 类数c的调整
- 利用先验知识选取
- 让类数递增重复进行聚类,选取J−c曲线曲率变化最大点所对应的类数
- 初始聚类中心的选取课采取的方式
- 凭经验选取
- 将模式随机分为c类计算每类内心
- 按密度大小选取
- 选取相距最远的c个特征点
- 随机地选出c个,用谱系聚类法聚成c类,选取类心
- 由c−1类问题,选取下一个最远的c点
近邻函数法
在C-均值法中,当类内样本非球状散布时,用样本的均值矢量作为类的代表,一般聚类结果不佳,如果我们有类的模式分布的某些先验知识,可以构造能反映类的模式分布情况的核函数,那么就以核函数来代表类
如果实际中不能确定核函数或不能用简单的函数表示核函数时,可以采用临界函数法,这种算法特别适用于类的模式分布式条状或线状的情况
近邻函数:对于一个样本集中的任意两个样本xi和xj,如果xi是xj的第i个近邻点,则定义xi对xj的近邻系数为I,记为d(i,j)=I,如果xj是xi的第j个近邻点,则定义xi对xj的近邻系数为J,记为d(j,i)=J,于是xi和xj之间的近邻函数值定义为
aij=d(i,j)+d(j,i)−2=I+J−2
当xi和xj互为最近邻时,有aij=0,如果样本集包含N个样本,那么近邻系数总是小于等于N−1,因此xi和xj之间的近邻函数值满足
aij≤2N−4
连接损失:在聚类过程中,如果xi和xj被聚为一类,就称xi和xj是互相连接的,对于每个连接,都应定义一个指标,用以刻画这两个样本是狗适于连接,称其为连接损失
aij越小,表明它们越相似,把它们连接起来,损失也越小,所以aij可作为连接损失
在聚类过程中,对于样本xi,计算它与其他样本间的近邻函数数值,取最小把它们连接起来,并有连接损失aik
类内连接损失:设有c类,总的类连接损失定义为
Lw=p=1∑c∑aij
记ωj类的类内最大近邻函数值
ap=max⌊aij⌋
设聚类ωp和ωq的样本之间的最小近邻函数值为rpq
rpq=min⌊aij⌋
设rpk聚类ωp与其他各聚类的最小近邻函数值为rpq
rpk=min⌊rpq⌋
上面表明,除ωp类内样本外,只有ωk中的某一个样本与ωp中某一个样本最临界,近邻函数值为rpk
定义总的类间损失
LB=p=1∑cβp
聚类的目标是使各rpk尽可能地大,使各ap尽可能的小,因而构造聚类的准则函数为
JL=min(Lw+LB)
算法步骤
- 对于给定的待分类样本集,计算距离矩阵D
- 利用矩阵D,计算近邻矩阵M,其元素Mij为样本x对x的近邻系数
- 生成近邻矩阵L,其阵元为Lij=Mij+Mji−2,置矩阵L的主对角线上阵元Lii=2N,如果xi和xj有连接,则Lij给出它们非零近近邻函数值,即连接损失
- 搜索矩阵L,将每个点与和它有最小近邻函数值的点连接起来,形成初始聚类
- 对于4.所形成的聚类,计算rpk,apm,akm,若rpk小于或等于apm或akm,则合并ωk和ωp,它们的样本间建立连接关系,转至5,否则结束
上诉过程将使JL最小
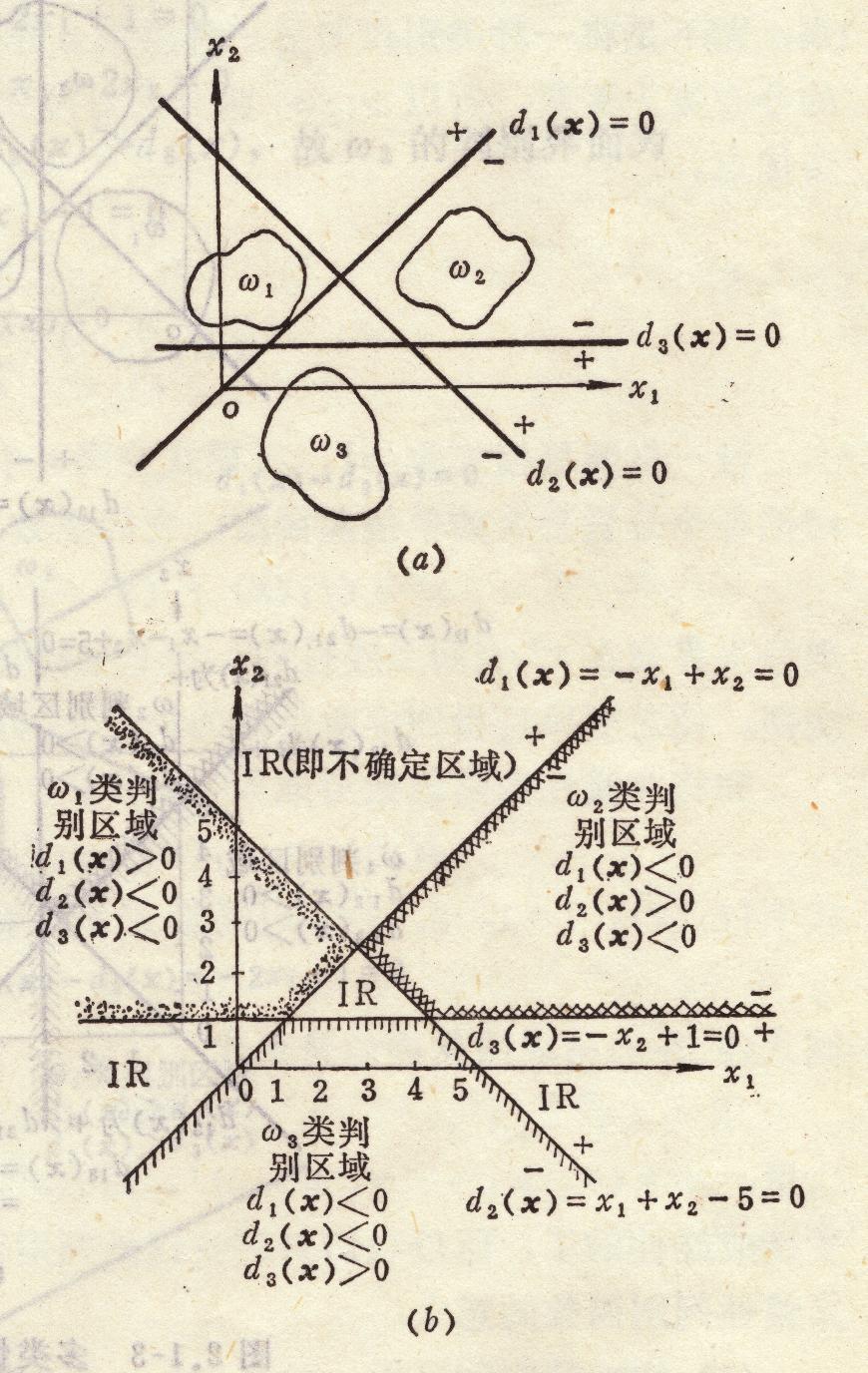
判别域代数界面方程法
判别域界面方差分类
原理:不同模式对应特征点在不同的区域中散布,运用已知类别的训练样本进行学习,产生若干个代数界面,d(x)将特征空间划分为一些互不重叠的子区域
判别函数:表示界面的函数d(x)
线性可分:对于来自两类的一组模式,如果能用一个线性判别函数正确分类,则为线性可分
线性判别函数
在n维特征空间中,特征矢量为x=(x1,x2,⋯,xn)T,线性判别函数的一般形式为
d(x)=w1x1+w2x2+⋯+wnxn+wn+1=w0Tx+wn+1
w0称为权矢量或系数矢量,简化为
d(x)xw=wTx=(x1,x2,⋯,xn,1)T=(w1,w2,⋯,wn,wn+1)T
增广权矢量:w
增广特征矢量:x
线性判别两类问题
d(x)⎩⎪⎨⎪⎧>0→x∈ω1<0→x∈ω2=0→拒判
线性判别多类问题
ωi/ωi两分法
将属于ω1类和不属于ωi类的模式分划开,c类问题转化为c−1个两类问题,可以建立c个判别函数
di(x)=wiTx,i=1,2,⋯,c
通过训练,其中每个判别函数都具有下面的性质
di(x){>0<0x∈ωix∈ωi
将ωi和ωi类分开
ωi/ωj两分法
对于c类中的任意两类ωi和ωj都分别建立一个判别函数,这个判别函数将属于ωi的模式与属于ωj的模式区分开,此函数对其他模式分类不提供信息,因此总共需要c(c−1)/2个这样的判别函数,通过训练,区分i,j两类的判别函数为
dij(x)=wijx,i,j=1,2,⋯,c,i=j
dij(x)=wijx{>0<0x∈ωix∈ωj
具有性质dij(x)=−dji(x),判别规则
dij(x)>0,∀j=i→x∈ωi
将ωi和ωj类分开
没有不确定区的ωi/ωj两分法
令上面的判别函数为
dij(x)=di(x)−dj(x)=(wi−wj)Tx
则dij(x)>0等价于di(x)>dj(x),于是对每一类ωi均建立一个判别函数di(x),c类问题又c个判别函数
di(x)=wiTx,i=1,2,⋯,c
判别规则为:
di(x)>dj(x),∀j=i→x∈ωi
或者写为
di(x)=jmaxdj(x)→x∈ωi
判别函数值的鉴别意义
在n维特征空间中,特征矢量维x=(x1,x2,⋯,xn)T,线性判别函数的一般形式为
d(x)=w1x1+w2x2+⋯+wnxn+wn+1
此方程表示一超平面,它具有以下性质
- 系数矢量:w0=(w1,w2,⋯,wn)T是该平面的法矢量
- 判别函数d(x)的绝对值正比于x到超平面d(x)=0距离
- 判别函数值的正负表示出特征点位于那个半空间中
权空间
增广特征矢量与增广权矢量是对称的,判别函数可以写成
d(x)=wTx=xTw=x1w1+x2w2+⋯+xnwn+wn+1
这里x1,x2,⋯,xn,1则对应位相应的wi的权
- x指向平面xTw=0的正侧,则该半空间中任一点w都使xTw>0
- x背向平面xTw=0,则该半空间中任一点w都使xTw<0
解矢量
对于两类问题,在对待分类模式进行分类之前,应根据已知类别的增广训练模式,确认线性判别函数
d(x)wTx
- 当训练模式xj∈ω1→wTxj>0
- 当训练模式xj∈ω2→wTxj<0
此时的w称为解矢量,记为w∗,解矢量不是唯一的
可以把其中一类的符号转向,从而规范化为wTxj>0
解空间
n个训练模式将确定n个界面,每个界面都把权空间分为两个半空间,N个正的半子空间的交空间使以权空间原点为顶点的凸多面锥
满足上式的个不等式w比在这个锥体中,锥体中每个点都是不等式的解,解矢量不是唯一的,上面的凸多面锥包含了解的全体,称为解空间
Fisher线性判别
线性可分条件下判别函数权矢量算法
感知器算法:用训练模式检验初始的或迭代中的增广权矢量w的合理性,当不合理时,对其进行校正
实质:校正方法实际上时最优化技术中的梯度下降法,本算法也是人工神经网络理论中的线性阈值神经元的学习算法
graph TD
任选一初始增广权矢量-->用训练样本检验分类是否正确
用训练样本检验分类是否正确--正确-->所有训练样本都正确分类
用训练样本检验分类是否正确--不正确-->对权值进行校正
对权值进行校正-->所有训练样本都正确分类
所有训练样本都正确分类--否-->用训练样本检验分类是否正确
所有训练样本都正确分类--是-->结束
设给定一个增广的训练模式集{x1,x2,⋯,xn},其中每个模式类别已知,它们分别属于ω1类和ω2类
- 置步数k=1,令增量p=某正常数,分别赋给初始增广权矢量w(1)的各分量较小的任意值
- 输入训练模式xk,计算判别函数值wT(k)xk
- 调整增广权矢量
- 如果xk∈ω1和wT(k)xk≤0,则w(k+1)=w(k)+pxk
- 如果xk∈ω2和wT(k)xk≥0,则w(k+1)=w(k)−pxk
- 如果xk∈ω1和wT(k)xk>0,或xk∈ω2和wT(k)xk≤0,则w(k+1)=w(k)
- 如果k<N,令k+=1,返回2,如果k=N,检验判别函数对所有模式是否正常分量,若是则结束,若不是,令k=1,返回2
一般情况下的判别函数权矢量算法
如果线性不可分的情况,用线性分类的过程会不收敛
对线性不可分样本集,求一节矢量使得错分的模式数目最少
引入N维余量矢量b>ϕ,不等式方程组变为
Xw≥b>ϕ
其中
X=⎝⎜⎜⎜⎛x1Tx2T⋮xNT⎠⎟⎟⎟⎞
分段二次准则函数:
J(w)=∣∣(Xw−b)−∣Xw−b∣∣∣2
- 在训练模式线性可分的情况下:J(w∗=0)
- 在训练模式线性不可分的情况下:J(w∗>0)
令sk为寻求J(w)极小值点的搜索方向
则共轭梯度法的基本公式为
gks0βkvkwk+1=g(wk)=−ΔJ(wk)=g0sk+1=gkTgkgk+1Tgk+1=∣∣gk∣∣∣∣gk+1∣∣=J(w+vksk)=minJ(wk+vsk)=wk+vksk=gk+1+βksk
// TODO
非线性判别函数
设n维模式特征集在特征空间xn中是非线性可分的,对各模式作非线性变换
Tx:Xn→Ydd>n=(x1,x2,⋯,xn)Ty=(y1,y2,⋯,yn)T
其中yi=fi(x)是x的单值函数,选取适当的函数
fi(x)i=1,2,⋯,d
使
{yj=(f1(xj),f2(xj),⋯,fd(xj))}
在特征空间使线性可分的,称其维广义线性判别函数
// TODO
最近邻方法
- 聚类分析:无先验知识,按最近距离原则进行分类
- 代数界面方法:有先验知识,要进行训练,按判别函数值符号或大小进行分类
- 最近邻方法:有先验知识,但不进行训练,按最近距离原则进行分类
1-NN最近邻方法
- 已知N个已知类别样本X
- 输入未知类别样本X
- 计算x到所有样本距离
- 找出最小距离样本xm
- 判未知样本属于xm的一类
K-NN最近邻方法
- 已知N个已知类别样本X
- 输入未知类别样本X
- 计算x到所有样本距离
- 找出x的k个最小邻元xk,k=1,2,⋯,k
- 判未知样本属于最小邻元最多的一类
剪辑最近邻方法
对于两类问题,设将已知类别的样本集X(N)分成参照集X(NR)和测试集X(NT)两部分
利用参照集X(NR)中的样本采用最近邻规则对已知类别的测试集X(NT)中的每个样本进行分类,剪辑掉错误分类的样本,获得剪辑样本集XNTE后,对待识别模式x采用最近邻规则进行分类
剪辑最近邻法可以推广到K-近邻法中,具体做法:
- 用K-NN法进行剪辑
- 用1-NN法进行分类
如果样本足够多,可以重复执行剪辑程序,进一步提高性能,称为重复剪辑最近邻法
- 将样本集X(N)随机地划分为s个子集
- 用最近邻法,以X1+i为参照集,对Xi中的样本进行分类,其中i=1,2,⋯,s
- 去掉2.中被错误分类的样本
- 用所留下的样本构成新的样本集X(NE)
- 如果经过k次迭代再没有样本被剪辑掉则停止,否则转1.
统计判决
贝叶斯判决进行分类时,要求满足以下两个条件
- 各类别总体的概率分布是已知的
- 要判决的类别数是一定的
先验概率:识别系统预先已知或者可以估计的模型属于某种类型的概率
P(ωi)表示类ωi出现的先验概率,检测类ωi的概率
P(ω1)+P(ω2)+⋯+P(ωn)=1
类条件概率密度函数:模式样本x属于某类条件下出现的概率密度分布函数
P(x∣ω1)
后验概率:在某个具体的模式样本x条件下,该样本属于某种类型的概率。
P(ω1∣x)
对模式识别来说,可以理解为:x来自类ωi的概率
后验概率涉及一个具体事务,而先验概率是泛指一类事物
后验概率可由贝叶斯公式计算,作为分类判决的依据
贝叶斯公式
P(ωi∣x)=P(x)P(ωi)P(x∣ωi)
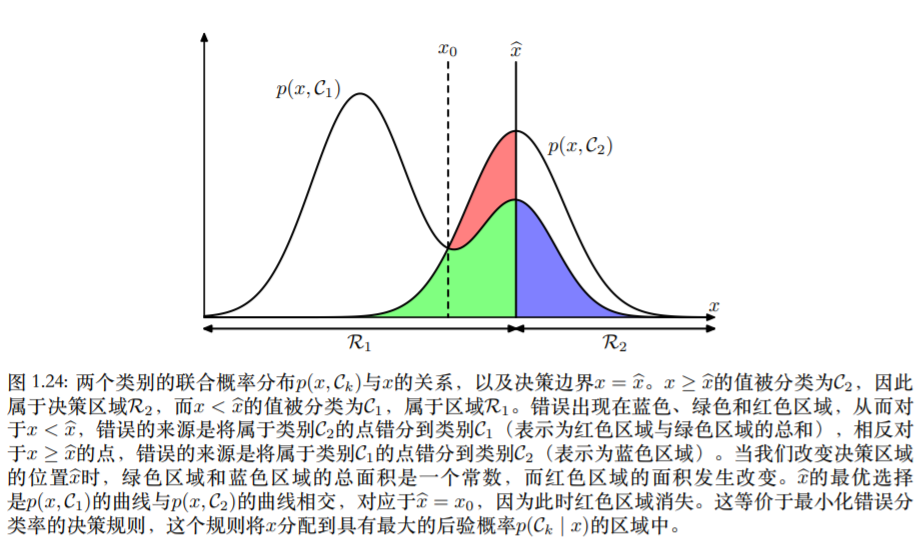
最小误判概率准则
对于两类ω1,ω2问题,直观地,可以根据后验概率做判决
P(ω1∣x)>P(ω2∣x)→x∈ω1P(ω1∣x)<P(ω2∣x)→x∈ω2
我们再知道它是x的前提下,属于哪个类的几率大就判给谁
P(x∣ω1)P(ω1)>P(x∣ω2)P(ω2)→x∈ω1P(x∣ω1)P(ω1)<P(x∣ω2)P(ω2)→x∈ω2
在ωi正确的情况下,谁属于x几率大就判给谁
l12=P(x∣ω2)P(x∣ω1)>P(ω1)P(ω2)=θ12→x∈ω1l12=P(x∣ω2)P(x∣ω1)<P(ω1)P(ω2)=θ12→x∈ω2
- 似然比:l12
- 判决阈值:θ12
因为是按照几率判定的,所以可以由错误,在两类问题中
ε12ε21=∫R1p(x∣ω1)dx=∫R2p(x∣ω2)dx
设ω1和ω2类出现的概率分别问P(ω1)和P(ω2),则总的误判概率是
P(e)=P(ω1)ε12+P(ω2)ε21=P(ω1)∫R1p(x∣ω1)dx+P(ω2)∫R2p(x∣ω2)dx
误判概率P(e)最小等价于使正确分类概率P(c)最大即
P(c)=max(∫R1P(ω1)p(x∣ω1)dx+∫R2P(ω2)p(x∣ω2)dx)
因为
∫R2P(ω2)p(x∣ω2)dx=P(ω2)−∫R1p(x∣ω2)dx
所以
P(c)=max(p(ω2)+∫R1[P(ω1)p(x∣ω1)−P(ω2)p(x∣ω2)]dx)
为了使P(c)最大,R1是R中所有满足条件
P(ω1)p(x∣ω1)>P(ω2)p(x∣ω2)
那些点x组成的集合
对于多类问题,最小误判概率准则有以下等价形式
- 后验概率形式
- 若P(ωi∣x)>P(ωj∣x),∀j=i,则判x∈ωi
- 若P(ωi∣x)=maxjP(ωj∣x),则判x∈ωj
- 条件概率形式
- 若P(x∣ωi)P(ωi)>P(x∣ωj)P(ωj),∀j=i,则判x∈ωi
- 若P(x∣ωi)P(ωi)=maxjP(x∣ωj)P(ωj),则判x∈ωj
- 似然比形式
- 若Iij(x)=p(x∣ωj)p(x∣ωi)>P(ωi)P(ωj),则判x∈ωi
- 条件概率的对数形式
- 如果lnp(x∣ωi)+lnP(ωi)>lnp(x∣ωj)+lnP(ωj),∀j=i,则判x∈ωi
正态模式最小误判概率判决规则
在c类问题中,属于ωi类的n维模式x的多变量正态分布密度函数为
p(x∣ω1)=(2π)n/2∣Σi∣1/21e−21(x−μi)TΣi−1(x−μi)
- 均值向量:μi=Ei(x)
- 协方差矩阵:Σi=Ei((x−μi)(x−μi)T)
ωi类的判决函数可以表示为
di(x)=p(x∣ωi)P(ωi)
写成对数形式
di(x)=lnP(ωi)−2nln(2π)−21ln∣Σi∣−21(x−μi)TΣi−1(x−μi)
去掉不影响结果项后
di(x)=lnP(ωi)−21ln∣Σi∣−21(x−μi)TΣi−1(x−μi)
判别规则:di(x)>dj(x)→x∈ωi
若各类概率相等,可继续化简为马氏距离的平方
di(x)=(x−μi)TΣ−1(x−μi)
- 当Σi=Σ
则判决函数可以变换为
di(x)=lnP(ωi)−21(x−μi)TΣi−1(x−μi)=lnP(ωi)−21xTΣ−1x+μTΣ−1x−21μTΣ−1μ
- 当Σi=Σ
这时一般的情况,ωi类模式的判决函数为
di(x)=lnP(ωi)−21ln∣Σi∣−21(x−μi)TΣi−1(x−μi)=−21xTΣi−1x+μiTΣ−1xi+lnP(ωi)−21ln∣Σi∣−21μiTΣi−1μi
相邻两类的决策平面是超平面:di(x)−dj(x)=0
最小损失准则判决
设Lij为本来是属于ωi类,但是判为ωj类的损失
把x判为ωi时的损失表示为
r(ωi∣x)=k=1∑KLikP(ωi∣x)
所以我们要选择损失最小的那一类
argminr(ωi∣x)
这个时候的损失为
r=E(r(x))=∫∑ωimin[r(ωi∣x)]p(x)dx=∫ω1(i=1∑KL1ip(x∣ω1)P(ω1))dx+∫ω2(i=1∑KL2ip(x∣ω2)P(ω2))dx⋮+∫ωk(i=1∑KLkip(x∣ωk)P(ωk))dx
参考