多元统计分析是同时考量多个变量,从多元数据集种获取信息的统计方法
多元随机变量
现有n个样本点,每个样本点包含p个变量的观测,则数据集课表示为n×p矩阵
Y=⎝⎜⎜⎜⎛y11y21⋮yn1y12y22⋮yn2⋯⋯⋱⋯y1py2p⋮ynp⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛y1Ty2T⋮ynT⎠⎟⎟⎟⎞
其中yi=(yi1,yi2,⋯,yip)由Y的第i行构成,表示第i个样本
均值向量
对于随机向量y=(yi1,yi2,⋯,yip)
μ=E[y]=y=⎣⎢⎢⎡E[y1]E[y2]⋯E[yn]⎦⎥⎥⎤=∫ynyp(y)dy
对于随机样本{y1,y2,⋯,yn}
yyi=n1i=1∑nyi=(y1,y2,⋯,yn)T=n1i=1∑n,E(y)=u
协方差矩阵
对随机变量y=(Y1,Y2,⋯,Yp)T,p×p的总体协方差矩阵为
Σ=Cov(y)=E[(y−μ)(y−μ)T]=⎝⎜⎜⎜⎛σ11σ21⋮σp1σ12σ22⋮σp2⋯⋯⋱⋯σ1pσ2p⋮σpp⎠⎟⎟⎟⎞
σjk为Yj和Yk之间的协方差
对随机样本{y1,y2,⋯,yn},p×p的样本协方差矩阵为
S=n−11i=1∑n(yi−y)(yi−y)T=⎝⎜⎜⎜⎛s11s21⋮sp1s12s22⋮sp2⋯⋯⋱⋯s1ps2p⋮spp⎠⎟⎟⎟⎞
其中sij=n−11∑i=1n(yij−yi)(yik−yk)
- Σ和S是对称的
- Σ是S的无偏估计
- y的协方差矩阵是Cov(y)=nΣ
总体相关系数矩阵
P=(pjk)=⎝⎜⎜⎜⎛1p21⋮pp1p121⋮pp2⋯⋯⋱⋯p1pp2p⋮1⎠⎟⎟⎟⎞
其中pjk=σjk/(σjσk)为Yi与Yj之间的总体相关系数
对随机样本{y1,y2,⋯,yn},样本相关系数矩阵为
R=(rjk)=⎝⎜⎜⎜⎛1r21⋮rp1r121⋮rp2⋯⋯⋱⋯r1pr2p⋮1⎠⎟⎟⎟⎞
其中rjk=sjk/sjjskk=sjk/(sjsk)为j与k个变量之间的样本相关系数
整体离散性
如果∣S∣很小,有可能是数据波动比较小,也可能是存在共线性现象,故∣S∣称为广义方程
tr(S)刻画了各变量波动程度的总和,但忽略了变量间的相关性,故称总方差
去相关化
使相关系数矩阵除对角线之外的值全部为0叫做去相关化
协方差矩阵Σ的特征值分别为
λ1,λ2,⋯,λp
对应特征向量为
s1,s2,⋯,sp
对Σ进行矩阵的对角化,见[线性代数] - 矩阵的分解总结
ΣΛ=SΛS=STΣS
对随机样本{y1,y2,⋯,yn},令Z=STY,则Cov(Z)为
Cov(Z)=Cov(STX)=E[(ST(X−μ))(ST(X−μ))T]=STE[(X−μ)(X−μ)T]S=STΣS=Σ
标准化
N(0,1)∼ΛST(X−μ)
欧式距离
- y1=(y11,y12,⋯,y1p)T
- y2=(y21,y22,⋯,y2p)T
∣∣y1−y2∣∣=i=1∑n(y1i−y2i)2
欧式距离没有考虑到不同变量变化的尺度不同,以及变量之间的相关性
马氏距离
(y1−y2)TS−1(y1−y2)
通过添加协方差矩阵的逆,方差更大的变量贡献更小的权重,两个高度相关的变量的贡献小于俩个相关较低的变量
马氏距离就是把向量经过标准化之后的欧式距离(S−1/2y1,S−1/2y2)
随机向量的变换
随机向量的分割
随机向量的分割
y=(Y1,Y2,⋯,Yp)T=(y(1)y(2))=(Y1Yq+1Y2Y2⋯⋯YqYp)
于是y的总体协方差矩阵可以分割为
Σ=((Σ11)q×q(Σ21)(p−q)×q(Σ12)q×(p−q)(Σ22)(p−q)×(p−q))
- Σ11:是y(1)的协方差矩阵
- Σ2:是y(2)的协方差矩阵
- Σ12=Σ21T:包含了所有y(1)和y(2)元素两两之间协方差的矩阵,通常记作Cov(y(1),y(2))
变量的线性组合
对y=(Y1,Y2,⋯,Yn)T的均值μ,协方差矩阵为Σ
Z=aTy=j=1∑pajYj
其中a=(a1,a2,⋯,ap)是系数向量
- E(Z)=E(aTy)=aTu
- var(Z)=var(aTy)=aTΣa
考虑2个线性组合
W=bTy=j=1∑pbjYj
- σZW=Cov(Z,W)=aTΣb
- ρZW=corr(Z,W)=(aTΣa)(bTΣb)aTΣb
考虑q个线性组合Y1,Y2,⋯,Yp的线性组合,记为z=Ay,A=(aij)q×p,则
μzΣz=E(Ay)=Aμ=Cov(z)=AΣAT
更一般地,对于w=Ay+b
μwΣw=E(Ay+b)=Aμ+b=Cov(w)=AΣAT
多元正态分布
若p维随机变量y=(Y1,Y2,⋯,Yn)T服从均值向量为μ,协方差矩阵为Σ的多元正态分布,记为y∼Np(μ,Σ),则密度函数为
f(y)=(2π)p/2∣Σ∣1/21e−2(y−μ)TΣ−1(y−μ)
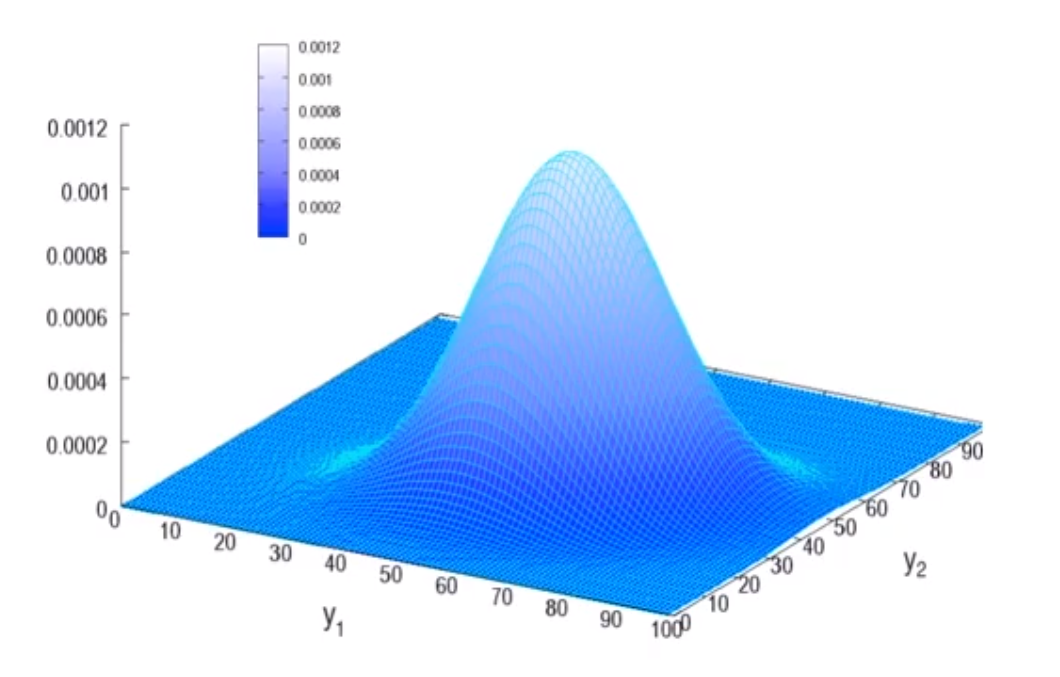
二元正态分布
p=2时,μ=(μ1μ2),Σ=(σ12ρ21σ1σ2ρ12σ1σ2σ22),所以随机向量y=(Y1,Y2)T服从二元正态分布,记为y∼BN(μ1,μ2,σ12,σ12,ρ12),密度函数为
f(y1,y2)=2πσ1σ2(1−ρ122)1exp[−2(1−ρ122)(σ1y1−y2)2+(σ2y2−μ2)2−2ρ12(σ1y1−μ1)(σ2y2−μ2)]
如果2元的正态的分布的两个变量的相关系数为0,可以得出2个变量是独立的

二元正态分布等高线
概率密度等高线可表示为
(σ1y1−y2)2+(σ2y2−μ2)2−2ρ12(σ1y1−μ1)(σ2y2−μ2)=c12
若它们相关系数为0,则
(c1σ1y1−y2)2+(c1σ2y2−μ2)2=1
以y1和y2为中心轴的椭圆
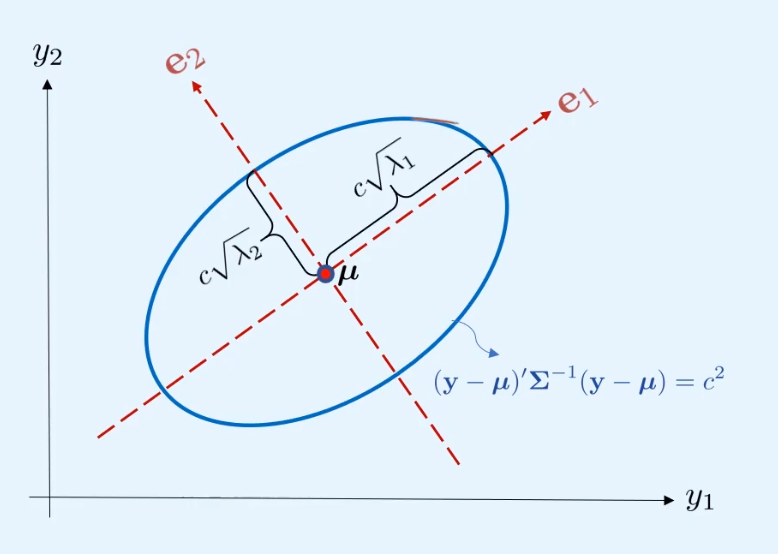
多元正态分布等高线
(y−μ)TΣ−1(y−μ)=c
通过矩阵的谱分解
Σ=j=1∑pλjejejT(λj,ej)为特征值-特征向量⇓Σ−1=j=1∑pλj1ejejT
代入原式后
j=1∑pc2λj(ejT(y−μ))2=1
多元正态分布性质
多元正态分布的线性组合
Z=aTy=j=1∑pajYj
如果y∼Np(μ,Σ),则aTy∼N(aTμ,aTΣa)
相对的,如果y中元素所有的线性组合都服从一元正态分布,则y一定是多元正态分布的
更一般地,假设A是一个q×p且秩为q(≤p)的常数矩阵,d为q维常数向量,如果y∼Np(μ,Σ),则
Ay+d∼Np(Aμ+d,AΣAT)
多元正态向量的分割
随机向量的分割
y=(Y1,Y2,⋯,Yp)T=(y(1)y(2))=(Y1Yr+1Y2Y2⋯⋯YrYp)
总体协方差矩阵可以分割为
Σ=((Σ11)r×r(Σ21)(p−r)×q(Σ12)r×(p−r)(Σ22)(p−r)×(p−r))
如果y∼Np(μ,Σ),则它的子向量也服从正态分布
y1y2∼Nr(μ1,Σ11)∼Np−r(μ2,Σ22)
特别的,y=(Y1,Y2,⋯,Yn)T的第j个元素服从一元正态分布
Yj∼N(μj,σjj)
多元正态向量的子向量条件分布
假设y∼Np(μ,Σ),并且∣Σ22∣>0,则对于其子向量y1和y2
y1∣y2∼Nr(μ1+Σ12Σ22−1(y2−μ2),Σ11−Σ12Σ22−1Σ21)
- 如果y是多元正态分布,则它的2个子向量有线性关系
- 回归系数矩阵:Σ12Σ22−1
- Cov(y1∣y2)不依赖y2
多元正态向量的独立性
考虑对于y,μ,Σ的分割,假设y∼Np(μ,Σ),则
- y1和y2独立当且仅当Σ12=0
- Yj和Yk独立当且仅当σjk=0
如果y1∼Nr(μ1,Σ11),y2∼Np(μ2,Σ22),且y1和y2相互独立,则
(y1y2)∼Nr+q[(μ1μ2),(Σ1100Σ22)]
多元正态向量的和
如果y与x相互独立,并且
yx∼Np(μy,Σyy)∼Np(μx,Σxx)
则它们的和或差仍然服从正态分布
y±x∼Np(μy±μx,Σyy+Σxx)
标准化多元正态向量
多元向量y的标准化向量定义为
z=(Σ)−1×(y−μ)z∼Np(0,I)
Σ=j=1∑pλjejejT⇓Σ=j=1∑pλjejejT
Σ=TT→TTT=Σ
多元正态向量的二次型
如果y∼Np(μ,Σ),则标准化向量z∼Np(0,I),则
zTz=j=1∑pZj2∼χ2(p)=(y−μ)TΣ−1(y−μ)
即(y−μ)TΣ−1(y−μ)∼χ2(p)
多元正态分布的估计
极大似然估计多元正态分布
当y∼Np(μ,Σ),对μ和Σ的估计通常由极大似然估计给出,给定独立同分布的n个样本y1,y2,⋯,yn∼Np(μ,Σ),其似然函数为
L(y1,y2,⋯,yn,μ,Σ)=i=1∏nf(yi,μ,Σ)=i=1∏n(2π)p/2∣Σ∣1/21e−2(y−μ)TΣ−1(y−μ)=(2π)np/2∣Σ∣n/21e−∑i=1n2(y−μ)TΣ−1(y−μ)
最大化似然函数L来得到μ和Σ的极大似然估计
step1. 确定分布律/分布函数P
step2. 计算L(p)=∏i=inP
step3. 计算lnL(p)
step4. 计算dpdlnL(p)=0,解出p
logL(y1,y2,⋯,yn,μ,Σ)=logi=1∏nf(yi,μ,Σ)=−2nlog∣Σ∣−21i=1∑n(yi−μ)TΣ−1(yi−μ)
我们先对μ进行极大化,对2次型求导为2倍的右边的部分
∂μ∂logL=0=i=1∑nΣ−1(yi−μ)⇓μ^=n1i=1∑nyi=y
现在对Σ做极大似然估计,带入上面得到的μ^
logL(y1,y2,⋯,yn,μ,Σ)=logi=1∏nf(yi,μ,Σ)=−2nlog∣Σ∣−21i=1∑n(yi−y)TΣ−1(yi−y)=−2nlog∣Σ∣−21i=1∑ntr(Σ−1(yi−y)(yi−y)T)=−2nlog∣Σ∣−21tr[Σ−1i=1∑n(yi−y)(yi−y)T]=−2nlog∣Σ∣−21tr(Σ−1S0)=2nlog∣Ω∣−21tr(ΩS0)
tr(AB)=tr(BA)
2nlog∣Ω∣−21tr(ΩS0)=2nlog∣ΩS0∣−21tr(ΩS0)−2nlog∣Ω∣
S0是已知值,假定λ1,λ2,⋯,λn为ΩS0的特征值,于是我们可以得到
2nlog∣Ω∣−21tr(ΩS0)=2nlogj=1∏pλj−21j=1∑pλj=21j=1∑p(nlogλj−λj)
现在实际上我们只需要对λj求极值即可,对每一个λj求偏导
∂λj∂logL=0=21(λjn−1)⇓λj=n
如果一个矩阵的所有特征值都相等,则为单位矩阵×n
ΩS0=n×Ip×p
则可算出Σ^
Σ^=n1S0=n1i=1∑n(yi−y)(yi−y)T
{μ^Σ^=n1∑i=1nyi=y=n1S0=n1∑i=1n(yi−y)(yi−y)T=nn−1S
S作为Σ的估计是无偏的,而Σ^是有偏的,所以样本协方差矩阵S在实际中更为常用
如果独立同分布多元样本{y1,y2,⋯,yn}来自Np(μ,Σ),则
- 样本均值向量:y=∑i=1nnyi的分布为:y∼N(μ,Σ/n)
- 样本协方差矩阵S=n−11∑i=1n(yi−μ)(yi−μ)T的分布为:(n−1)S∼Wp(n−1,Σ)
- 在正态分布假设下,y和S相互独立
Wishart分布
假设p维向量zi,i=1,2,⋯,q独立同分布且服从Np(0,Σ),则
i=1∑pziziT∼Wp(q,Σ)
假设p×p随机矩阵W1和W2分别服从分布Wp(q1,Σ),且Wp(q2,Σ)彼此独立,则
W1+W2∼Wp(q1+q2,Σ)
如果W∼Wp(q,Σ),C为k×p的常数矩阵,则有
CWCT∼Wk(q,CΣCT)
评估正态性
- 直方图
- QQ图
- 直线:正态
- 反S形:比正态重尾
- S形:比正态薄尾
- 凸弯形:右偏
- 凹弯形:左偏
- 偏度,峰度=(0,3)
拟合优度检验:检验数据是否来自一种特定的分布
H0H1:数据来自正态分布:数据不来自正态分布
Shapiro-Wilks检验
检验统计量:
W=∑i=1n(yi−y)2(∑i=1na(i)y(i))2
- y(i):第i个样本次序统计量
- a(i):标准正态分布中第i个标准化次序统计量
W可看作实际数据与正态数据之间的相关系数
- 当W=1时,数据为正态分布
- W显著小于1则表明数据非正态
Kolmogorov-Smirnov检验
D=nysup∣Fn(y)−F0(y)∣
- Fn(y):是数据的经验累积分布函数
- F0(y):是与数据同均值,同方差的正态分布的累积分布函数
结果
Cramer-von Miss检验
C=∫[Fn(y)−F0(y)]2dF0(y)
- Fn(y):是数据的经验累积分布函数
- F0(y):是与数据同均值,同方差的正态分布的累积分布函数
结果
Anderson-Darling检验
A=∫F0(y)(1−F0(y))[Fn(y)−F0(y)]2dF0(y)
相对于Cramer-von Miss检验给予尾巴上的数据更大的权重
多元数据的正态性
- 检验向量的每一维是否都是一元正态分布
- 检验是否成对散点图存在非线性趋势
- 构造χ2QQ图,检验统计距离{d1,d2,⋯,dn}是否距离χ2(p)很远
- 其中di(yi−y)TS−1(yi−y)
均值向量的检验
多元检验的动机
如果对每一维度分布进行一元检验,则每次一都a几率犯第一类错误。一元检验有时会降低统计功效,小的个体效应可能累积称为显著的联合效应,也就是说每个差异都很小,但是累积起来就会非常的大,导致多元检验下会拒绝原假设,但是一维检验全部接受
单样本均值向量检验
p维独立同分布的样本{y1,y2,⋯,yn}服从Np(μ,Σ)分布,其中
- 未知:μ
- 已知:Σ
待检验问题
H0H1:μ=μ0:μ=μ0
检验统计量:马氏距离(因为是向量)
Z2=n(y−μ0)TΣ−1(y−μ0)Cov(y)=Σ/n
统计量原假设分布
Z2=n(y−μ0)TΣ−1(y−μ0)∼χ2(p)p:样本维度
拒绝域
Z2>χa2(p)
因为数据来自二元,一元会忽略掉变量之间的关系,二元的假设检验的结论更加可信
p维独立同分布的样本{y1,y2,⋯,yn}服从Np(μ,Σ)分布,其中
- 未知:μ
- 未知:Σ
待检验问题
H0H1:μ=μ0:μ=μ0
检验统计量:Hotelling T平方检验统计量
把Σ替换为样本协方差矩阵
T2=n(y−μ0)TS−1(y−μ0)
统计量原假设分布:Hotelling T分布
T2∼T2(p,n−1){p:样本维度n:样本个数
拒绝域
T2>Ta2(p,n−1)
Hotelling T分布可以转化为F分布
p(n−1)n−pT2(p,n−1)=F(p,n−p)
两样本均值向量检验
独立两样本均值向量检验
假设群体1与群体2之间是独立的,假设
- y11,y12,⋯,y1n1 来自 N(μ1,Σ)
- y21,y22,⋯,y2n2 来自 N(μ2,Σ)
我们需要检验它们的均值是否相等
- 单边检验
- H0:μ1=μ2或μ1≤μ2
- H1:μ1>μ2
- 单边检验
- H0:μ1=μ2或μ1≥μ2
- H1:μ1<μ2
- 双边验
- H0:μ1=μ2
- H1:μ1=μ2
不知道μ就用y来估计它
检验统计量,若Cov(y1,y2)=Σ(n21+n21)协方差已知,则使用,否则用Spl来替代
T2Spl=n1+n2n1n2(y1−y2)TSpl−1(y1−y2)=n1+n2−2(n1−1)S1+(n2−1)S2
本质也是估计y1和y2的马氏距离
统计量原假设分布:
T2∼T2(p,n1+n2−2)
拒绝域
T2>Ta2(p,n1+n2−2)
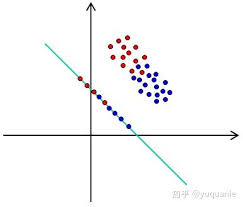
Fisher判别函数法可以用来寻找两个群体间"最好"的线性组合法则,来最大限度地区分两个群体
成对两样本均值向量检验
成对样本:群体1与群体2之间是成对的
- y11,y12,⋯,y1n1 来自 N(μ1,Σ)
- y21,y22,⋯,y2n2 来自 N(μ2,Σ)
由于是成对出现的,差异di=yi−xi独立同分布服从于Np(λ,Σd),其中λ=μy=μx
参数估计
- λ的估计:d=∑i=1ndi
- Σd的估计:Sd=n−1Σi=1n(di−d)(di−d)T
待检验问题
H0H1:λ=0:λ=0
检验统计量及其原假设分布
T2ndSd−1d∼T2(p,n−1)
拒绝域
T2>Ta2(p,n−1)
判别分析和分类分析
- 判别分析:寻找一种判别规则,利用变量的函数(判别函数)来描述,解释两组或多组群体间的区别
- 分类分析:预测一个新观察对象的类别-利用判别函数在新观测上的取值,找到该观测最有可能属于的类别
判别分析和分类分析中,所有个体有既定标签,即有:标准答案可供监督,所以为有监督学习
判别分析
| Fisher’s LDA |
贝叶斯法则 |
| 不需要分布假设 |
需要明确f(y1)和f(y2) |
| 需要同协方差矩阵假设 |
不要求同协方差矩阵假设 |
| 不可以考虑先验概率和误判代价 |
可以考虑先验概率和误判代价 |
两群体Fisher线性判别分析
用来寻找两个群体间"最好"的线性组合法则,来最大限度地区分两个群体
假设:
两个群体的均值向量μ1=μ2,但具有相同的协方差矩阵Σ
随机样本:
- y11,y12,⋯,y1n1
- 样本均值向量y1
- 协方差矩阵:Σ/n1
- y21,y22,⋯,y2n2
- 样本均值向量y2
- 协方差矩阵:Σ/n2
但是我们不需要看所有的点,而是让它们的样本均值投影后之间的距离最大,找到一个a方向,其中y1和y2在其的投影长度为Z1=aTy1和Z2=aTy2,我们需要找到一个a使得d=Z1−Z2最大,但是这是欧式距离,可能只是单纯的它本身比较大,所以需要寻找它们标准化后的距离的最大
Cov(y1−y2)=Σ(n11+n21)⇓var(d)=(n11+n21)aTΣasd=(n11+n21)aTSpla
得到我们最终要最大化的标准化距离
t2(a)=(sdd)2=(n11+n21)aTSpla(aT(y1−y2))2
Fisher线性判别分析寻找a使得t2(a)最大
柯西不等式
(aTb)2aTWa(aTb)2≤(aTa)(bTb)≤(aTWa)(bTW−1b)≤bTW−1b(=→a=W−1b)
所以为了使t2(a)最大,则
a=Spl−1(y1−y2)
称为判别函数系数
z=aTy
称为Fisher判别函数
多群体Fisher线性判别分析
现有g个群体Gk,k=1,2,⋯,g
- 第k个群体样本为:yk1,yk2,⋯,yknk
- 第k个群体样本容量为:nk
- 第k个群体样本均值为:yk
- s所有群体均值为y=1/g∑k=1gyk
目标函数:多群体“组间方差”和“组内方差”的比值为
aTW−1aaTBa=aT[∑k=1g∑i=1nk(yki−yk)(yki−yk)T]aaT[∑k=1g(yk−y)]a
将矩阵W−1B的非零特征值记为λ1,λ2,⋯,λs>0,其中s≤min(g−1,p),对应的特征向量为e1,e2,⋯,es,则a=e1为最大化的系数向量,对应最大值为λ1
- 样本第一判别式:线性组合e1Ty
- 样本第二判别式:线性组合e2Ty
- …
有多少e,就有多少判别式,最多g−1
分类分析
判别分析旨在寻找一种分类规则,而分类分析更进一步:将新观测对象分到一个合适的类别-即在分析过程中的预测部分
两群体Fisher分类
根据距离均值向量的距离大小进行分类
如果
(y1−y2)TSpl−1y0≥21(y1−y2)TSpl−1(y1+y2)
则将新观测对象y0分为类别G1,如果
(y1−y2)TSpl−1y0<21(y1−y2)TSpl−1(y1+y2)
则将新观测对象y0分为类别G2
Fisher分类实际是在比较新观测对象y0与y1,y2间的马氏距离
真实数据中,任何分类法则通常都不能完全正确地分类,可用以下表格计算总错分率
|
G1 |
G2 |
| G1 |
n11 |
×n12 |
| G2 |
×n21 |
n22 |
TPM=P(样本被分为G1实际上来自G2)+P(样本被分为G2实际上来自G1)=n11+n12+n21+n22n12+n21
两群体贝叶斯分类
G1和G2代表两个总体,各自的先验概率为p1和p2(p1+p2=1)
f1(y)和f2(y)分别是总体G1和G2中y的概率密度函数
记号:
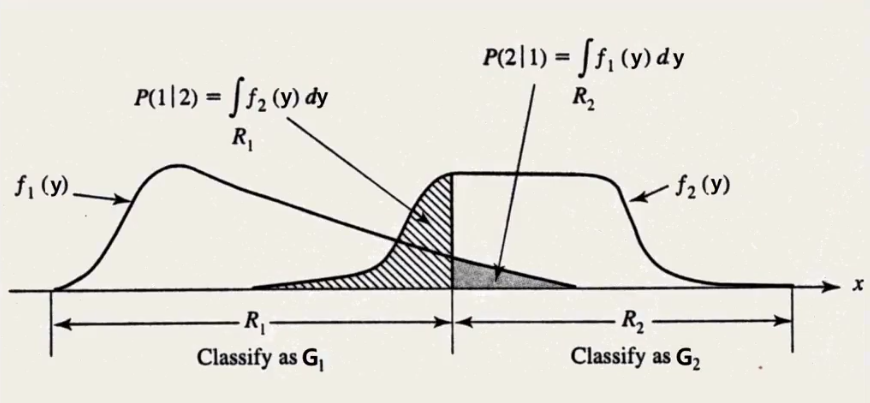
- R1和R2代表分类规则给出的分类区域,如果新观测对象属于Rk,我们说该对象来自Gk,k=1,2,R1,R2是整个空间的分割
- P(1∣2)是我们将对象y分为G1(y∈R1)然而实际上它来自G2的误判条件概率
P(1∣2)P(2∣1)=P(y∈R1∣G2)=∫R1f2(y)dy=P(y∈R2∣G1)=∫R2=Ω−R1f1(y)dy=1−∫R1f1(y)dy
错分率
P(观测对象被错分到G1)P(观测对象被错分到G2)=P(y∈R1∣G2)P(G2)=P(1∣2)p2=P(y∈R2∣G1)P(G1)=P(2∣1)p1
错分成本
记c(1∣2)为错误地将来自总体G2的观测对象y错分到G1的代价/成本,类似可定义c(2∣1)
|
G1 |
G2 |
| G1 |
0 |
c(2∣1) |
| G2 |
c(1∣2) |
0 |
贝叶斯分类法则目标是最小化错分的期望误判代价
ECM=c(2∣1)P(2∣1)p1+c(1∣2)P(1∣2)p2=c(2∣1)p1{1−∫R1f1(y)dy}+c(1∣2)p2∫R1f2(y)dy∝∫R1{f2(y)c(1∣2)p2−f1(y)c(2∣1)p1}d(y)
求得一个积分区域,要使积分下的有向面积最小,即R1包含积分项函数小于0的那些y
基于最小化ECM的思想
R1:f2(y)f1(y)≥c(2∣1)c(1∣2)p1p2R2:f1(y)f2(y)≥c(1∣2)c(2∣1)p2p1
特殊形式:p1p2=1(先验概率相同)
R1:f2(y)f1(y)≥c(2∣1)c(1∣2)R2:f1(y)f2(y)<c(2∣1)c(1∣2)
特殊形式:c(2∣1)c(1∣2)=1(错分成本相同)
R1:f2(y)f1(y)≥p1p2R2:f1(y)f2(y)<p1p2
特殊形式:p1p2=c(2∣1)c(1∣2)=1
R1:f2(y)f1(y)≥1R2:f1(y)f2(y)<1
当两群体来自具有相同协方差矩阵的正态分布Np(μ1,Σ)和Np(μ2,Σ)时,贝叶斯法则可表示为
(y1−y2)TS(pl)−1y0−21(y1−y2)TS(pl)−1(y1+y2)≥∈[c(2∣1)c(1∣2)p1p2]
当两群体具有相同协方差矩阵的正态分布时,贝叶斯法则的特殊情形等价于Fisher’s LDA分类法则
多群体Fisher分类
假设协方差矩阵相同,Fisher分类法则旨在比较新观测对象y0和均值yk,k=1,2,⋯,g之间的马氏距离
(y0−yk)TSpl−1(y0−yk)
并将其分到有最小距离的群体
多群体贝叶斯分类
多群体的误判代价较为复杂,因为要考虑g(g−1)组代价,因此我们假设相同的误判代价,即
R1:f2(y)f1(y)≥c(2∣1)c(1∣2)R2:f1(y)f2(y)<c(2∣1)c(1∣2)
将y0分到pkfk(y0)最大的那个组
- pk:先验概率
- fk(y0):密度函数
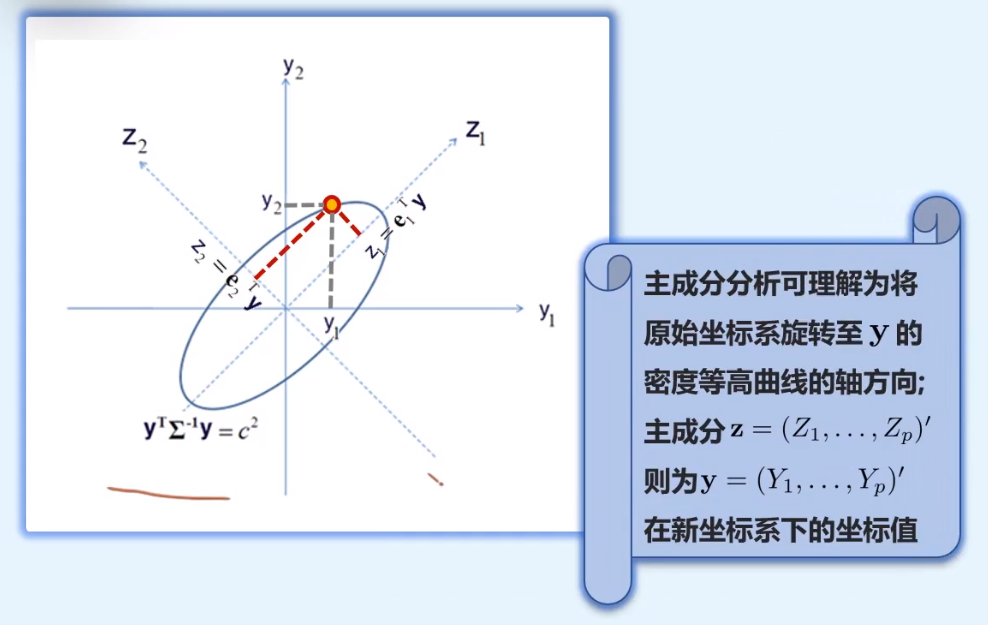
主成分分析
降维:用少数几个新的变量代替原有变量,合并重复信息,但不损失重要信息
主成分分析:在所有可能的Y1,Y2,⋯,Yp的线性组合模式中,寻找一个或几个可以最大程度区分数据的线性组合/加权平均
- LDA:线性判别分析寻求最大化两个或多个群体之间距离的线性组合
- PCA:主成分分析只有一个群体,找到能使这个群体中个体之间分的最开的变量组合
总体主成分推导
graph LR
原式变量--总体PCA-->主成分
- 线性组合
- 信息不重合
- 按重要性排序
- var(Z1),var(Z2),⋯,var(Zp)
记原式变量y=(Y1,Y2,⋯,Yp)T,其协方差矩阵为Σ
主成分分析试图定义一组互不相关的变量,称为Y1,Y2,⋯,Yp的主成分,记为Z1,Z2,⋯,Zp,每一个主成分都是Y1,Y2,⋯,Yp的线性组合
Z1Z2⋮Zp=a1Ty=a11Y1+a12Y2+⋯+a1pYp=a2Ty=a21Y1+a22Y2+⋯+a2pYp=apTy=ap1Y1+ap2Y2+⋯+appYp
则方差和协方差为
var(Zj)Cov(Zj,Zk)=var(ajTy)=aTΣaj=aTΣak
实际为求解a1,a2,⋯,ap使var(Zj)最大,Cov(Zj,Zk)为0
主成分Z1,Z2,⋯,Zp按照方差贡献度依次导出
- 第一主成分Z1=a1Ty在满足a1Ta1=1时(标准向量),最大化方差a1TΣa1
a1=0maxa1Ta1a1TΣa1
- 第二主成分Z2=a2Ty在满足a2Ta2=1时且a2TΣa1=0(信息不重合),最大化方差a2TΣa2
a2=0, a2TΣa1=0maxa2Ta2a2TΣa2
- 第j主成分Zj=ajTy在满足ajTaj=1时且ajTΣak=0(k=1,2,⋯,j−1)(信息不重合),最大化方差ajTΣaj
a2=0, ajTΣak=0maxa2Ta2a2TΣa2
- 第p主成分Zj=ajTy在满足apTap=1时,最小化方差ajTΣaj
ap=0minapTapapTΣap
记(λ1,e1),⋯,(λp,ep)为协方差矩阵Σ的特征值-特征向量,λ1≥λ2≥⋯≥λn≥0,并且特征向量为标准化特征向量,则变量Y1,Y2,⋯,Yp的第j个主成分由下式给出
Zj=ejTy=ej1Y1+ej2Y2+⋯+ejpYn,j=1,2,⋯,p
- 这里有var(Zj)=ejTΣej=λj
- 并且有Cov(Zj,Zk)=ejTΣek=0
- 进一步,还有
j=1∑pvar(Zj)=j=1∑pvar(Yj)
第k个主成分贡献的方差,占总体方差的比例可表示如下
∑j=1pλjλk,k=1,2,⋯,p
如果前几个主成分贡献大部分方差/信息(如80%),那么这些主成分能够以较少的信息损失来综合原始变量的信息,构成几个综合指标
总体主成分分析
如果变量y=(Y1,Y2,⋯,Yp)T的波动性(由于度量单位不同等原因)差距过大,直接由协方差矩阵Σ生成的主成分会由方差大的变量主导,这时我们可对每个变量分别进行标准化
Wj=σjjYj−μj⇓w=(W1,W2,⋯,Wp)T=DS−1(y−μ)Ds=diag(σ11,⋯,σpp)
Cov(w)=Ds−1ΣDs−1=ρ,对w做主成分分析就是在对y的相关系数矩阵做特征值和特征向量的分解(主成分分析)
记(λ1~,e1~),⋯,(λp~,ep~)为y的相关系数矩阵P的特征值-特征向量,λ1~≥λ2~≥⋯≥λn~≥0,并且特征向量为标准化特征向量,则y基于P的主成分分析等价于W1,W2,⋯,Wsp的第j个主成分由下式给出
Vj=e~jTw=e~j1W1+e~j2W2+⋯+e~jpWp,j=1,⋯,p
同时,我们也有
j=1∑pvar(Vj)=j=1∑pvar(Wj)=ρ
- 基于相关系数矩阵P的主成分分析不受度量单位影响
- P与Σ的特征值、特征向量不同,因此两组主成分的数值和方向均不同,一组主成分并不是另一组主成分的简单变换
- 如果变量数值差异很大,推荐进行标准化来获得一个较平衡的数据集
样本主成分分析
graph LR
原式数据矩阵--样本PCA-->主成分数据矩阵
样本主成分推导
y1,y2,⋯,yn表示n个p维随机样本,
- yi=(yi1,yi2,⋯,yip)T
- 样本均值向量:y
- 样本协方差矩阵:S
- 样本相关系数矩阵:R
记(λ1^,e1^),⋯,(λp^,ep^)为S的相关系数矩阵P的特征值-特征向量,则第i个样本得到的第j个主成分为
zij=e^jTyi=e^j1yi1+e^j2yi2+⋯+e^jpyip,j=1,2,⋯,pi=1,2,⋯,n
- szj2=e^jTSe^j=λ^j
- szjzk=e^jTSe^k=0
- j,k=1,2,⋯,p,j=k
记sjj为S的第j个对角元,那么有
样本总方差=j=1∑psjj=j=1∑pλ^j
总体主成分分析中,利用相关系数矩阵构造主成分的结论可以类似地推广到样本主成分分析
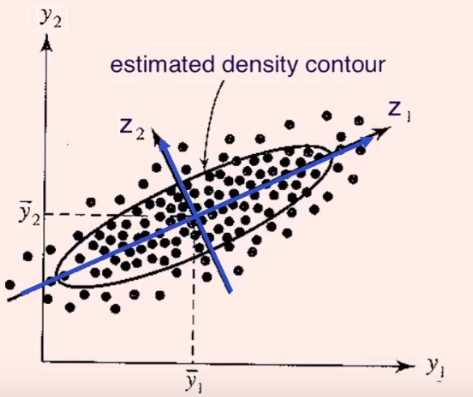
经过中心化的一系列主成分
zij=e^jT(yi−y),j=1,2,⋯,p,i=1,2,⋯,n
看作原理坐标系的原点平移到y,然后旋转坐标轴,使得坐标轴与数据最大方差方向一致
样本主成分个数的选择
- 百分比截点法:使用一定数目的主成分来反映足够比例(80%)的总方差
∑j=1pλj∑j=1kλj
- 平均截点:使用特征值大于平均特征值∑j=1pλ1/p的主成分
- 被广泛使用
- 当数据能够相对较小的维度下被很好地归纳时,特征值可以明显地分为“大特征值”和“小特征值”
- 碎石图:画出λj关于j的散点图,从图上寻找能区分“大特征值”和“小特征值”的分界点
因子分析
对于p个原始变量Y1,Y2,⋯,Yp来说,那些高度相关的变量很可能会遵循一个共同的潜在结构,称为公共因子
公共因子通常无法观测,故称为潜变量
因子分析旨在提出因子模型,来研究如何让用几个公共因子,记作F1,F2,⋯,Fm,通常m<p来刻画原始变量之间的相关性
| 因子分析 |
主成分分析 |
| 通常指是一种模型 |
不涉及模型 |
| 通过公共因子解释原始变量间的相关性 |
通过综合指标解释个体之间的差异性 |
| 原变量为因子的线性组合 |
主成分为原变量的线性组合 |
| 结果不唯一 |
结果唯一 |
单因子模型
Yj=ljF+εj
- 公共因子:F
- 特殊因子:εj
- 系数/载荷:lj
大多数时候需要多个因子来刻画:正交因子模型
正交因子模型
记随机向量y=(Y1,Y2,⋯,Yp)T的均值为μ,协方差矩阵为Σ,正交因子模型假定y线性依赖于m个不可观测公共因子f=(F1,F2,⋯,Fm)T和p个不可观测的特殊因子ε=(ε1,ε2,⋯,εp)T,通常m<p
Y1−μ1=l11F1+l12F2+⋯+l1mFm+ε1Y2−μ2=l21F1+l22F2+⋯+l2mFm+ε2⋮Yp−μp=lp1F1+lp2F2+⋯+lpmFm+εp
系数ljk称为第j个变量在第k个因子上的载荷,体现了该因子对此变量的解释力
yp×1−up×1=Lp×mfm×1+εp×1
其中f和ε假设满足
- 假设f是正交的:不相关
- 若2个公共因子有很强相关性,那么就可以合并为一个公共因子
- 假设ε的都是互不相关的
- 同时f和ε是无关的
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧E(f)Cov(f)E(ε)Cov(ε)Cov(ε,f)=0m×1=E(ffT)=I(m×m)=0p×1=E(εεT)=Ψp×p=⎣⎢⎢⎢⎡ψ10⋮00ψ2⋮0⋯⋯⋱⋯00⋮ψp⎦⎥⎥⎥⎤=0p×m
- 矩阵形式模型:y−u=Lf+ε
- 元素形式模型:Yj−μj=lj1F1+lj2F2+ljmFm+εj,j=1,⋯,p
Cov(y,f)=Cov(Lf+ε,f)=L
因此载荷ljk测度了第j个变量与第k个公共因子之间的关联Cov(Yj,Fk)=ljk
Σσ=Cov(y)=LLT+Ψ=var(Yj)=hj2+ψj,hj2=lj12+lj22+⋯+ljm2
- hj2体现了共同性,指由m个公共因子贡献的方差
- ψj称为唯一性或个体方差,指无法由公共因子贡献的方差部分
- σjjT=Cov(Yj,YjT)=lj1lj′1+⋯+ljmlj′m,j=j′
载荷估计方法
主成分法
y−u=Lf+ε
通过因子模型的协方差矩阵分解
Σ=Lp×mLp×mT+Ψ
利用谱分解
Σ=j=1∑pλjejejT=Λp×pΛp×pTΛ=(λ1e1,⋯,λpep)
当最后p−m个特征值很小的时候,我们可定义
L=(λ1e1,⋯,λpep)
则Σ=LLT,而Ψ可以补全Σ的对角线部分
Ψ=diag(ψ1,⋯,ψp),ψj=σjj−k=1∑mljk2,j=1,⋯,p
定理:(λ^j,e^j),j=1,2,⋯,p为样本协方差矩阵S的排序后标准化特征对,记m<p为公共因子的数目,那么因子载荷矩阵估计的主成分分解为
L^=(λ^1e^1λ^2e^2⋯λ^me^m)
个体方差的估计为S−L^L^T的对角元素,即Ψ^=diag(ψ^1,ψ^2,⋯,ψ^p)
- ψ^j=sjj−∑k=1ml^jk2
- 共同度:h^j2=l^j12+⋯+l^jm2
第k个因子的载荷估计与第k个主成分的系数成比例
S的对焦元素等于L^L^T+Ψ^的对角元素,然而,S的非对角元素通常不能由L^L^T+Ψ^完全复原
第k个因子对总方差s11+s22+⋯+spp=tr(S)的贡献为
j=1∑pl^jk2=λ^k
贡献比例
tr(S)λ^k,k=1,2,⋯,m
类似主成分分析,当变量的度量单位/量纲相差很多时,建议使用标准化后的变量进行因子分析,这等价于基于样本相关系数矩阵R使用主成分法,即将S换成R
确定m:参考主成分分析,评估被忽略的特征值的贡献,即可以使用百分比截点,平均截点和碎石图
还可以使用相关系数矩阵,把高度相关的变量分为一组为一个公共因子
主因子法
主成分方法中,忽略了Ψ,而主因子法。主轴法,则使用一个初始的估计值,从而对S−Ψ^(0)或R−Ψ^(0)使用与主成分方法相同的操作进行因子分析
我们可以迭代的更新估计值Ψ^(0)以及S−Ψ^(0)或R−Ψ^(0)的分解直到收敛
因为S−Ψ^(0)或R−Ψ^(0)可能不是正定的,这个方法有可能得到负的特征值,使结果较难解释
极大似然法
当样本f1,f2,⋯,fn和ε1,ε2,⋯,εn服从联合正态分布,y1,y2,⋯,yn也因此独立同分布的服从Np(μ,Σ)分布时(Σ=LLT+Ψ),Σ的似然函数可以如下表示
L(Σ)∝∣Σ∣−2nexp[−21tr{Σ−1(i=1∑n(yi−y)(yi−y)T)}]
其中μ^MLE=y已经带入上式,那么L和Ψ的极大似然估计可以通过迭代计算得到
估计因子得分
有时希望得到因子得分,f^i=(F^i1,F^i2,⋯,F^im),i=1,2,⋯,n,即每个因子在不同个体上的取值,从而可以:查看不同个体的因子表现情况
- 因子模型:yi−u=Lfi+εi
- 回归模型:y=Xβ+ε
- β^=(XTX)−1XTy
由于ε的方差不相同,我们可以通过加权最小二乘法来估计f:
f=(LTΨ−1L)−1LTΨ−1(y−μ)
将已估计的参数L^,Ψ^和μ^=y代入上式:
f^i=(L^TΨ^−1L^)−1L^TΨ^−1(yi−μ),i=1,2,⋯,n
回归法:基于正态假设
(y−μf)∼Np+m(0[Σ=LLT+ΨLTLI])
则f在给定y时的条件分布为正态分布,均值为
E(f∣y)=LTΣ−1(y−μ)
就可以得到第i个因子得分的估计
f^i=L^T(L^L^T+Ψ^)−1(yi−y)orf^i=L^TS−1(yi−y)
因子旋转
y−u=Lf+ε
以上因子模型等价于y−u=L∗f∗+ε
- L∗=LT
- f∗=TTf
- T→TTT=TTT=I
所以因子及其载荷矩阵并不唯一,可按照任意正交矩阵T提供的方向旋转,寻找使因子及载荷结构更简单,解释更清晰的旋转方向T
Y1−μ1=l11F1+l12F2+⋯+l1mFm+ε1Y2−μ2=l21F1+l22F2+⋯+l2mFm+ε2⋮Yp−μp=lp1F1+lp2F2+⋯+lpmFm+εp
- 载荷矩阵L代表原始变量和公共因子之间的关系
- 我们希望每个原始变量都由某个因子主要决定
- 对应载荷数值很大
- 对应其他因子关系不大,载荷数值很小
几何的角度,L^的第j行的载荷构成了原始变量Yj在因子/载荷空间的坐标
因子旋转的目标:让坐标轴靠近尽可能多的点(=0)
正交旋转
- 原来垂直的坐标轴经过旋转后仍保持垂直
- 角度和距离都保持不变
- 共同度不变
- 点的相对位置也维持原则
- 只有参考系改变了
我们选择一个角度ϕ来让坐标轴更加靠近点构成的聚类,新的选择载荷(l^j1∗,l^j2∗)可以通过图像测量出来,或者通过L^∗=LT得到,其中
T=(cosϕsinϕ−sinϕcosϕ)
对于维度大于2的情况,最常用的为最大方差法,也就是寻找能够最大化载荷矩阵中每一列载荷平方的方差的选择载荷
斜交旋转
- 不要求轴保持垂直
- 旋转更加自由
- 让更多的点靠近轴
- 共同度会变化
用非奇异变换矩阵Q来得到f∗=QTf,那么
Cov(f∗=QTIQ=QTQ=I)
因此新的因子之间使相关的,不是正交的
聚类分析
无监督学习的分类,类别和个数及个体标签本身并不存在,通过相似性进行合理的聚集
对于n个样本观测y1,y2,⋯,yn,可计算距离矩阵
D=(dij)dij=d(yi,yj)
层级聚类
凝聚法
由单个个体开始,逐步合并最“相似”的个体,直到所有个体都合并为一个群组
层次聚类过程的结果可以利用图表展示为系统树图,用来展示层次聚类的每一个步骤及其结果,包括合并族群带来的距离的变化
凝聚法每一步需要合并“距离最小的两个族群”,不同族群间距离的定义方法决定了不同的聚类结果
- 建立n个初始族群,每个族群中只有一个个体
- 计算n个族群间的距离矩阵
- 合并距离最小的两个矩阵,计算新族群间的距离矩阵
- 重复步骤3直到只有一个族群
- 绘制系统树图
连接法
简单连接
定义族群间的距离为两族群中相隔最近的两个个体间的距离
D(A,B)=min{d(yi,yj) for yi∈A AND yj∈B}
简单连接法存在“链式”问题,倾向于将新的个体归入已存在的族群,而不是创建新的族群
完全连接
定义族群间的距离为两族群中相隔最远的两个个体间的距离
D(A,B)=max{d(yi,yj) for yi∈A AND yj∈B}
平均连接
定义族群间的距离为nA个A集合点和nB个B集合点产生的所有nAnB个距离数值的平均
D(A,B)=nAnB1i=1∑nAj=1∑nBd(yi,yj)
质心连接
两族群的距离定义为两族群各自的质心,即样本均值向量之间的欧式距离
D(A,B)=d(yA,yB){yA=nA1=nA1∑i=1nAyiyB=nB1=nB1∑i=1nByi
合并后新的质心为
yAB=nA+nB∑i=1nAyi+∑j=1nByj=nA+nBnAyA+nByB
如果两个族群合并之后,下一步合并时的最小距离反而减小,这种情况称为倒置,在系统树图中表现为交叉现象
基于中心质心连接
合并后新的质心为,不要加权平均
mAB=21(yA+tB)
Ward法
由合并前后的族群内方差平方和的差异定义距离
IAB=SSEAB−(SSEA+SSEB)
SSEA=i=1∑nA(yi−yA)T(yi−yA) foryi∈ASSEB=i=1∑nB(yi−yB)T(yi−yB) foryi∈BSSEAB=i=1∑nA+nB(yi−yAB)T(yi−yAB) foryi∈AByAB=nA+nB(nAyA+nByB)
族群个数的选择
- 可根据经验或业务解释预先设定
- 也可由数据驱动:从系统树图中于给定距离水平下区分树图得到对应族群
- 通常寻找合并组别时较大的距离变化的节点
分离法
凝聚法的反方向
K-均值聚类
层次聚类有点类似弹性算法,已分配群体不能再分配
非层次聚类:分割法
K-均值法试图寻找k个族群(G1,G2,⋯,Gk)的划分方式,使得划分后的族群内方差(WGSS)最小
WGSS=l=i∑ki∈Gl∑j=1∑p(yij−yj(l))2=l=1∑ki∈Gl∑(yi−yi∈Gi(l))T(yi−yi∈Gi(l))
其中族群Gl中第j个变量的均值
yj(l)yiy(l)=i∈Gl∑niyij=(yi1,yi2,⋯,yip)T=(y1(l),y2(l),⋯,yp(l))T
- 选定k个种子作为初始族群代表
- 每个个体归入距离其最近的种子所在的族群
- 归类完成后,将新产生的族群的质心定位新的种子
- 重复步骤2和3,直到不需要再移动
用WGSS的碎石图来寻找最优的k,通常选取拐点为最优的k
选择初始种子
- 在相互间隔超过某指定最小距离的前提下,随机选择k个个体
- 选择数据集前k个相互间隔超过某指定最小距离个体
- 选择k个相互距离最远的个体
- 选择k个等距网格点,可能不是数据集的点
如果收敛速度极其缓慢或聚类结果每次都不同,可能数据原本就不存在族群
可以用层次聚类法聚类后,以各族群的质心作为k-均值法的初始种子
参考