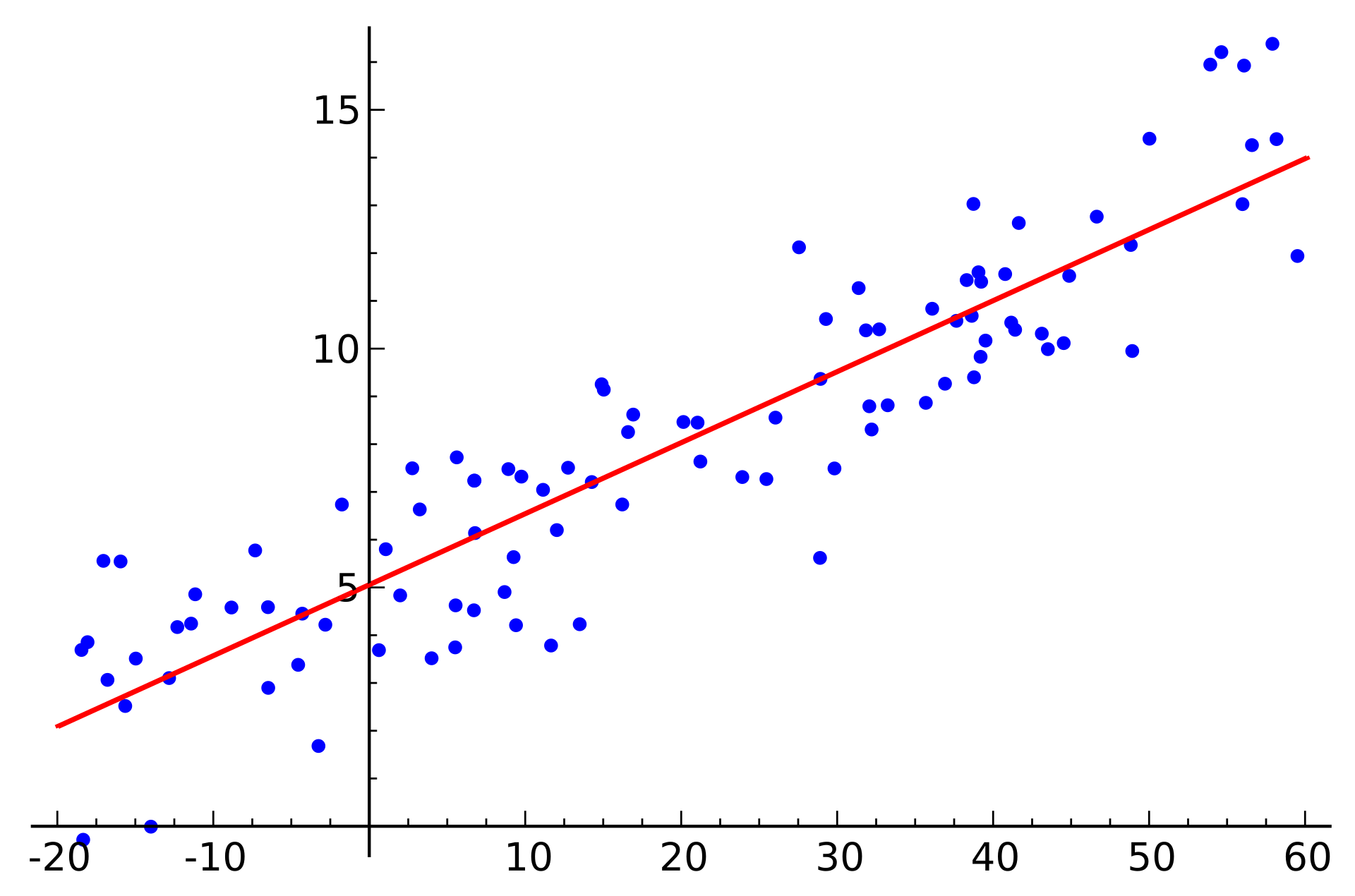
线性回归分析,可以通过一个已知的变量的值,进而推断一个未知的变量的确切的值。
我们对于x x x x 1 , x 2 , ⋯ , x n x_1, x_2, \cdots, x_n x 1 , x 2 , ⋯ , x n Y 1 , Y 2 , ⋯ , Y n Y_1, Y_2, \cdots, Y_n Y 1 , Y 2 , ⋯ , Y n x 1 , x 2 , ⋯ , x n x_1, x_2, \cdots, x_n x 1 , x 2 , ⋯ , x n Y Y Y
( x 1 , Y 1 ) , ( x 2 , Y 2 ) , ⋯ , ( x n , Y n ) (x_1, Y_1), (x_2, Y_2), \cdots, (x_n, Y_n)
( x 1 , Y 1 ) , ( x 2 , Y 2 ) , ⋯ , ( x n , Y n )
是一个样本,对应的样本值记为
( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n ) (x_1, y_1), (x_2, y_2), \cdots, (x_n, y_n)
( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n )
假设对于x x x
Y ∼ N ( a + b x , σ 2 ) Y \sim N(a + bx, \sigma^2)
Y ∼ N ( a + b x , σ 2 )
其中a , b a,b a , b σ 2 \sigma^2 σ 2 x x x ε = Y − ( a + b x ) \varepsilon = Y - (a + bx) ε = Y − ( a + b x ) Y Y Y
Y = a + b x + ε , ε ∼ N ( o , σ 2 ) Y = a + bx + \varepsilon, \quad \varepsilon \sim N(o, \sigma^2)
Y = a + b x + ε , ε ∼ N ( o , σ 2 )
其中未知参数a , b a, b a , b σ 2 \sigma^2 σ 2 x x x 一元线性回归模型 ,其中b b b 回归系数
取x x x n n n x 1 , x 2 , ⋯ , x n x_1, x_2, \cdots, x_n x 1 , x 2 , ⋯ , x n
( x 1 , Y 1 ) , ( x 2 , Y 2 ) , ⋯ , ( x n , Y n ) (x_1, Y_1), (x_2, Y_2), \cdots, (x_n, Y_n)
( x 1 , Y 1 ) , ( x 2 , Y 2 ) , ⋯ , ( x n , Y n )
由一元线性回归模型得到
Y i = a + b x i + ε i , ε i ∼ N ( o , σ 2 ) . 各 ε i 相互独立 Y_i = a + bx_i + \varepsilon_i, \quad \varepsilon_i \sim N(o, \sigma^2).\text{各}\varepsilon_i\text{相互独立}
Y i = a + b x i + ε i , ε i ∼ N ( o , σ 2 ) . 各 ε i 相互独立
于是得到Y i ∼ N ( a + b x i , σ 2 ) , i = 1 , 2 , ⋯ , n Y_i \sim N(a + bx_i, \sigma^2), i = 1, 2, \cdots, n Y i ∼ N ( a + b x i , σ 2 ) , i = 1 , 2 , ⋯ , n Y 1 , Y 2 , ⋯ , Y n Y_1, Y_2, \cdots, Y_n Y 1 , Y 2 , ⋯ , Y n Y 1 , Y 2 , ⋯ , Y n Y_1, Y_2, \cdots, Y_n Y 1 , Y 2 , ⋯ , Y n
L = ∏ i = 1 n 1 σ 2 π exp [ − 1 2 σ 2 ( y i − a − b x i ) ] = ( 1 σ 2 π ) n exp [ − 1 2 σ 2 ∑ i = 1 n ( y i − a − b x i ) ] \begin{aligned}
L &= \prod^n_{i=1}\frac{1}{\sigma \sqrt{2\pi}} \exp \Big[ -\frac{1}{2\sigma^2}(y_i - a -bx_i) \Big]
\\
&= (\frac{1}{\sigma \sqrt{2\pi}})^n \exp \Big[ -\frac{1}{2\sigma^2}\sum^n_{i=1}(y_i - a -bx_i) \Big]
\end{aligned}
L = i = 1 ∏ n σ 2 π 1 exp [ − 2 σ 2 1 ( y i − a − b x i ) ] = ( σ 2 π 1 ) n exp [ − 2 σ 2 1 i = 1 ∑ n ( y i − a − b x i ) ]
利用最大似然估计法来估计未知参数a , b a,b a , b y 1 , y 2 , ⋯ , y n y_1, y_2, \cdots, y_n y 1 , y 2 , ⋯ , y n L L L
min Q ( a , b ) = ∑ i = 1 n ( y i − a − b x i ) 2 \min \quad Q(a,b) = \sum^n_{i=1}(y_i - a -bx_i)^2
min Q ( a , b ) = i = 1 ∑ n ( y i − a − b x i ) 2
取Q Q Q a , b a,b a , b 0 0 0
{ ∂ Q ∂ a = − 2 ∑ i = 1 n ( y i − a − b x i ) = 0 ∂ Q ∂ b = − 2 ∑ i = 1 n ( y i − a − b x i ) x i = 0 \begin{cases}
\frac{\partial Q}{\partial a} &= -2 \sum^n_{i=1} (y_i - a - bx_i) = 0
\\
\frac{\partial Q}{\partial b} &= -2 \sum^n_{i=1} (y_i - a - bx_i)x_i = 0
\end{cases}
{ ∂ a ∂ Q ∂ b ∂ Q = − 2 ∑ i = 1 n ( y i − a − b x i ) = 0 = − 2 ∑ i = 1 n ( y i − a − b x i ) x i = 0
得到方程组
{ n a + ( ∑ i = 1 n x i ) b = ∑ i = 1 n y i ( ∑ i = 1 n x i ) a + ( ∑ i = 1 n x i 2 ) b = ∑ i = 1 n x i y i \begin{cases}
na + (\sum^n_{i=1}x_i)b = \sum^n_{i=1}y_i
\\
(\sum^n_{i=1}x_i)a + (\sum^n_{i=1}x^2_i)b = \sum^n_{i=1}x_iy_i
\end{cases}
{ n a + ( ∑ i = 1 n x i ) b = ∑ i = 1 n y i ( ∑ i = 1 n x i ) a + ( ∑ i = 1 n x i 2 ) b = ∑ i = 1 n x i y i
称上式为正规方程组 ,上述线性方程的行列式
∣ n ∑ i = 1 n x i ∑ i = 1 n x i ∑ i = 1 n x i 2 ∣ = n ∑ i = 1 n x i 2 − ( ∑ i = 1 n x i ) 2 = n ∑ i = 1 n ( x i − x ‾ ) 2 ≠ 0 \begin{vmatrix}
n & \sum^n_{i=1}x_i
\\
\sum^n_{i=1}x_i & \sum^n_{i=1}x^2_i
\end{vmatrix} = n\sum^n_{i=1}x^2_i - (\sum^n_{i=1}x_i)^2 = n\sum^n_{i=1}(x_i - \overline{x})^2 \neq 0
∣ ∣ ∣ ∣ n ∑ i = 1 n x i ∑ i = 1 n x i ∑ i = 1 n x i 2 ∣ ∣ ∣ ∣ = n i = 1 ∑ n x i 2 − ( i = 1 ∑ n x i ) 2 = n i = 1 ∑ n ( x i − x ) 2 = 0
故方程式由唯一的解,解得a , b a,b a , b
b ^ = n ∑ i = 1 n x i y i − ( ∑ i = 1 n x i ) ( ∑ i = 1 n y i ) n ∑ i = 1 n x i 2 − ( ∑ i = 1 n x i ) 2 = ∑ i = 1 n ( x i − x ‾ ) ( y i − y ‾ ) ∑ i = 1 n ( x i − x ‾ ) 2 a ^ = 1 n ∑ i = 1 n y i − b ^ n ∑ i = 1 n x i = y ‾ − b ^ x ‾ \begin{aligned}
\hat{b} &= \frac{n\sum^n_{i=1}x_iy_i - (\sum^n_{i=1}x_i)(\sum^n_{i=1}y_i)}{n\sum^n_{i=1}x^2_i - (\sum^n_{i=1}x_i)^2}
\\
&= \frac{\sum^n_{i=1}(x_i - \overline{x})(y_i - \overline{y})}{\sum^n_{i=1}(x_i - \overline{x})^2}
\\
\\
\hat{a} &= \frac{1}{n}\sum^n_{i=1}y_i - \frac{\hat{b}}{n} \sum^n_{i=1}x_i = \overline{y} - \hat{b}\overline{x}
\end{aligned}
b ^ a ^ = n ∑ i = 1 n x i 2 − ( ∑ i = 1 n x i ) 2 n ∑ i = 1 n x i y i − ( ∑ i = 1 n x i ) ( ∑ i = 1 n y i ) = ∑ i = 1 n ( x i − x ) 2 ∑ i = 1 n ( x i − x ) ( y i − y ) = n 1 i = 1 ∑ n y i − n b ^ i = 1 ∑ n x i = y − b ^ x
于是对于给定的x x x a ^ + b ^ x \hat{a} + \hat{b}x a ^ + b ^ x μ ( x ) = a + b x \mu(x) = a + bx μ ( x ) = a + b x
y ^ = a ^ + b ^ x \hat{y} = \hat{a} + \hat{b}x
y ^ = a ^ + b ^ x
称为Y Y Y x x x 经验回归方程 ,简称回归方程 ,其图形称为回归直线
引入下述记号
S x x = ∑ i = 1 n ( x i − x ‾ ) 2 S y y = ∑ i = 1 n ( y i − y ‾ ) 2 S x y = ∑ i = 1 n ( x i − x ‾ ) ( y i − y ‾ ) \begin{aligned}
S_{xx} &= \sum^n_{i=1}(x_i - \overline{x})^2
\\
S_{yy} &= \sum^n_{i=1}(y_i - \overline{y})^2
\\
S_{xy} &= \sum^n_{i=1}(x_i - \overline{x})(y_i - \overline{y})
\end{aligned}
S x x S y y S x y = i = 1 ∑ n ( x i − x ) 2 = i = 1 ∑ n ( y i − y ) 2 = i = 1 ∑ n ( x i − x ) ( y i − y )
a , b a,b a , b
b ^ = S x y S x x a ^ = 1 n ∑ i = 1 n y i − ( 1 n ∑ i = 1 n x i ) b ^ \begin{aligned}
\hat{b} &= \frac{S_{xy}}{S_{xx}}
\\
\hat{a} &= \frac{1}{n}\sum^n_{i=1}y_i - (\frac{1}{n}\sum^n_{i=1}x_i)\hat{b}
\end{aligned}
b ^ a ^ = S x x S x y = n 1 i = 1 ∑ n y i − ( n 1 i = 1 ∑ n x i ) b ^
变量y y y
离差 的大小可以用实际观测值y y y y ‾ \overline{y} y y − y ‾ y - \overline{y} y − y
∑ i = 1 n ( y i − y ‾ ) = 0 \sum^n_{i=1} (y_i - \overline{y}) = 0 ∑ i = 1 n ( y i − y ) = 0 ∑ i = 1 n x i ( y i − y ‾ ) = 0 \sum^n_{i=1} x_i(y_i - \overline{y}) = 0 ∑ i = 1 n x i ( y i − y ) = 0 x i x_i x i
对于n n n 总平方和 ,也叫总变差 ,记为SST,即
S S T = ∑ i = 1 n ( y i − y ‾ ) 2 SST = \sum^n_{i=1}(y_i - \overline{y})^2
S S T = i = 1 ∑ n ( y i − y ) 2
残差 的大小可以用实际观测值y y y y ^ \hat{y} y ^ e = y − y ^ e = y - \hat{y} e = y − y ^
E ( e ) = 0 E(e) = 0 E ( e ) = 0 C o v ( e , b ^ ) = 0 Cov(e, \hat{b}) = 0 C o v ( e , b ^ ) = 0 D ( e ) = σ 2 ( I − H ) D(e) = \sigma^2(I - H) D ( e ) = σ 2 ( I − H )
对于n n n 残差平方和 ,记为SSE,即
S S E = ∑ i = 1 n ( y i − y ^ i ) 2 SSE = \sum^n_{i=1}(y_i - \hat{y}_i)^2
S S E = i = 1 ∑ n ( y i − y ^ i ) 2
由上图,可以得出
y − y ‾ = ( y ^ − y ‾ ) + ( y − y ^ ) ⇓ ∑ i = 1 n ( y i − y ‾ ) 2 = ∑ i = 1 n ( y ^ i − y ‾ ) 2 + ∑ i = 1 n ( y i − y ^ i ) 2 + 2 ∑ i = 1 n ( y ^ i − y ‾ ) ( y i − y ^ i ) \begin{gathered}
y - \overline{y} = (\hat{y} - \overline{y}) + (y - \hat{y})
\\
\Downarrow
\\
\sum^n_{i=1}(y_i - \overline{y})^2 = \sum^n_{i=1}(\hat{y}_i - \overline{y})^2 + \sum^n_{i=1}(y_i - \hat{y}_i)^2 + 2\sum^n_{i=1}(\hat{y}_i - \overline{y})(y_i - \hat{y}_i)
\end{gathered}
y − y = ( y ^ − y ) + ( y − y ^ ) ⇓ i = 1 ∑ n ( y i − y ) 2 = i = 1 ∑ n ( y ^ i − y ) 2 + i = 1 ∑ n ( y i − y ^ i ) 2 + 2 i = 1 ∑ n ( y ^ i − y ) ( y i − y ^ i )
其中2 ∑ i = 1 n ( y ^ i − y ‾ ) ( y i − y ^ i ) = 0 2\sum^n_{i=1}(\hat{y}_i - \overline{y})(y_i - \hat{y}_i)= 0 2 ∑ i = 1 n ( y ^ i − y ) ( y i − y ^ i ) = 0
∑ i = 1 n ( y i − y ‾ ) 2 = ∑ i = 1 n ( y ^ i − y ‾ ) 2 + ∑ i = 1 n ( y i − y ^ i ) 2 \begin{aligned}
\sum^n_{i=1}(y_i - \overline{y})^2 &= \sum^n_{i=1}(\hat{y}_i - \overline{y})^2 + \sum^n_{i=1}(y_i - \hat{y}_i)^2
\end{aligned}
i = 1 ∑ n ( y i − y ) 2 = i = 1 ∑ n ( y ^ i − y ) 2 + i = 1 ∑ n ( y i − y ^ i ) 2
也就是
总平方和(SST) = 回归平方和(SSR) + 残差平方和(SSE) \begin{aligned}
\text{总平方和(SST)} &= \text{回归平方和(SSR)} + \text{残差平方和(SSE)}
\end{aligned}
总平方和( SST ) = 回归平方和( SSR ) + 残差平方和( SSE )
可以从图中看出,如果回归直线拟合较好,那么残差平方和(SSE)应该是比较低的,定义以下变量为决定系数 或判定系数 (coefficient of determination)
R 2 = 回归平方和 S S R 总平方和 S S T = 1 − 残差平方和 S S E 总平方和 S S T = ∑ i = 1 n ( y ^ i − y ‾ ) 2 ∑ i = 1 n ( y i − y ‾ ) 2 = 1 − ∑ i = 1 n ( y i − y ^ i ) 2 ∑ i = 1 n ( y i − y ‾ ) 2 \begin{aligned}
R^2 &= \frac{\text{回归平方和}SSR}{\text{\ \ \ \ 总平方和}SST} = 1 - \frac{\text{残差平方和}SSE}{\text{\ \ \ \ 总平方和}SST}
\\
&= \frac{\sum^n_{i=1}(\hat{y}_i - \overline{y})^2}{\sum^n_{i=1}(y_i - \overline{y})^2} = 1 - \frac{\sum^n_{i=1}(y_i - \hat{y}_i)^2}{\sum^n_{i=1}(y_i - \overline{y})^2}
\end{aligned}
R 2 = 总平方和 S S T 回归平方和 S S R = 1 − 总平方和 S S T 残差平方和 S S E = ∑ i = 1 n ( y i − y ) 2 ∑ i = 1 n ( y ^ i − y ) 2 = 1 − ∑ i = 1 n ( y i − y ) 2 ∑ i = 1 n ( y i − y ^ i ) 2
如果所有观测点都落在直线上,拟合是完全的,则R 2 = 1 R^2 = 1 R 2 = 1
如果y y y x x x y ^ = y ‾ \hat{y} = \overline{y} y ^ = y R 2 = 0 R^2 = 0 R 2 = 0
SSE代表了x x x
决定系数会随着自变量的增多,趋近于1 1 1 经调整决定系数 (Adjusted coefficient of determination)
R f 2 = 1 − ∑ i = 1 n ( y i − y ^ i ) 2 n − k − 1 ∑ i = 1 n ( y i − y ‾ ) 2 n − 1 R^2_f = 1 - \dfrac{\frac{\sum^n_{i=1}(y_i - \hat{y}_i)^2}{n - k - 1}}{\frac{\sum^n_{i=1}(y_i - \overline{y})^2}{n - 1}}
R f 2 = 1 − n − 1 ∑ i = 1 n ( y i − y ) 2 n − k − 1 ∑ i = 1 n ( y i − y ^ i ) 2
比较自变量数不同的回归模型的时候,使用调整决定系数
决定系数或调整决定系数越高,说明回归直线拟合越好
由
Y = a + b x + ε , ε ∼ N ( o , σ 2 ) Y = a + bx + \varepsilon, \quad \varepsilon \sim N(o, \sigma^2)
Y = a + b x + ε , ε ∼ N ( o , σ 2 )
得到
E [ ( Y − ( a + b x ) ) 2 ] = E [ ε 2 ] = D ( ε ) + E ( ε ) 2 = σ 2 E[(Y - (a + bx))^2] = E[\varepsilon^2] = D(\varepsilon) + E(\varepsilon)^2 = \sigma^2
E [ ( Y − ( a + b x ) ) 2 ] = E [ ε 2 ] = D ( ε ) + E ( ε ) 2 = σ 2
其表示σ 2 \sigma^2 σ 2 μ ( x ) = a + b x \mu(x) = a + bx μ ( x ) = a + b x Y Y Y μ ( x ) = a + b x \mu(x) = a + bx μ ( x ) = a + b x Y Y Y x x x 有效 ,不过一般情况下σ 2 \sigma^2 σ 2 σ 2 \sigma^2 σ 2
记x i x_i x i y i − y ^ i y_i - \hat{y}_i y i − y ^ i
y ^ i = y ^ ∣ x = x i = a ^ + b ^ x i \hat{y}_i = \hat{y}|_{x = x_i} = \hat{a} + \hat{b}x_i
y ^ i = y ^ ∣ x = x i = a ^ + b ^ x i
则残差平方和为
Q e = ∑ i = 1 n ( y i − y ^ i ) 2 = ∑ i = 1 n ( y i − a ^ − b ^ x i ) 2 \begin{aligned}
Q_e &= \sum^n_{i=1}(y_i - \hat{y}_i)^2
\\
&= \sum^n_{i=1}(y_i - \hat{a} - \hat{b}x_i)^2
\end{aligned}
Q e = i = 1 ∑ n ( y i − y ^ i ) 2 = i = 1 ∑ n ( y i − a ^ − b ^ x i ) 2
对Q e Q_e Q e
Q e = ∑ i = 1 n ( y i − y ^ i ) 2 = ∑ i = 1 n ( y i − y ‾ − b ^ ( x i − x ‾ ) ) 2 = ∑ i = 1 n ( y i − y ‾ ) 2 − 2 b ^ ∑ i = 1 n ( x i − x ‾ ) ( y i − y ‾ ) + b ^ 2 ∑ i = 1 n ( x − x ‾ ) 2 = S y y − 2 b ^ S x y + b ^ 2 S x x \begin{aligned}
Q_e &= \sum^n_{i=1}(y_i - \hat{y}_i)^2
\\
&= \sum^n_{i=1}(y_i - \overline{y} - \hat{b}(x_i - \overline{x}))^2
\\
&= \sum^n_{i=1}(y_i - \overline{y})^2 - 2\hat{b}\sum^n_{i=1}(x_i - \overline{x})(y_i - \overline{y}) + \hat{b}^2\sum^n_{i=1}(x - \overline{x})^2
\\
&= S_{yy} - 2\hat{b}S_{xy} + \hat{b}^2S_{xx}
\end{aligned}
Q e = i = 1 ∑ n ( y i − y ^ i ) 2 = i = 1 ∑ n ( y i − y − b ^ ( x i − x ) ) 2 = i = 1 ∑ n ( y i − y ) 2 − 2 b ^ i = 1 ∑ n ( x i − x ) ( y i − y ) + b ^ 2 i = 1 ∑ n ( x − x ) 2 = S y y − 2 b ^ S x y + b ^ 2 S x x
其中b ^ = S x y / S x x \hat{b} = S_{xy}/S_{xx} b ^ = S x y / S x x Q e Q_e Q e
Q e = S y y − b ^ S x y Q_e = S_{yy} - \hat{b}S_{xy}
Q e = S y y − b ^ S x y
对于上式的残差平方和的统计量Q e Q_e Q e y = Y y = Y y = Y
S Y Y = ∑ i = 1 n ( Y i − Y ‾ ) 2 S x Y = ∑ i = 1 n ( x i − x ‾ ) ( Y i − Y ‾ ) \begin{aligned}
S_{YY} &= \sum^n_{i=1}(Y_i - \overline{Y})^2
\\
S_{xY} &= \sum^n_{i=1}(x_i - \overline{x})(Y_i - \overline{Y})
\end{aligned}
S Y Y S x Y = i = 1 ∑ n ( Y i − Y ) 2 = i = 1 ∑ n ( x i − x ) ( Y i − Y )
则统计量Q e Q_e Q e
Q e = S Y Y − b ^ S x Y Q_e = S_{YY} - \hat{b}S_{xY}
Q e = S Y Y − b ^ S x Y
其服从χ 2 ( n − 2 ) \chi^2(n -2) χ 2 ( n − 2 )
Q e σ 2 ∼ χ 2 ( n − 2 ) \frac{Q_e}{\sigma^2} \sim \chi^2(n -2)
σ 2 Q e ∼ χ 2 ( n − 2 )
可以得到期望
E ( Q e σ 2 ) = n − 2 E(\frac{Q_e}{\sigma^2}) = n - 2
E ( σ 2 Q e ) = n − 2
于是从E ( Q e n − 2 ) = σ 2 E(\frac{Q_e}{n-2}) = \sigma^2 E ( n − 2 Q e ) = σ 2 σ 2 \sigma^2 σ 2
σ ^ 2 = Q e n − 2 = 1 n − 2 ( S Y Y − b ^ S x Y ) \hat{\sigma}^2 = \frac{Q_e}{n-2} = \frac{1}{n-2}(S_{YY} - \hat{b}S_{xY})
σ ^ 2 = n − 2 Q e = n − 2 1 ( S Y Y − b ^ S x Y )
我们都是假定Y Y Y x x x μ ( x ) \mu(x) μ ( x ) a + b a+b a + b μ ( x ) \mu(x) μ ( x ) x x x Y = a + b x + ε Y = a + bx + \varepsilon Y = a + b x + ε b b b 0 0 0 b = 0 b = 0 b = 0 E ( Y ) = μ ( x ) E(Y) = \mu(x) E ( Y ) = μ ( x ) x x x
H 0 : b = 0 H 1 : b ≠ 0 \begin{aligned}
H_0: \quad b = 0
\\
H_1: \quad b \neq 0
\end{aligned}
H 0 : b = 0 H 1 : b = 0
利用t t t
b ^ ∼ N ( b , σ 2 S x x ) \hat{b} \sim N(b, \frac{\sigma^2}{S_{xx}})
b ^ ∼ N ( b , S x x σ 2 )
由
{ Q e σ 2 ∼ χ 2 ( n − 2 ) σ ^ 2 = Q e n − 2 = 1 n − 2 ( S Y Y − b ^ S x Y ) ⇒ ( n − 2 ) σ ^ 2 σ 2 = Q e σ 2 ∼ χ 2 ( n − 2 ) \begin{cases}
\frac{Q_e}{\sigma^2} \sim \chi^2(n -2)
\\
\hat{\sigma}^2 = \frac{Q_e}{n-2} = \frac{1}{n-2}(S_{YY} - \hat{b}S_{xY})
\end{cases}\Rightarrow \frac{(n - 2)\hat{\sigma}^2}{\sigma^2} = \frac{Q_e}{\sigma^2} \sim \chi^2(n - 2)
{ σ 2 Q e ∼ χ 2 ( n − 2 ) σ ^ 2 = n − 2 Q e = n − 2 1 ( S Y Y − b ^ S x Y ) ⇒ σ 2 ( n − 2 ) σ ^ 2 = σ 2 Q e ∼ χ 2 ( n − 2 )
且b ^ \hat{b} b ^ Q e Q_e Q e
b ^ − b σ 2 S x x ( n − 2 ) σ ^ 2 σ n − 2 ∼ t ( n − 2 ) \frac{\frac{\hat{b} - b}{\sqrt{\frac{\sigma^2}{S_{xx}}}}}{\sqrt{\frac{\frac{(n - 2)\hat{\sigma}^2}{\sigma}}{n - 2}}} \sim t(n - 2)
n − 2 σ ( n − 2 ) σ ^ 2 S x x σ 2 b ^ − b ∼ t ( n − 2 )
也就是
b ^ − b σ ^ S x x ∼ t ( n − 2 ) , σ ^ = σ ^ 2 \frac{\hat{b} - b}{\hat{\sigma}} \sqrt{S_{xx}} \sim t(n - 2), \quad \hat{\sigma} = \sqrt{\hat{\sigma}^2}
σ ^ b ^ − b S x x ∼ t ( n − 2 ) , σ ^ = σ ^ 2
当H 0 H_0 H 0 b = 0 b = 0 b = 0 t t t
t = b ^ σ ^ S x x ∼ t ( n − 2 ) t = \frac{\hat{b}}{\hat{\sigma}}\sqrt{S_{xx}} \sim t(n - 2)
t = σ ^ b ^ S x x ∼ t ( n − 2 )
且E ( b ^ ) = b = 0 E(\hat{b}) = b = 0 E ( b ^ ) = b = 0 H 0 H_0 H 0
∣ t ∣ = ∣ b ^ ∣ σ ^ S x x ≥ t a / 2 ( n − 2 ) |t| = \frac{|\hat{b}|}{\hat{\sigma}}\sqrt{S_{xx}} \geq t_{a/2}(n - 2)
∣ t ∣ = σ ^ ∣ b ^ ∣ S x x ≥ t a / 2 ( n − 2 )
当假设H 0 : b = 0 H_0: b = 0 H 0 : b = 0 0 0 0
影响Y Y Y x x x
E ( Y ) E(Y) E ( Y ) x x x Y Y Y x x x
在实际中,我们还可能使用t t t P r ( > ∣ t ∣ ) Pr(>|t|) P r ( > ∣ t ∣ )
当回归效果显著时,可能需要对系数b b b b ^ − b σ ^ S x x ∼ t ( n − 2 ) \frac{\hat{b} - b}{\hat{\sigma}} \sqrt{S_{xx}} \sim t(n - 2) σ ^ b ^ − b S x x ∼ t ( n − 2 ) b b b 1 − a 1 - a 1 − a 1 − a 1 - a 1 − a
( b ^ ± t a / 2 ( n − 2 ) × σ ^ S x x ) (\hat{b} \pm t_{a/2}(n - 2) \times \frac{\hat{\sigma}}{\sqrt{S_{xx}}})
( b ^ ± t a / 2 ( n − 2 ) × S x x σ ^ )
Y = a e β x ⋅ ε , ln ε ∼ N ( 0 , σ 2 ) Y = ae^{\beta x} \cdot \varepsilon, \quad \ln \varepsilon \sim N(0,\sigma^2)
Y = a e β x ⋅ ε , ln ε ∼ N ( 0 , σ 2 )
其中a , β , σ 2 a, \beta, \sigma^2 a , β , σ 2 x x x
ln Y = ln a + β x + ln ε \ln Y = \ln a + \beta x + \ln \varepsilon
ln Y = ln a + β x + ln ε
令ln Y = Y ′ , ln a = a , β = b , x = x ′ , ln ε = ε ′ \ln Y = Y', \ln a = a, \beta = b, x = x', \ln \varepsilon = \varepsilon' ln Y = Y ′ , ln a = a , β = b , x = x ′ , ln ε = ε ′
Y ′ = a + b x ′ + ε ′ , ε ′ ∼ N ( 0 , σ 2 ) Y' = a + bx' + \varepsilon', \quad \varepsilon' \sim N(0, \sigma^2)
Y ′ = a + b x ′ + ε ′ , ε ′ ∼ N ( 0 , σ 2 )
Y = a x β ⋅ ε , ln ε ∼ N ( 0 , σ 2 ) Y = ax^\beta \cdot \varepsilon, \quad \ln \varepsilon \sim N(0, \sigma^2)
Y = a x β ⋅ ε , ln ε ∼ N ( 0 , σ 2 )
其中a , β , σ 2 a, \beta, \sigma^2 a , β , σ 2 x x x
ln Y = ln a + β ln x + ln ε \ln Y = \ln a + \beta \ln x + \ln \varepsilon
ln Y = ln a + β ln x + ln ε
令ln Y = Y ′ , ln a = a , β = b , ln x = x ′ , ln ε = ε ′ \ln Y = Y', \ln a = a, \beta = b, \ln x = x', \ln \varepsilon = \varepsilon' ln Y = Y ′ , ln a = a , β = b , ln x = x ′ , ln ε = ε ′
Y ′ = a + b x ′ + ε ′ , ε ′ ∼ N ( 0 , σ 2 ) Y' = a + bx' + \varepsilon', \quad \varepsilon' \sim N(0, \sigma^2)
Y ′ = a + b x ′ + ε ′ , ε ′ ∼ N ( 0 , σ 2 )
Y = a + β h ( x ) + ε , ε ∼ N ( 0 , σ 2 ) Y = a + \beta h(x) + \varepsilon, \quad \varepsilon \sim N(0,\sigma^2)
Y = a + β h ( x ) + ε , ε ∼ N ( 0 , σ 2 )
其中a , β , σ 2 a, \beta, \sigma^2 a , β , σ 2 x x x h ( x ) h(x) h ( x ) x x x a = a , β = b , h ( x ) = x ′ a = a, \beta = b, h(x) = x' a = a , β = b , h ( x ) = x ′
Y = a + b x ′ + ε , ε ′ ∼ N ( 0 , σ 2 ) Y = a + bx' + \varepsilon, \quad \varepsilon' \sim N(0, \sigma^2)
Y = a + b x ′ + ε , ε ′ ∼ N ( 0 , σ 2 )
上述得到Y Y Y x ′ x' x ′ x x x y y y x x x 曲线回归方程
假设回归模型为(R语言)
y = a + β 1 × R 1 + β 2 × log ( R 2 ) + 残差 y = a + \beta_1 \times R_1 + \beta_2 \times \log(R_2) + \text{残差}
y = a + β 1 × R 1 + β 2 × log ( R 2 ) + 残差
1 2 3 4 5 6 7 8 9 10 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -1.283e+03 1.137e+02 -11.278 1.39e-15 population -6.617e-02 1.046e-02 -6.326 5.87e-08 log(gdp) 1.757e+02 1.175e+01 14.959 < 2e-16 --- Residual standard error: 103.5 on 52 degrees of freedom Multiple R-squared: 0.821 Adjusted R-squared: 0.8141 F-statistic: 119.2 on 2 and 52 DF, p-value: < 2.2e-16
翻译过来即
1 2 3 4 5 6 7 8 9 10 计算结果: 参数估计列 参数的标准差 t value Pr(>|t|) (参数a的估计值) -1.283e+03 1.137e+02 -11.278 1.39e-15 population -6.617e-02 1.046e-02 -6.326 5.87e-08 log(gdp) 1.757e+02 1.175e+01 14.959 < 2e-16 --- 残差的标准差: 103.5 on 自由度: 52 决定系数: 0.821 经调整决定系数: 0.8141 F统计量: 119.2 自由度: (2, 52), p值: < 2.2e-16
Coefficients:表示参数估计的计算结果。Estimate:为参数估计列。Intercept行表示常数参数a的估计值 ,x行表示自变量x的参数b的估计值。Std. Error:为参数的标准差,sd(a), sd(b)t value:为t值,为T检验的值Pr(>|t|):表示P-value值,用于T检验判定,匹配显著性标记Residual standard error:表示残差的标准差,自由度为n-2Multiple R-squared:为相关系数R 2 R^2 R 2 Adjusted R-squared:为相关系数的修正系数,解决多元回归自变量越多,判定系数R 2 R^2 R 2 F-statistic:表示F统计量,自由度为( 1 , n − 2 ) (1, n-2) ( 1 , n − 2 ) p-value:用于F检验判定,匹配显著性标记
Pr(>|t|)如果小于0.05 0.05 0 . 0 5
实际问题中,随机变量Y Y Y x 1 , x 2 , ⋯ , x p , ( p > 1 ) x_1, x_2, \cdots, x_p,(p > 1) x 1 , x 2 , ⋯ , x p , ( p > 1 ) x 1 , x 2 , ⋯ , x p x_1, x_2, \cdots, x_p x 1 , x 2 , ⋯ , x p Y Y Y Y Y Y x 1 , x 2 , ⋯ , x p x_1, x_2, \cdots, x_p x 1 , x 2 , ⋯ , x p μ ( x 1 , x 2 , ⋯ , x p ) \mu(x_1, x_2, \cdots, x_p) μ ( x 1 , x 2 , ⋯ , x p ) x 1 , x 2 , ⋯ , x p x_1, x_2, \cdots, x_p x 1 , x 2 , ⋯ , x p
Y = b 0 + b 1 x 1 + ⋯ b p x p + ε , ε ∼ N ( 0 , σ 2 ) Y = b_0 + b_1x_1 + \cdots b_px_p + \varepsilon, \quad \varepsilon \sim N(0, \sigma^2)
Y = b 0 + b 1 x 1 + ⋯ b p x p + ε , ε ∼ N ( 0 , σ 2 )
其中b 0 , b 2 , ⋯ , b p , σ 2 b_0, b_2, \cdots, b_p, \sigma^2 b 0 , b 2 , ⋯ , b p , σ 2 x 1 , x 2 , ⋯ , x p x_1, x_2, \cdots, x_p x 1 , x 2 , ⋯ , x p
( x 11 , x 12 , ⋯ , x 1 p , y 1 ) ( x 21 , x 22 , ⋯ , x 2 p , y 2 ) ⋮ ( x n 1 , x n 2 , ⋯ , x n p , y n ) \begin{aligned}
(x_{11}, x_{12}, &\cdots, x_{1p}, y_1)
\\
(x_{21}, x_{22}, &\cdots, x_{2p}, y_2)
\\
&\vdots
\\
(x_{n1}, x_{n2}, &\cdots, x_{np}, y_n)
\end{aligned}
( x 1 1 , x 1 2 , ( x 2 1 , x 2 2 , ( x n 1 , x n 2 , ⋯ , x 1 p , y 1 ) ⋯ , x 2 p , y 2 ) ⋮ ⋯ , x n p , y n )
是一个样本,类似一元线性回归的情况,采用最大似然估计法来估计参数,取b ^ 0 , b ^ 1 , ⋯ , b ^ p \hat{b}_0, \hat{b}_1, \cdots, \hat{b}_p b ^ 0 , b ^ 1 , ⋯ , b ^ p b 0 = b ^ 0 , b 1 = b ^ 1 , ⋯ , b p = b ^ p b_0 = \hat{b}_0, b_1 = \hat{b}_1, \cdots, b_p = \hat{b}_p b 0 = b ^ 0 , b 1 = b ^ 1 , ⋯ , b p = b ^ p
Q = ∑ i = 1 n ( y i − b 0 − b 1 x i 1 − b 2 x i 2 − ⋯ − b p x i p ) 2 Q = \sum^n_{i=1}(y_i - b_0 - b_1x_{i1} - b_2x_{i2} - \cdots - b_px_{ip})^2
Q = i = 1 ∑ n ( y i − b 0 − b 1 x i 1 − b 2 x i 2 − ⋯ − b p x i p ) 2
达到最小,对Q Q Q b 0 , b 2 , ⋯ , b p b_0, b_2, \cdots, b_p b 0 , b 2 , ⋯ , b p
∂ Q ∂ b 0 = − 2 ∑ i = 1 n ( y i − b 0 − b 1 x i 1 − ⋯ − b p x i p ) = 0 ∂ Q ∂ b j = − 2 ∑ i = 1 n ( y i − b 0 − b 1 x i 1 − ⋯ − b p x i p ) x i j = 0 , j = 1 , 2 , ⋯ , p \begin{aligned}
\frac{\partial Q}{\partial b_0} &= -2 \sum^n_{i=1}(y_i - b_0 - b_1x_{i1} - \cdots - b_px_{ip}) = 0
\\
\frac{\partial Q}{\partial b_j} &= -2 \sum^n_{i=1}(y_i - b_0 - b_1x_{i1} - \cdots - b_px_{ip})x_{ij} = 0, \quad j = 1,2,\cdots,p
\end{aligned}
∂ b 0 ∂ Q ∂ b j ∂ Q = − 2 i = 1 ∑ n ( y i − b 0 − b 1 x i 1 − ⋯ − b p x i p ) = 0 = − 2 i = 1 ∑ n ( y i − b 0 − b 1 x i 1 − ⋯ − b p x i p ) x i j = 0 , j = 1 , 2 , ⋯ , p
化简后得到
b 0 n + b 1 ∑ i = 1 n x i 1 + b 2 ∑ i = 1 n x i 2 + ⋯ + b p ∑ i = 1 n x i p = ∑ i = 1 n y i b 0 ∑ i = 1 n x i 1 + b 1 ∑ i = 1 n x i 1 + b 2 ∑ i = 1 n x i 1 x i 2 + ⋯ + b p ∑ i = 1 n x i 1 x i p = ∑ i = 1 n x i 1 y i ⋮ b 0 ∑ i = 1 n x i p + b 1 ∑ i = 1 n x i p + b 2 ∑ i = 1 n x i p x i 2 + ⋯ + b p ∑ i = 1 n x i p x i p = ∑ i = 1 n x i p y i \begin{aligned}
b_0 n + b_1\sum^n_{i=1}x_{i1} + b_2\sum^n_{i=1}x_{i2} + \cdots + b_p\sum^n_{i=1}x_{ip} &= \sum^n_{i=1}y_i
\\
\\
b_0\sum^n_{i=1}x_{i1} + b_1\sum^n_{i=1}x_{i1} + b_2\sum^n_{i=1}x_{i1}x_{i2} + \cdots + b_p\sum^n_{i=1}x_{i1}x_{ip} &= \sum^n_{i=1}x_{i1}y_i
\\
\vdots
\\
b_0\sum^n_{i=1}x_{ip} + b_1\sum^n_{i=1}x_{ip} + b_2\sum^n_{i=1}x_{ip}x_{i2} + \cdots + b_p\sum^n_{i=1}x_{ip}x_{ip} &= \sum^n_{i=1}x_{ip}y_i
\end{aligned}
b 0 n + b 1 i = 1 ∑ n x i 1 + b 2 i = 1 ∑ n x i 2 + ⋯ + b p i = 1 ∑ n x i p b 0 i = 1 ∑ n x i 1 + b 1 i = 1 ∑ n x i 1 + b 2 i = 1 ∑ n x i 1 x i 2 + ⋯ + b p i = 1 ∑ n x i 1 x i p ⋮ b 0 i = 1 ∑ n x i p + b 1 i = 1 ∑ n x i p + b 2 i = 1 ∑ n x i p x i 2 + ⋯ + b p i = 1 ∑ n x i p x i p = i = 1 ∑ n y i = i = 1 ∑ n x i 1 y i = i = 1 ∑ n x i p y i
上式称为正规方程组 ,为了更方便的表达,将上式写作矩阵的形式
X = ( 1 x 11 x 12 ⋯ x 1 p 1 x 21 x 22 ⋯ x 2 p ⋮ ⋮ ⋮ ⋱ ⋮ 1 x n 1 x n 2 ⋯ x n p ) , Y = ( y 1 y 2 ⋮ y n ) , B = ( b 0 b 1 ⋮ b p ) X = \begin{pmatrix}
1 & x_{11} & x_{12} & \cdots & x_{1p}
\\
1 & x_{21} & x_{22} & \cdots & x_{2p}
\\
\vdots & \vdots & \vdots & \ddots &\vdots
\\
1 & x_{n1} & x_{n2} & \cdots & x_{np}
\end{pmatrix}, \quad Y = \begin{pmatrix}
y_1
\\
y_2
\\
\vdots
\\
y_n
\end{pmatrix}, \quad B = \begin{pmatrix}
b_0
\\
b_1
\\
\vdots
\\
b_p
\end{pmatrix}
X = ⎝ ⎜ ⎜ ⎜ ⎛ 1 1 ⋮ 1 x 1 1 x 2 1 ⋮ x n 1 x 1 2 x 2 2 ⋮ x n 2 ⋯ ⋯ ⋱ ⋯ x 1 p x 2 p ⋮ x n p ⎠ ⎟ ⎟ ⎟ ⎞ , Y = ⎝ ⎜ ⎜ ⎜ ⎛ y 1 y 2 ⋮ y n ⎠ ⎟ ⎟ ⎟ ⎞ , B = ⎝ ⎜ ⎜ ⎜ ⎛ b 0 b 1 ⋮ b p ⎠ ⎟ ⎟ ⎟ ⎞
即可化简为
X T X B = X T Y X^TXB = X^TY
X T X B = X T Y
即为正规方程式的矩阵形式,若X T X X^TX X T X
B ^ = ( b ^ 0 b ^ 1 ⋮ b ^ p ) = ( X T X ) − 1 X T Y \hat{B} = \begin{pmatrix}
\hat{b}_0
\\
\hat{b}_1
\\
\vdots
\\
\hat{b}_p
\end{pmatrix} = (X^TX)^{-1}X^TY
B ^ = ⎝ ⎜ ⎜ ⎜ ⎛ b ^ 0 b ^ 1 ⋮ b ^ p ⎠ ⎟ ⎟ ⎟ ⎞ = ( X T X ) − 1 X T Y
即为( b 0 , b 1 , ⋯ , b p ) T (b_0,b_1,\cdots,b_p)^T ( b 0 , b 1 , ⋯ , b p ) T
b ^ 0 + b ^ 1 x 1 + ⋯ + b ^ p x p \hat{b}_0 + \hat{b}_1x_1 + \cdots + \hat{b}_px_p
b ^ 0 + b ^ 1 x 1 + ⋯ + b ^ p x p
作为μ ( x 1 , x 2 , ⋯ , x n ) \mu(x_1, x_2, \cdots, x_n) μ ( x 1 , x 2 , ⋯ , x n )
y ^ = b ^ 0 + b ^ 1 x 1 + ⋯ + b ^ p x p \hat{y} = \hat{b}_0 + \hat{b}_1x_1 + \cdots + \hat{b}_px_p
y ^ = b ^ 0 + b ^ 1 x 1 + ⋯ + b ^ p x p
称为p p p 元经验线性回归方程 ,简称回归方程
类似一元线性回归,多元线性假设的显著性检验需要检验假设
H 0 : b 1 = b 2 = ⋯ = b p = 0 H 1 : b i ≠ 0 , i = 1 , 2 , ⋯ , p \begin{aligned}
H_0&: \quad b_1 = b_2 = \cdots = b_p = 0
\\
H_1&: \quad b_i \neq 0, \quad i =1,2,\cdots,p
\end{aligned}
H 0 H 1 : b 1 = b 2 = ⋯ = b p = 0 : b i = 0 , i = 1 , 2 , ⋯ , p
在实际问题中,与Y Y Y Y Y Y Y Y Y