复杂性理论 :发现了一个按照计算难度给问题分类的完美体系可计算性理论 :把问题分成可解和不可解自动机理论 :论述计算的数学模型和定义和性质
集合:是一组对象,把它作为一个整体。
子集 :A ⊆ B A \subseteq B A ⊆ B 真子集 :A ⊈ B A \nsubseteq B A ⊈ B 多重集合 :考虑元素出现的次数空集 :∅ \varnothing ∅
其他:
交集 :∩ \cap ∩ 并集 :∪ \cup ∪ 补集 :A ‾ \overline{A} A
序列 :把一些对象按照某种顺序 排列成一列又穷序列 :多元组 k k k 个元素的序列 :k元组 2元组 :有序对
设A , B A,\ B A , B A , B A,\ B A , B 笛卡尔积丨叉积 是第一个元素位A A A A × B A \times B A × B
k k k A 1 , A 2 , A 3 , ⋯ , A k A_1, A_2, A_3, \cdots, A_k A 1 , A 2 , A 3 , ⋯ , A k A 1 × A 2 × A 3 × ⋯ × A k A_1 \times A_2 \times A_3 \times \cdots \times A_k A 1 × A 2 × A 3 × ⋯ × A k ( a 1 , a 2 , ⋯ , a k ) (a_1, a_2, \cdots, a_k) ( a 1 , a 2 , ⋯ , a k ) a i ∈ A i a_i \in A_i a i ∈ A i 集合自身的笛卡尔积记作:A × A × ⋯ × A = A k A \times A \times \cdots \times A = A^k A × A × ⋯ × A = A k
函数建立一个输入-输出的关系,记作
f ( a ) = b f(a) = b
f ( a ) = b
函数又称作映射,并且若f ( a ) = b f(a) =b f ( a ) = b f f f a a a b b b
定义域 :函数所有可能的输入组成的集合值域 :函数的输出
f : D → R f: D \rightarrow R
f : D → R
k k k 元函数 :k k k 元数 :k k k 一元函数 :k = 1 k=1 k = 1 二元函数 :k = 2 k=2 k = 2
谓词或性质是值域伪True,False的函数。True,奇数时为False
一种特殊的二元 关系
R R R 自反的 ,集对每一个x x x x R y xRy x R y R R R 对称的 ,集对每一个x x x y y y x R y xRy x R y y R x yRx y R x R R R 传递的的 ,集对每一个x , y x, y x , y z z z x R y xRy x R y y R z yRz y R z x R z xRz x R z
无向图 又简称为图 :是一个点的集合和连接其中的某些点的线段
顶点 :图中的点边 :图中的边顶点的度数 :以这个顶点为端点的边的数目
概念:
子图 :如果图G G G H H H G G G H H H 路径 :由边连接的顶点序列简单路径 :没有顶点重复的路径简单圈 :只有最后一个点和第一个的重复的圈
用箭头代替线段
概念:
出度 :一个顶点引出的箭头数入度 :指向一个顶点的箭头数有向路径 :所有箭头的方向都与其前进的方向一致的路径强连通 :每一个顶点到另一个顶点都有一条有向路径
字母表 :任意一个又穷集合字母表的成员 :是该字母表的符号 ,记作Σ \Sigma Σ Γ \Gamma Γ
例:
Σ 1 = ∣ 0 , 1 ∣ \Sigma_1 = \begin{vmatrix}
0, & 1
\end{vmatrix}
Σ 1 = ∣ ∣ 0 , 1 ∣ ∣
Σ 1 = ∣ a , b , c , ⋯ , z ∣ \Sigma_1 = \begin{vmatrix}
a, & b, & c, & \cdots, & z
\end{vmatrix}
Σ 1 = ∣ ∣ a , b , c , ⋯ , z ∣ ∣
设Σ 1 = ∣ 0 , 1 ∣ \Sigma_1 = \begin{vmatrix}0, & 1\end{vmatrix} Σ 1 = ∣ ∣ 0 , 1 ∣ ∣ 01001是Σ 1 \Sigma_1 Σ 1 字符串
长度 :字符串包含的符号数空串 :长度为0的字符串反转 :按照相反的顺序写源字符串所得到的字符串,记作w R w^R w R 子串 :如果字符串z z z w w w z z z w w w 连结 :设x x x y y y y y y x x x 连结 ,记作x y xy x y 自身连结 :记作x k x^k x k k k k 字符串的字典序 :同字母表顺序
布尔逻辑是建立在两个值True和False的数学体系,True和False称为布尔值
运算:
或非NOT运算 :
¬ 1 = 0 \neg 1 = 0 ¬ 1 = 0 ¬ 0 = 1 \neg 0 = 1 ¬ 0 = 1
合并或AND运算 :∧ \wedge ∧ 析取或OR运算 :∨ \vee ∨
其他布尔运算:
异或或者XOR运算 :⊕ \oplus ⊕ 等值运算 :↔ \leftrightarrow ↔ 蕴涵运算 :→ \rightarrow →
AND,OR分配律:
P ∧ ( Q ∨ R ) = = ( P ∧ Q ) ∨ ( P ∧ R ) P \wedge (Q \vee R) == (P \wedge Q) \vee (P \wedge R) P ∧ ( Q ∨ R ) = = ( P ∧ Q ) ∨ ( P ∧ R ) P ∨ ( Q ∧ R ) = = ( P ∨ Q ) ∧ ( P ∨ R ) P \vee (Q \wedge R) == (P \vee Q) \wedge (P \vee R) P ∨ ( Q ∧ R ) = = ( P ∨ Q ) ∧ ( P ∨ R )
定义 :描述我们使用的对象和概念数学命题 :表述某一个对象具有某种心智证明 :一种逻辑定理 :被证明为帧的数学命题引理 :帮助我们证明其他更有意义命题的命题推论 :一个定理或它的证明可以使我们容易得出另外一些有关命题为真的结论
P P P Q Q Q P P P Q Q Q P ⇒ Q P \Rightarrow Q P ⇒ Q P P P Q Q Q Q Q Q P P P P ⇐ Q P \Leftarrow Q P ⇐ Q P P P Q Q Q P ⇔ Q P \Leftrightarrow Q P ⇔ Q
构造性证明
反证法
证明方法:假设这个定理为假,然后证明这个假设导致的一个明显错误的结论
归纳法:证明无穷集合的所有元素都有一种特定性质的高级方法
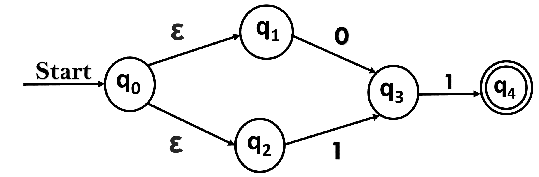
有穷自动机是关于储存量极其有限的计算机的很好的模型。
上图为M 1 M_1 M 1 状态图
状态 :q 1 , q 2 , q 3 q_1, q_2, q_3 q 1 , q 2 , q 3 起始状态 :q 1 q_1 q 1 接受状态 :q 2 q_2 q 2 转移 :一个状态指向另外一个状态的箭头
自动机从左至右一个接一个接受输入串的所有符号
读取到符号后,M 1 M_1 M 1
读取到最后一个符号后,M 1 M_1 M 1
有穷自动机是一个5元组(Q , Σ , δ , q 0 , F Q, \Sigma, \delta, q_0, F Q , Σ , δ , q 0 , F
Q Q Q 状态集 Σ \Sigma Σ 字母集 δ \delta δ Q × Σ → Q Q \times \Sigma \rightarrow Q Q × Σ → Q 转移函数 q 0 ∈ Q q_0 \in Q q 0 ∈ Q 起始状态 F ⊂ Q F \subset Q F ⊂ Q 接受状态集
设A A A A A A M M M L ( M ) = A L(M) = A L ( M ) = A M M M 识别 A A A M M M 接受 A A A
L ( M ) = A L(M) = A
L ( M ) = A
一台机器可能接受若干字符串,但是只能识别一个语言
如果机器不接受任何字符串,但它仍然识别一个语言:∅ \varnothing ∅
设M = ( Q , Σ , δ , q 0 , F ) M = (Q, \Sigma, \delta, q_0, F) M = ( Q , Σ , δ , q 0 , F ) w = w 1 w 2 ⋯ w n w=w_1w_2\cdots{}w_n w = w 1 w 2 ⋯ w n Σ \Sigma Σ Q Q Q r 0 , r 2 , ⋯ , r n r_0, r_2, \cdots, r_n r 0 , r 2 , ⋯ , r n
r 0 = q 0 r_0 = q_0 r 0 = q 0 δ ( r i , w i + 1 ) = r r + i , i = 0 , 1 , ⋯ , n − 1 \delta(r_i, w_{i+1}) = r_{r+i}, \quad i=0,1,\cdots,n-1 δ ( r i , w i + 1 ) = r r + i , i = 0 , 1 , ⋯ , n − 1 r n ∈ F r_n \in F r n ∈ F
则M M M w w w
如果A = { w ∣ M 接受 w } A = \lbrace w | M\text{接受}w \rbrace A = { w ∣ M 接受 w } M M M A A A 正则语言 :如果一个语言被一台有穷自动机识别,则称他是正则语言
确定型有穷自动机(DFA) :下一个状态是确定的非确定型有穷自动机(NFA) :下一个状态是不确定的
一个状态对于字母表中的每一个符号可能有0个,1个或多个射出的箭头
箭头可以标记字母表中的符号或ε \varepsilon ε 空字符串 )
遇到多种选择,机器将分裂(出一个备份),形成类似多线程
如果下一个输入符号不出现在她所处的状态射出的任何箭头上,此分支废弃
如果机器的某一个备份(分支)处于接受状态,则NFA接受输入串
如果遇到射出箭头有ε \varepsilon ε
每一个标记ε \varepsilon ε ε \varepsilon ε
有一个备份停留在当前状态
然后和之前一样的多线程的方式继续执行
在NFA在,转移函数取一个状态和一个输入符号,产生下一个状态的集合
引入形式符号P ( Q ) P(Q) P ( Q ) Q Q Q P ( Q ) P(Q) P ( Q ) 幂集
对于任意字母表Σ \Sigma Σ Σ ∪ { ε } \Sigma \cup \lbrace \varepsilon \rbrace Σ ∪ { ε } Σ ε \Sigma_\varepsilon Σ ε
转移函数:δ : Q × Σ ε → P ( Q ) \delta: Q \times \Sigma_\varepsilon \rightarrow P(Q) δ : Q × Σ ε → P ( Q )
非确定型有穷自动机是一个5元组(Q , Σ , δ , q 0 , F Q, \Sigma, \delta, q_0, F Q , Σ , δ , q 0 , F
Q Q Q 状态集 Σ \Sigma Σ 字母集 δ \delta δ Q × Σ ε → P ( Q ) Q \times \Sigma_\varepsilon \rightarrow P(Q) Q × Σ ε → P ( Q ) 转移函数 q 0 ∈ Q q_0 \in Q q 0 ∈ Q 起始状态 F ⊂ Q F \subset Q F ⊂ Q 接受状态集
设N = ( Q , Σ , δ , q 0 , F ) N = (Q, \Sigma, \delta, q_0, F) N = ( Q , Σ , δ , q 0 , F ) w = y 1 y 2 ⋯ y n w=y_1y_2\cdots{}y_n w = y 1 y 2 ⋯ y n Σ ε \Sigma_\varepsilon Σ ε Q Q Q r 0 , r 2 , ⋯ , r m r_0, r_2, \cdots, r_m r 0 , r 2 , ⋯ , r m
r 0 = q 0 r_0 = q_0 r 0 = q 0 r i + 1 ∈ δ ( r i , y i + 1 ) = r r + i , i = 0 , 1 , ⋯ , m − 1 r_{i+1} \in \delta(r_i, y_{i+1}) = r_{r+i}, \quad i=0,1,\cdots,m-1 r i + 1 ∈ δ ( r i , y i + 1 ) = r r + i , i = 0 , 1 , ⋯ , m − 1 r m ∈ F r_m \in F r m ∈ F
则N N N w w w
定理:确定型和非确定型有穷自动机识别相同的语言类,如果两台机器识别相同的语言,则称他们是等价 的
每一台非确定型有穷自动机都有一台等价的确定型有穷自动机
设k k k 2 k 2^k 2 k 2 k 2^k 2 k
设N = ( Q , Σ , δ , q 0 , F ) N = (Q, \Sigma, \delta, q_0, F) N = ( Q , Σ , δ , q 0 , F ) N N N ε \varepsilon ε
构造M = ( Q , Σ , δ , q 0 , F ) M = (Q, \Sigma, \delta, q_0, F) M = ( Q , Σ , δ , q 0 , F )
M M M N N N P ( Q ) P(Q) P ( Q ) Q Q Q
对于R ∈ Q ′ R \in Q' R ∈ Q ′ a ∈ Σ a \in \Sigma a ∈ Σ δ ′ ( R , a ) = { q ∈ Q } \delta'(R, a) = \lbrace q \in Q \rbrace δ ′ ( R , a ) = { q ∈ Q } r ∈ R r \in R r ∈ R q ∈ δ ( r , a ) q \in \delta(r, a) q ∈ δ ( r , a )
如果R R R M M M N N N
δ ′ ( R , a ) = ⋃ r ∈ R δ ( r , a ) \delta'(R, a) = \bigcup_{r \in R} \delta(r, a)
δ ′ ( R , a ) = r ∈ R ⋃ δ ( r , a )
q 0 ′ = { q 0 } q'_0 = \lbrace q_0 \rbrace q 0 ′ = { q 0 }
M M M N N N
F ′ = { R ∈ Q ′ ∣ R 包含N的一个接受状态 } F' = \lbrace R \in Q' | R \text{包含N的一个接受状态} \rbrace F ′ = { R ∈ Q ′ ∣ R 包含 N 的一个接受状态 }
考虑ε \varepsilon ε :M M M R R R E ( R ) E(R) E ( R ) R R R ε \varepsilon ε R R R R ⊆ Q R \subseteq Q R ⊆ Q
E ( R ) = { q ∣ 从 R 出发的沿着 0 个或多个 ε 箭头可以达到 q } E(R) = \lbrace q | \text{从}R\text{出发的沿着}0\text{个或多个}\varepsilon\text{箭头可以达到}q \rbrace
E ( R ) = { q ∣ 从 R 出发的沿着 0 个或多个 ε 箭头可以达到 q }
为了达到沿着ε \varepsilon ε E ( δ ( r , a ) ) E(\delta(r,a)) E ( δ ( r , a ) ) δ ( r , a ) \delta(r,a) δ ( r , a )
δ ′ ( R , a ) = { q ∈ Q ∣ ∃ r ∈ R → Q ∈ E ( δ ( r , a ) ) } \delta'(R, a) = \lbrace q \in Q | \exists r \in R \rightarrow Q \in E(\delta(r, a)) \rbrace
δ ′ ( R , a ) = { q ∈ Q ∣ ∃ r ∈ R → Q ∈ E ( δ ( r , a ) ) }
同时,对于起始状态,把q 0 ′ q_0' q 0 ′ E ( { q 0 } ) E(\lbrace q_0 \rbrace) E ( { q 0 } )
定理:一个语言时正则的,当且仅当有一台非确定型有穷自动机识别它
设k k k 2 k 2^k 2 k 2 k 2^k 2 k
{ ∅ , { 1 } , { 2 } , { 3 } , { 1 , 2 } , ⋯ } \lbrace \varnothing, \lbrace 1 \rbrace, \lbrace 2 \rbrace, \lbrace 3 \rbrace, \lbrace 1,2 \rbrace, \cdots \rbrace
{ ∅ , { 1 } , { 2 } , { 3 } , { 1 , 2 } , ⋯ }
接受状态集是DFA的所有包含接收状态的状态子集
确定DFA的转移函数
对于每一个字符串,遍历所有状态的输入和输出
状态x x x a a a y y y x → a { y } x \xrightarrow{\quad a \quad} \lbrace y \rbrace x a { y }
状态x x x a a a y , z y, z y , z x → a { y , z } x \xrightarrow{\quad a \quad} \lbrace y, z \rbrace x a { y , z }
状态x x x a a a x → a ∅ x \xrightarrow{\quad a \quad} \varnothing x a ∅
状态x x x a a a y y y y y y a a a z z z { x , y } → a { y , z } \lbrace x, y \rbrace \xrightarrow{\quad a \quad} \lbrace y, z \rbrace { x , y } a { y , z }
DFA中对于没有射入状态,可以删除进行简化
设A A A B B B
并 :A ∪ B = { x ∣ x ∈ A 或 x ∈ B } A \cup B = \lbrace x\ |\ x \in A \text{或} x \in B \rbrace A ∪ B = { x ∣ x ∈ A 或 x ∈ B } 连结 :A ∘ B = { x y ∣ x ∈ A 且 x ∈ B } A \circ B = \lbrace xy\ |\ x \in A \text{且} x \in B \rbrace A ∘ B = { x y ∣ x ∈ A 且 x ∈ B } 星号 :A ∗ = { x 1 x 2 ⋯ x k ∣ k ≥ 0 且每一个 x i ∈ A } A^* = \lbrace x_1x_2\cdots x_k\ |\ k \geq 0\text{且每一个}x_i \in A \rbrace A ∗ = { x 1 x 2 ⋯ x k ∣ k ≥ 0 且每一个 x i ∈ A }
定理:正则语言类在并运算下封闭
设N 1 N_1 N 1 A 1 A_1 A 1 N 2 N_2 N 2 A 2 A_2 A 2
N 1 = { Q 1 , Σ , δ 1 , q 1 , F 1 } N 2 = { Q 2 , Σ , δ 2 , q 2 , F 2 } \begin{aligned}
N_1 &= \{Q_1, \Sigma, \delta_1, q_1, F_1\}
\\
N_2 &= \{Q_2, \Sigma, \delta_2, q_2, F_2\}
\end{aligned}
N 1 N 2 = { Q 1 , Σ , δ 1 , q 1 , F 1 } = { Q 2 , Σ , δ 2 , q 2 , F 2 }
构造识别A 1 ∪ A 2 A_1 \cup A_2 A 1 ∪ A 2 N N N
N = ( Q , Σ , δ , q 0 , F ) N = (Q, \Sigma, \delta, q_0, F)
N = ( Q , Σ , δ , q 0 , F )
Q Q Q N 1 N_1 N 1 N 2 N_2 N 2 Q 1 ∪ Q 2 ∪ { q 0 } Q_1 \cup Q_2 \cup \lbrace q_0 \rbrace Q 1 ∪ Q 2 ∪ { q 0 }
q 0 q_0 q 0 N 1 N_1 N 1 N 2 N_2 N 2
q q q q 0 q_0 q 0 F F F F 1 ∪ F 2 F_1 \cup F_2 F 1 ∪ F 2 定义δ \delta δ q ∈ Q q \in Q q ∈ Q a ∈ Σ ε a \in \Sigma_\varepsilon a ∈ Σ ε
δ ( q , a ) = { δ 1 ( q , a ) , 若 q ∈ Q 1 δ 2 ( q , a ) , 若 q ∈ Q 2 { q 1 , q 2 } , 若 q = q 0 , 且 a = ε ∅ , 若 q = q 0 , 且 a ≠ ε \delta(q, a) = \begin{cases}
\delta_1(q,a), &\text{若}q \in Q_1
\\
\delta_2(q,a), &\text{若}q \in Q_2
\\
\lbrace q_1, q_2 \rbrace, &\text{若}q = q_0, \text{且} a = \varepsilon
\\
\varnothing, &\text{若}q = q_0, \text{且} a \neq \varepsilon
\end{cases}
δ ( q , a ) = ⎩ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎧ δ 1 ( q , a ) , δ 2 ( q , a ) , { q 1 , q 2 } , ∅ , 若 q ∈ Q 1 若 q ∈ Q 2 若 q = q 0 , 且 a = ε 若 q = q 0 , 且 a = ε
定理:正则语言类在连结运算下封闭
设两台NFA,N 1 N_1 N 1 A 1 A_1 A 1 N 2 N_2 N 2 A 2 A_2 A 2
N 1 = { Q 1 , Σ , δ 1 , q 1 , F 1 } N 2 = { Q 2 , Σ , δ 2 , q 2 , F 2 } \begin{aligned}
N_1 &= \{Q_1, \Sigma, \delta_1, q_1, F_1\}
\\
N_2 &= \{Q_2, \Sigma, \delta_2, q_2, F_2\}
\end{aligned}
N 1 N 2 = { Q 1 , Σ , δ 1 , q 1 , F 1 } = { Q 2 , Σ , δ 2 , q 2 , F 2 }
构造识别A ∘ B A \circ B A ∘ B N N N
N = { Q , Σ , δ , q , F } N = \{Q, \Sigma, \delta, q, F\}
N = { Q , Σ , δ , q , F }
Q Q Q N 1 N_1 N 1 N 2 N_2 N 2 Q 1 ∪ Q 2 Q_1 \cup Q_2 Q 1 ∪ Q 2 q q q N 1 N_1 N 1 q 1 q_1 q 1 F F F N 2 N_2 N 2 F 2 F_2 F 2 定义δ \delta δ q ∈ Q q \in Q q ∈ Q a ∈ Σ ε a \in \Sigma_\varepsilon a ∈ Σ ε
δ ( q , a ) = { δ 1 ( q , a ) , 若 q ∈ Q 1 , 且 q ∉ F 1 δ 1 ( q , a ) , 若 q ∈ F 1 , 且 a ≠ ε δ 1 ( q , a ) ∪ { q 2 } , 若 q ∈ F 1 , 且 a = ε δ 2 ( q , a ) , 若 q ∈ Q 2 \delta(q, a) = \begin{cases}
\delta_1(q,a), &\text{若}q \in Q_1, \text{且}q \notin F_1
\\
\delta_1(q,a), &\text{若}q \in F_1, \text{且}a \neq \varepsilon
\\
\delta_1(q,a) \cup \lbrace q_2 \rbrace, &\text{若}q \in F_1, \text{且}a = \varepsilon
\\
\delta_2(q,a), &\text{若}q \in Q_2
\end{cases}
δ ( q , a ) = ⎩ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎧ δ 1 ( q , a ) , δ 1 ( q , a ) , δ 1 ( q , a ) ∪ { q 2 } , δ 2 ( q , a ) , 若 q ∈ Q 1 , 且 q ∈ / F 1 若 q ∈ F 1 , 且 a = ε 若 q ∈ F 1 , 且 a = ε 若 q ∈ Q 2
定理:正则语言类在星号运算下封闭
设N 1 = ( Q 1 , Σ , δ 1 , q 1 , F 1 ) N_1 = (Q_1, \Sigma, \delta_1, q_1, F_1) N 1 = ( Q 1 , Σ , δ 1 , q 1 , F 1 ) A 1 A_1 A 1 A ∗ A^* A ∗ N = ( Q , Σ , δ , q 0 , F ) N=(Q, \Sigma, \delta, q_0, F) N = ( Q , Σ , δ , q 0 , F )
Q Q Q Q 1 ∪ { q 0 } Q_1 \cup \lbrace q_0 \rbrace Q 1 ∪ { q 0 } q q q q 0 q_0 q 0 F F F { q 0 } ∪ F 1 \lbrace q_0 \rbrace \cup F_1 { q 0 } ∪ F 1 定义δ \delta δ q ∈ Q q \in Q q ∈ Q a ∈ Σ ε a \in \Sigma_\varepsilon a ∈ Σ ε
δ ( q , a ) = { δ 1 ( q , a ) , 若 q ∈ Q 1 , 且 q ∉ F 1 δ 1 ( q , a ) , 若 q ∈ F 1 , 且 a ≠ ε δ 1 ( q , a ) ∪ { q 1 } , 若 q ∈ F 1 , 且 a = ε { q 1 } , 若 q = q 0 , 且 a = ε ∅ , 若 q = q 0 , 且 a ≠ ε \delta(q, a) = \begin{cases}
\delta_1(q,a), &\text{若}q \in Q_1, \text{且}q \notin F_1
\\
\delta_1(q,a), &\text{若}q \in F_1, \text{且}a \neq \varepsilon
\\
\delta_1(q,a) \cup \lbrace q_1 \rbrace, &\text{若}q \in F_1, \text{且}a = \varepsilon
\\
\lbrace q_1 \rbrace, &\text{若}q = q_0, \text{且}a = \varepsilon
\\
\varnothing, &\text{若}q = q_0, \text{且}a \neq \varepsilon
\end{cases}
δ ( q , a ) = ⎩ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎧ δ 1 ( q , a ) , δ 1 ( q , a ) , δ 1 ( q , a ) ∪ { q 1 } , { q 1 } , ∅ , 若 q ∈ Q 1 , 且 q ∈ / F 1 若 q ∈ F 1 , 且 a = ε 若 q ∈ F 1 , 且 a = ε 若 q = q 0 , 且 a = ε 若 q = q 0 , 且 a = ε
利用正则运算符构造描述语言的表达式,称作正则表达式 ,例如
( 0 ∪ 1 ) 0 ∗ = ( 0 ∪ 1 ) ∘ 0 ∗ \begin{aligned}
(0 \cup 1)& 0^*
\\
= (0 \cup 1)& \circ 0^*
\end{aligned}
( 0 ∪ 1 ) = ( 0 ∪ 1 ) 0 ∗ ∘ 0 ∗
Σ \Sigma Σ Σ ∗ \Sigma^* Σ ∗ Σ ∗ 1 \Sigma^*1 Σ ∗ 1 1 1 1 ( 0 Σ ∗ ) ∪ ( Σ ∗ 1 ) (0 \Sigma^*)\cup(\Sigma^*1) ( 0 Σ ∗ ) ∪ ( Σ ∗ 1 ) 0 0 0 1 1 1
a ∪ a = a a \cup a = a a ∪ a = a a ∪ b = b ∪ a a \cup b = b \cup a a ∪ b = b ∪ a a ∗ = a ∗ a ∗ = ( a ∗ ) ∗ = a ∪ a ∗ a^* = a^*a^* = (a^*)^* = a \cup a^* a ∗ = a ∗ a ∗ = ( a ∗ ) ∗ = a ∪ a ∗ a ∗ = ε ∪ a ∗ = ε ∪ a a ∗ = ( ε ∪ a ) ∗ a^* = \varepsilon \cup a^* = \varepsilon \cup aa^* = (\varepsilon \cup a)^* a ∗ = ε ∪ a ∗ = ε ∪ a a ∗ = ( ε ∪ a ) ∗ ( a ∪ b ) ∗ = ( b ∪ a ) ∗ (a \cup b)^* = (b \cup a)^* ( a ∪ b ) ∗ = ( b ∪ a ) ∗ ( a ∪ b ) ∗ = ( a ∗ ∪ b ∗ ) ∗ = ( a ∗ b ∗ ) ∗ (a \cup b)^* = (a^* \cup b^*)^* = (a^*b^*)^* ( a ∪ b ) ∗ = ( a ∗ ∪ b ∗ ) ∗ = ( a ∗ b ∗ ) ∗ ( a ∪ b ) ∗ = ( a ∗ b ∗ ) ∗ a ∗ = a ∗ ( b a ∗ ) ∗ (a \cup b)^* =(a^*b^*)^*a^* = a^*(ba^*)^* ( a ∪ b ) ∗ = ( a ∗ b ∗ ) ∗ a ∗ = a ∗ ( b a ∗ ) ∗ ( a ∪ b ) ∗ = ( a ∪ b ) ∗ ∪ a (a \cup b)^* = (a \cup b)^* \cup a ( a ∪ b ) ∗ = ( a ∪ b ) ∗ ∪ a
( a ∪ b ) ∗ ≠ a ∗ ∪ b ∗ (a \cup b)^* \neq a^* \cup b^* ( a ∪ b ) ∗ = a ∗ ∪ b ∗ ( a ∪ b ) ∗ ≠ a ∗ b ∗ (a \cup b)^* \neq a^*b^* ( a ∪ b ) ∗ = a ∗ b ∗
称R R R R R R
a a a a a a Σ \Sigma Σ ε \varepsilon ε { ε } \lbrace \varepsilon \rbrace { ε } ∅ \varnothing ∅ ( R 1 ∪ R 2 ) (R_1 \cup R_2) ( R 1 ∪ R 2 ) R 1 R_1 R 1 R 2 R_2 R 2 ( R 1 ∘ R 2 ) (R_1 \circ R_2) ( R 1 ∘ R 2 ) R 1 R_1 R 1 R 2 R_2 R 2 ( R 1 ∗ ) (R_1^*) ( R 1 ∗ ) R 1 R_1 R 1
这里使用R 1 R_1 R 1 R 2 R_2 R 2 R R R R 1 R_1 R 1 R 2 R_2 R 2 R R R 归纳定义
星号
连结
并
一些较为特殊的正则表达式
( Σ Σ ) ∗ (\Sigma\Sigma)* ( Σ Σ ) ∗ { w ∣ w 是偶长度的字符串 } \lbrace w|w\text{是偶长度的字符串}\rbrace { w ∣ w 是偶长度的字符串 } 1 ∗ ∅ 1*\varnothing 1 ∗ ∅ ∅ \varnothing ∅ ∅ ∗ \varnothing^* ∅ ∗ { ∅ } \lbrace \varnothing \rbrace { ∅ } R ∪ ∅ = R R \cup \varnothing = R R ∪ ∅ = R R ∘ ε = R R \circ \varepsilon = R R ∘ ε = R R ∪ ε R \cup \varepsilon R ∪ ε R R R R ∘ ∅ R \circ \varnothing R ∘ ∅ R R R
程序设计语言中基本对象叫做单字 ,如变量名和长了,他们可以用正则表达式描述
只要程序设计语言中单字的语法用正则表达式描述出来,自动系统能够生成词法分析程序
这个是编译程序的一部分,用在开始阶段处理输入程序
正则表达式和有穷自动机的描述能力是等价的
定理 :一个语言是正则的,当且仅当可以用正则表达式描述它引理 :如果一个语言可以用正则表达式描述,则它是正则的
把R R R N N N
R = a R = a R = a a ∈ Σ a \in \Sigma a ∈ Σ L ( R ) = { a } L(R) = \lbrace a \rbrace L ( R ) = { a }
graph LR
id1(( )) --a--> id2((接受));
R = ε R = \varepsilon R = ε L ( R ) = { ε } L(R) = \lbrace \varepsilon \rbrace L ( R ) = { ε }
graph LR
id1((接受));
R = ∅ R = \varnothing R = ∅ L ( R ) = { ∅ } L(R) = \lbrace \varnothing \rbrace L ( R ) = { ∅ }
graph LR
id1((接受));
R = R 1 ∪ R 2 R = R_1 \cup R_2 R = R 1 ∪ R 2 R = R 1 ∘ R 2 R = R_1 \circ R_2 R = R 1 ∘ R 2 R = R 1 ∗ R = R_1^* R = R 1 ∗
证明:
广义非确定型有穷自动机 :记作GNFA,即非确定型有穷自动机,但是转移箭头上可以使用任何正则表达式
起始状态有射到其他每一个状态的箭头,但是没有从任何其他状态射入的箭头
有唯一 的一个接受状态,并且它有从其他每一个状态射入的箭头,但是没有射到任何其他状态的箭头
接受状态与起始状态不同
初起始状态和接收状态之外,每一个状态到自身和其他每一个状态都有一个箭头
为了把DFA转化为GNFA,添加一个新的起始状态和一个新的接受状态
graph LR
3状态DFA --> 5状态GNFA;
5状态GNFA --> 4状态GNFA;
4状态GNFA --> 3状态GNFA;
3状态GNFA --> 2状态GNFA;
2状态GNFA --> 正则表达式;
当状态数k > 2 k>2 k > 2
挑选一个状态(非起始和接受),把它(q r i p q_{rip} q r i p
修改留下来的部分使其仍然识别相同的语言
graph LR
id1((q_i)) --R4--> id2((q_j));
id1((q_i)) --R1--> id3((q_rip));
id3((q_rip)) --R3--> id2((q_j));
id3((q_rip)) --R2-->id3((q_rip));
可以转化为
q i → ( R 1 ) ( R 2 ) ∗ ( R 3 ) ∪ ( R 4 ) q j q_i \xrightarrow[(R_1)(R_2)*(R_3)\cup(R_4)]{} q_j
q i ( R 1 ) ( R 2 ) ∗ ( R 3 ) ∪ ( R 4 ) q j
( Q , Σ , δ , q s t a r t , q a c c e p t ) (Q, \Sigma, \delta, q_{start}, q_{accept}) ( Q , Σ , δ , q s t a r t , q a c c e p t )
Q Q Q Σ \Sigma Σ δ \delta δ ( Q − { q a c c e p t } ) × ( Q − { q s t a r t } ) → R (Q - \lbrace q_{accept} \rbrace) \times (Q - \lbrace q_{start} \rbrace) \rightarrow R ( Q − { q a c c e p t } ) × ( Q − { q s t a r t } ) → R q s t a r t q_{start} q s t a r t q a c c e p t q_{accept} q a c c e p t
如果字符串w w w w = w 1 w 2 w 3 ⋯ w k , w i ∈ Σ ∗ w = w_1w_2w_3\cdots w_k, w_i \in \Sigma^* w = w 1 w 2 w 3 ⋯ w k , w i ∈ Σ ∗ q 0 , q 1 , ⋯ , q k q_0,q_1,\cdots,q_k q 0 , q 1 , ⋯ , q k
q 0 = q s t a r t q_0 = q_{start} q 0 = q s t a r t q k = q a c c e p t q_k = q_{accept} q k = q a c c e p t ∀ i , w i ∈ L ( R i ) \forall i, w_i \in L(R_i) ∀ i , w i ∈ L ( R i ) R i = δ ( q i − 1 , q i ) R_i = \delta(q_{i-1}, q_i) R i = δ ( q i − 1 , q i ) R R R q i − 1 q_{i-1} q i − 1 q i q_i q i
则称这台GNFA接受字符串w w w
则G N F A → GNFA \rightarrow G N F A → 递归算法 CONVERT(G)可以表示为
设k k k G G G
如果k = 2 k = 2 k = 2 G G G 起始状态 ,一个接受状态 及连接这两个状态的箭头组成,返回这个箭头上的表达式
否则添加一个新的起始状态和接受状态
如果k > 2 k > 2 k > 2 q r i p ∈ Q − { q s t a r t , q a c c e p t } q_{rip} \in Q - \lbrace q_{start}, q_{accept} \rbrace q r i p ∈ Q − { q s t a r t , q a c c e p t }
G ′ G' G ′ G N F A ( Q ′ , Σ , δ ′ , q s t a r t , q a c c e p t ) GNFA(Q', \Sigma, \delta', q_{start}, q_{accept}) G N F A ( Q ′ , Σ , δ ′ , q s t a r t , q a c c e p t ) Q ′ = Q − { q r i p } Q' = Q - \lbrace q_{rip} \rbrace Q ′ = Q − { q r i p }
且对每一个q i ∈ Q ′ − { q a c c e p t } q_i \in Q' -\lbrace q_{accept} \rbrace q i ∈ Q ′ − { q a c c e p t } q j ∈ Q ′ − { q a c c e p t } q_j \in Q' -\lbrace q_{accept} \rbrace q j ∈ Q ′ − { q a c c e p t }
δ ′ ( q i , q j ) = ( R 1 ) ( R 2 ) ∗ ( R 3 ) ∪ ( R 4 ) \delta'(q_i, q_j) = (R_1)(R_2)*(R_3)\cup (R_4)
δ ′ ( q i , q j ) = ( R 1 ) ( R 2 ) ∗ ( R 3 ) ∪ ( R 4 )
其中
R 1 = δ ( q i , q r i p ) R_1 = \delta(q_i, q_{rip}) R 1 = δ ( q i , q r i p ) R 2 = δ ( q r i p , q r i p ) R_2 = \delta(q_{rip}, q_{rip}) R 2 = δ ( q r i p , q r i p ) R 3 = δ ( q r i p , q j ) R_3 = \delta(q_{rip}, q_j) R 3 = δ ( q r i p , q j ) R 4 = δ ( q i , q j ) R_4 = \delta(q_i, q_j) R 4 = δ ( q i , q j )
计算C O N V E R T ( G ′ ) CONVERT(G') C O N V E R T ( G ′ )
语言种的所有字符串只要它的长度不小于某一个特定的值 - 泵长度 ,就可以被抽取
意思是:每一个这样的字符串都包括一段字串,把这段字串重复任意次,得到的字符串仍在这个语言种
设A A A p p p s s s A A A s s s 3 3 3 s = x y z s = xyz s = x y z
对每一个i ≥ 0 , x y i z ∈ A i \geq 0, xy^iz \in A i ≥ 0 , x y i z ∈ A
∣ y ∣ > 0 |y| > 0 ∣ y ∣ > 0 y ≠ ε y \neq \varepsilon y = ε ∣ x y ∣ ≤ q |xy| \leq q ∣ x y ∣ ≤ q x x x y y y p p p
∣ s ∣ |s| ∣ s ∣ y i y^i y i i i i y y y y 0 y^0 y 0 ε \varepsilon ε s s s x y z xyz x y z z , x z,x z , x ε \varepsilon ε
这是一种能力更强的描述语言的方法,这种文法能够描述某些具有递归结构的特征
A → 0 A 1 A → B B → # \begin{aligned}
A \rightarrow 0A1
\\
A \rightarrow B
\\
B \rightarrow \#
\end{aligned}
A → 0 A 1 A → B B → #
一个文法由一组替换规则 组成
替换规则也叫做产生式
每一个规则占一行
由一个符号 和一个字符串 构成
符号和字符串之间用一个箭头隔开:符号 → 字符串 \text{符号} \rightarrow \text{字符串} 符号 → 字符串
变元 :即符号,常用大学字母表示字符串 :由变元和终结符 组成起始变元 :通常出现在第一条规则的左边
如果用语法生成每一个字符串
写下起始变元,一般来说是第一条规则左边的变元
去一个写下的变元,找到以该变元开始的规则,把这个变元替换成这条规则右边的字符串
重复上步骤,直到没有变元
A ⇒ 0 A 1 ⇒ 00 A 11 ⇒ 000 A 111 ⇒ 000 B 111 ⇒ 000 # 111 A \Rightarrow 0A1 \Rightarrow 00A11 \Rightarrow 000A111 \Rightarrow 000B111 \Rightarrow 000\#111
A ⇒ 0 A 1 ⇒ 0 0 A 1 1 ⇒ 0 0 0 A 1 1 1 ⇒ 0 0 0 B 1 1 1 ⇒ 0 0 0 # 1 1 1
上下文无关语言 :能够用上下文无关文法生成的语言(CFL),用L ( G 1 ) L(G_1) L ( G 1 ) G 1 G_1 G 1
{ A → 0 A 1 A → B ⇒ A → 0 A 1 ∣ B \begin{cases}
A \rightarrow 0A1
\\
A \rightarrow B
\end{cases} \Rightarrow A \rightarrow 0A1|B
{ A → 0 A 1 A → B ⇒ A → 0 A 1 ∣ B
上下文无关文法是一个4元组( V , Σ , R , S ) (V, \Sigma, R, S) ( V , Σ , R , S )
V V V 变元集 Σ \Sigma Σ V V V 终结符集 R R R 规则集 ,每一条规则是一个变元 和一个由变元和终结符 组成的字符串S ∈ V S \in V S ∈ V
A → w A \rightarrow w A → w u A v uAv u A v 生成 u w v uwv u w v u A v ⇒ u w v uAv \Rightarrow uwv u A v ⇒ u w v u = v u = v u = v u 1 , u 2 , ⋯ , u k u_1, u_2, \cdots, u_k u 1 , u 2 , ⋯ , u k
u ⇒ u 1 ⇒ u 2 ⇒ ⋯ ⇒ u k ⇒ v u \Rightarrow u_1 \Rightarrow u_2 \Rightarrow \cdots \Rightarrow u_k \Rightarrow v
u ⇒ u 1 ⇒ u 2 ⇒ ⋯ ⇒ u k ⇒ v
其中k ≥ 0 k \geq 0 k ≥ 0 u ⇒ ∗ v u \overset{*}{\Rightarrow} v u ⇒ ∗ v { w ∈ Σ ∗ ∣ S ⇒ ∗ w } \lbrace w \in \Sigma^* | S \overset{*}{\Rightarrow} w \rbrace { w ∈ Σ ∗ ∣ S ⇒ ∗ w }
许多CFG是由几个较简单的CFG合并成的
CFG是由几个较简单的部分,可以把它拆分成几部分,再分别构成每一部分
只需要把他们的规则都放在一起,再加入新的规则S → S 1 ∣ S 2 ∣ ⋯ ∣ S k S \rightarrow S_1 | S_2 | \cdots | S_k S → S 1 ∣ S 2 ∣ ⋯ ∣ S k S i S_i S i
例如:{ 0 n 1 n ∣ b ≥ 0 } ∪ { 1 n 0 n ∣ n ≥ 0 } \lbrace 0^n1^n | b \geq 0 \rbrace \cup \lbrace 1^n0^n | n \geq 0 \rbrace { 0 n 1 n ∣ b ≥ 0 } ∪ { 1 n 0 n ∣ n ≥ 0 }
S → S 1 ∣ S 2 S 1 → 0 S 1 1 ∣ ε S 2 → 1 S 2 0 ∣ ε \begin{aligned}
S &\rightarrow S_1|S_2
\\
S_1 &\rightarrow 0S_11|\varepsilon
\\
S_2 &\rightarrow 1S_20|\varepsilon
\end{aligned}
S S 1 S 2 → S 1 ∣ S 2 → 0 S 1 1 ∣ ε → 1 S 2 0 ∣ ε
如果这个语言是正则的
先构造DFA,再构造CFG
对于DFA的每一个状态q i q_i q i R i R_i R i
如果δ ( q i , a ) = q j \delta(q_i, a) = q_j δ ( q i , a ) = q j R i → a R j R_i \rightarrow aR_j R i → a R j
如果q i q_i q i R i → ε R_i \rightarrow \varepsilon R i → ε
设q 0 q_0 q 0 R 0 R_0 R 0
有时候一个文法能够用几种不同的方式产生同一个字符串,这样的结构可能是某些情况下不希望看到的,例如:程序设计语言希望给定程序应该有唯一的解释
如果字符串w w w G G G G G G 歧义地 生产字符串w w w G G G 歧义的
某些时候能够找到一个产生相同语言的非歧义文法
某些只能使用歧义文法产生,称作固有歧义
最简单,最有用的形式叫做乔姆斯基范式 乔姆斯基范式 ,如果它的每一个规则具有如下形式:
A → B C A → a \begin{aligned}
A &\rightarrow BC
\\
A &\rightarrow a
\end{aligned}
A A → B C → a
a a a A , B , C A,B,C A , B , C B , C B,C B , C 允许规则S → ε S \rightarrow \varepsilon S → ε S S S
任一上下文无关语言都可以用乔姆斯基范式的上下文无关文法产生
添加一个新的起始变元S 0 S_0 S 0 S 0 → S S_0 \rightarrow S S 0 → S S S S
考虑所有的ε \varepsilon ε
删除一条ε \varepsilon ε A → ε A \rightarrow \varepsilon A → ε A A A
然后对规则右边出现的每一个A A A
R → u A R \rightarrow uA R → u A R → u R \rightarrow u R → u R → A v R \rightarrow Av R → A v R → v R \rightarrow v R → v R → u A v R \rightarrow uAv R → u A v R → u v R \rightarrow uv R → u v R → u A v A w R \rightarrow uAvAw R → u A v A w R → u v A w R \rightarrow uvAw R → u v A w R → u A v w R \rightarrow uAvw R → u A v w R → u v w R \rightarrow uvw R → u v w 如果有规则R → A R \rightarrow A R → A R → ε R \rightarrow \varepsilon R → ε
除非前面已经删除过规则R → ε R \rightarrow \varepsilon R → ε
即使这个R R R S 0 → ε S_0 \rightarrow \varepsilon S 0 → ε
重复进行上述步骤,直到删除所有不包括起始变元的ε \varepsilon ε
处理所有单一规则
删除一条单一规则A → B A \rightarrow B A → B A A A
然后对规则左边出现的每一个B B B
只要有一条规则B → u B \rightarrow u B → u A → u A \rightarrow u A → u B → u B \rightarrow u B → u
除非A → u A \rightarrow u A → u
u u u
重复进行上述步骤,直到删除所有单一规则
把所有留下的规则转换成适当的形式
对每一个长度k ≥ 3 k \geq 3 k ≥ 3 u 1 u 2 ⋯ u k u_1u_2\cdots u_k u 1 u 2 ⋯ u k
把每一条规则A → u 1 u 2 ⋯ u k A \rightarrow u_1u_2\cdots u_k A → u 1 u 2 ⋯ u k A → u 1 A 1 , A 1 → u 2 A 2 , A 2 → u 3 A 3 , ⋯ , A k − 2 → u k − 1 u k A \rightarrow u_1A_1,\ A_1 \rightarrow u_2A_2,\ A_2 \rightarrow u_3A_3,\ \cdots, A_{k-2} \rightarrow u_{k-1}u_k A → u 1 A 1 , A 1 → u 2 A 2 , A 2 → u 3 A 3 , ⋯ , A k − 2 → u k − 1 u k
例如:S 0 → A S A S_0 \rightarrow ASA S 0 → A S A S 0 → A A 1 S_0 \rightarrow AA_1 S 0 → A A 1 A 1 → S A A_1 \rightarrow SA A 1 → S A
每一个u i u_i u i A i A_i A i
重复上步骤,直到没有长度k ≥ 3 k \geq 3 k ≥ 3
至此,所有规则只能是以下几种形式
S 0 → ε S_0 \rightarrow \varepsilon S 0 → ε A → a i A \rightarrow a_i A → a i A → B C A \rightarrow BC A → B C A → a i B A \rightarrow a_iB A → a i B A → B a i A \rightarrow Ba_i A → B a i A → a i a j A \rightarrow a_ia_j A → a i a j
其中a i , a j a_i,a_j a i , a j A , B , C A, B, C A , B , C S 0 S_0 S 0
对每一个终结符a i a_i a i U i U_i U i U i → a i U_i \rightarrow a_i U i → a i
如果a i a_i a i
把后3种规则分别替换成
A → a i B A → B a i A → a i a j ⇒ A → U i B A → B U i A → U i U j \begin{aligned}
A &\rightarrow a_iB
\\
A &\rightarrow Ba_i
\\
A &\rightarrow a_ia_j
\end{aligned} \Rightarrow \begin{aligned}
A &\rightarrow U_iB
\\
A &\rightarrow BU_i
\\
A &\rightarrow U_iU_j
\end{aligned}
A A A → a i B → B a i → a i a j ⇒ A A A → U i B → B U i → U i U j
至此,所有的式子都应该只是以下形式
S 0 → ε A → a i A → B C \begin{aligned}
S_0 &\rightarrow \varepsilon
\\
A &\rightarrow a_i
\\
A &\rightarrow BC
\end{aligned}
S 0 A A → ε → a i → B C
这种机器(PDA)非常像非确定型有穷自动机,但是有栈 ,使之能够识别一些非正则语言
下推自动机在能力上与上下文无关文法等价
下推自动机能够把符合写到栈上,然后再读取它
写一个符合,把栈种其他的所有符合"下推 "
在任何时候,可以读和删去栈顶的符号,其余符号向上移动
在栈上写一个符号,叫做"推入 "这个符号
删去一个符号叫做弹出 它
无论是读,写,都只能在栈顶进行,遵循”先进后出 “
下推自动机(PDA)是一个6元组( Q , Σ , Γ , δ , q 0 , F ) (Q, \Sigma, \Gamma, \delta, q_0, F) ( Q , Σ , Γ , δ , q 0 , F ) Q Q Q Σ \Sigma Σ Γ \Gamma Γ F F F
Q Q Q Σ \Sigma Σ Γ \Gamma Γ δ \delta δ Q × Σ ε × Γ ε → P ( Q × Γ ε ) Q \times \Sigma_\varepsilon \times \Gamma_\varepsilon \rightarrow \mathcal{P}(Q \times \Gamma_\varepsilon) Q × Σ ε × Γ ε → P ( Q × Γ ε ) q 0 ∈ Q q_0 \in Q q 0 ∈ Q F ⊂ Q F \subset Q F ⊂ Q
一台下推自动机M = ( Q , Σ , Γ , δ , q 0 , F ) M=(Q, \Sigma, \Gamma, \delta, q_0, F) M = ( Q , Σ , Γ , δ , q 0 , F )
接受输入w w w
如果能够把w w w w = w 1 , w 2 , ⋯ , w m , ( w i ∈ Σ ε ) w=w_1, w_2, \cdots, w_m,(w_i \in \Sigma_\varepsilon) w = w 1 , w 2 , ⋯ , w m , ( w i ∈ Σ ε )
并且存在状态序列r 0 , r 1 , ⋯ , r m ∈ Q r_0, r_1, \cdots, r_m \in Q r 0 , r 1 , ⋯ , r m ∈ Q s 0 , s 1 , ⋯ , s m ∈ Δ ∗ s_0, s_1, \cdots, s_m \in \Delta^* s 0 , s 1 , ⋯ , s m ∈ Δ ∗ s 0 , s 1 , ⋯ , s m s_0, s_1, \cdots, s_m s 0 , s 1 , ⋯ , s m M M M
r 0 = q 0 r_0 = q_0 r 0 = q 0 s 0 = ε s_0 = \varepsilon s 0 = ε M M M 对于i = 0 , ⋯ , m − 1 , ( r i + 1 , b ) ∈ δ ( r i , w i + 1 , a ) i = 0, \cdots, m - 1, (r_{i+1}, b) \in \delta(r_i, w_{i+1}, a) i = 0 , ⋯ , m − 1 , ( r i + 1 , b ) ∈ δ ( r i , w i + 1 , a ) s i = a t , s i + 1 = b t , ( a , b ∈ Σ ε ) s_i = at, s_{i+ 1}= bt, (a, b \in \Sigma_\varepsilon) s i = a t , s i + 1 = b t , ( a , b ∈ Σ ε ) t ∈ Σ ∗ t \in \Sigma^* t ∈ Σ ∗ M M M
r m ∈ F r_m \in F r m ∈ F
用a , b → c a, b \rightarrow c a , b → c a a a c c c b b b
a , b , c a, b, c a , b , c ε \varepsilon ε 如果a a a ε \varepsilon ε
如果b b b ε \varepsilon ε
如果c c c ε \varepsilon ε
检测空栈的方法:
q 1 → ε , ε → $ q 2 \color{blue}q_1\color{black} \xrightarrow{\varepsilon, \varepsilon \rightarrow \$} q_2
q 1 ε , ε → $ q 2
检测输入达到末端:
q 1 → ε , $ → ε q 2 q_1 \xrightarrow{\varepsilon, \$ \rightarrow \varepsilon} \color{green}q_2
q 1 ε , $ → ε q 2
c , ε → c c, \varepsilon \rightarrow c c , ε → c c c c c c c c , c → ε c, c \rightarrow \varepsilon c , c → ε c c c c c c
a , b → c a,b \rightarrow c a , b → c a a a b b b
它们都能够描述上下文无关语言类
定理:一个语言是上下文无关的,当且仅当存在一台下推自动机识别他
设A A A G G G G G G P P P
设上下文无关文法CFG为G = ( V , Σ , R , S ) G=(V, \Sigma, R, S) G = ( V , Σ , R , S ) P = ( Q , Σ , Γ , δ , q s t a r t , F ) P=(Q, \Sigma, \Gamma, \delta, q_{start}, F) P = ( Q , Σ , Γ , δ , q s t a r t , F )
输入字母表Σ \Sigma Σ G G G
栈字母表Γ \Gamma Γ G G G V V V
设q q q r r r P P P a a a Σ ε \Sigma_\varepsilon Σ ε b b b Γ ε \Gamma_\varepsilon Γ ε P P P a a a b b b q q q r r r u = u 1 , u 2 , ⋯ , u l u = u_1, u_2, \cdots, u_l u = u 1 , u 2 , ⋯ , u l q 1 , q 2 , ⋯ , q l − 1 q_1, q_2, \cdots, q_{l - 1} q 1 , q 2 , ⋯ , q l − 1
δ ( q , a , s ) 包含 ( q 1 , u 1 ) δ ( q 1 , ε , ε ) = { ( q 2 , u l − 1 ) } δ ( q 2 , ε , ε ) = { ( q 3 , u l − 2 ) } ⋮ δ ( q l − 1 , ε , ε ) = { ( r , u 1 ) } \begin{aligned}
\delta(q, a, s)&\text{包含}(q_1 ,u_1)
\\
\delta(q_1, \varepsilon, \varepsilon) &= \lbrace (q_2, u_{l - 1}) \rbrace
\\
\delta(q_2, \varepsilon, \varepsilon) &= \lbrace (q_3, u_{l - 2}) \rbrace
\\
&\vdots
\\
\delta(q_{l - 1}, \varepsilon, \varepsilon) &= \lbrace (r, u_1) \rbrace
\end{aligned}
δ ( q , a , s ) δ ( q 1 , ε , ε ) δ ( q 2 , ε , ε ) δ ( q l − 1 , ε , ε ) 包含 ( q 1 , u 1 ) = { ( q 2 , u l − 1 ) } = { ( q 3 , u l − 2 ) } ⋮ = { ( r , u 1 ) }
使用记号( r , u ) ∈ δ ( q , a , s ) (r, u) \in \delta(q, a, s) ( r , u ) ∈ δ ( q , a , s ) q q q a a a s s s P P P a a a s s s u u u r r r
q ↓ a , s → x y z r ⇒ q ↓ a , s → z q 1 ↓ ε , ε → y q 2 ↓ ε , ε → x r \begin{aligned}
\begin{aligned}
&q&
\\
&\downarrow& a,s\rightarrow xyz
\\
&r&
\end{aligned} \quad \Rightarrow \quad
\begin{aligned}
&q&
\\
&\downarrow& a,s\rightarrow z
\\
&q_1&
\\
&\downarrow& \varepsilon,\varepsilon\rightarrow y
\\
&q_2&
\\
&\downarrow& \varepsilon,\varepsilon\rightarrow x
\\
&r&
\end{aligned}
\end{aligned}
q ↓ r a , s → x y z ⇒ q ↓ q 1 ↓ q 2 ↓ r a , s → z ε , ε → y ε , ε → x
P P P Q = { q s t a r t , q l o o p , q a c c e p t } ∪ E Q = \lbrace q_{start}, q_{loop}, q_{accept} \rbrace \cup E Q = { q s t a r t , q l o o p , q a c c e p t } ∪ E E E E q a c c e p t q_{accept} q a c c e p t 庄毅函数定义如下,从初始化开始,把符号@和S S S δ ( q s t a r t , ε , ε ) = { ( q l o o p , S @ ) } \delta(q_{start, \varepsilon, \varepsilon}) = \lbrace (q_{loop}, S@) \rbrace δ ( q s t a r t , ε , ε ) = { ( q l o o p , S @ ) }
首先处理情况( a ) (a) ( a ) δ ( q l o o p , ε , A ) = { ( q l o o p , w ) } A → w \delta(q_{loop}, \varepsilon, A) = \lbrace (q_{loop}, w) \rbrace A \rightarrow w δ ( q l o o p , ε , A ) = { ( q l o o p , w ) } A → w R R R ( b ) (b) ( b ) δ ( q l o o p , a , a ) = { ( q l o o p , ε ) } \delta(q_{loop}, a, a) = \lbrace (q_{loop}, \varepsilon) \rbrace δ ( q l o o p , a , a ) = { ( q l o o p , ε ) } ( c ) (c) ( c ) δ ( q l o o p , ε , @ ) = { ( q a c c e p t , ε ) } \delta(q_{loop}, \varepsilon, @) = \lbrace (q_{accept}, \varepsilon) \rbrace δ ( q l o o p , ε , @ ) = { ( q a c c e p t , ε ) }
→ q s t a r t ↓ ε , ε → S @ q l o o p ⇌ { ε , A → w a , a → ε ↓ ε , @ → ε q a c c e p t \begin{aligned}
\rightarrow &q_{start}
\\
&\downarrow \varepsilon, \varepsilon \rightarrow S@
\\
&q_{loop} \rightleftharpoons \begin{cases}
\varepsilon, A \rightarrow w
\\
a, a \rightarrow \varepsilon
\end{cases}
\\
&\downarrow \varepsilon, @ \rightarrow \varepsilon
\\
&q_{accept}
\end{aligned}
→ q s t a r t ↓ ε , ε → S @ q l o o p ⇌ { ε , A → w a , a → ε ↓ ε , @ → ε q a c c e p t
例子:
S → a T b ∣ b T → T a ∣ ε \begin{aligned}
S &\rightarrow aTb|b
\\
T &\rightarrow Ta|\varepsilon
\end{aligned}
S T → a T b ∣ b → T a ∣ ε
引理:一个语言被一台下推自动机识别,则它是上下文无关的
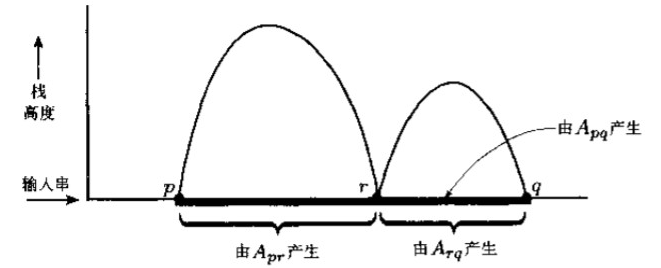
设PAD P P P G G G P P P
我们设计一个能够做更多事情的文法,对于P P P p p p q q q A p q A_{pq} A p q P P P p p p q q q P P P p p p q q q q q q p p p
先对P P P
有位移的接收状态q a c c e p t q_{accept} q a c c e p t
在接受之间排空栈
每一个转移把一个符号推入栈(推入动作),或者把一个符合弹出栈(弹出动作),但是不能同时做这两个动作
对于特点3,要把每一个同时弹出和推入的转移替换成两个转移,中间要经过一个新的状态,把每一个既不弹出也不推入的转移替换成两个转移,先推入任意一个栈符号,然后再把它弹出。P P P P P P x x x x x x P P P x x x
仅在计算的开始和结束时,栈是空的
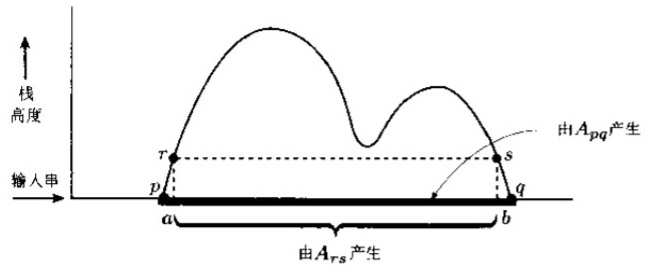
最后弹出的符号一定就是开始时推入的那个符号:A p q → a A r s b A_{pq} \rightarrow aA_{rs}b A p q → a A r s b
a a a b b b r r r p p p s s s q q q
除开始和结束时之外,在计算中的某个地方,栈变成空的
A p q → A p r A r q A_{pq} \rightarrow A_{pr}A_{rq} A p q → A p r A r q r r r
关于G G G P = ( Q , Σ , Γ , δ , q 0 , { q a c c e p t } ) P=(Q, \Sigma, \Gamma, \delta, q_0, \lbrace q_{accept} \rbrace) P = ( Q , Σ , Γ , δ , q 0 , { q a c c e p t } ) G G G { A p q ∣ p , q ∈ Q } \lbrace A_{pq} | p,q \in Q \rbrace { A p q ∣ p , q ∈ Q } A q 0 q a c c e p t A_{q_0q_{accept}} A q 0 q a c c e p t
对每一个p , q , r , s ∈ Q , t ∈ Γ p, q, r, s \in Q, t \in \Gamma p , q , r , s ∈ Q , t ∈ Γ a , b ∈ Σ ε a, b \in \Sigma_\varepsilon a , b ∈ Σ ε δ ( p , a , ε ) \delta(p, a, \varepsilon) δ ( p , a , ε ) ( r , t ) (r, t) ( r , t ) δ ( s , b , t ) \delta(s, b, t) δ ( s , b , t ) ( q , ε ) (q, \varepsilon) ( q , ε ) A p q → a A r s b A_{pq} \rightarrow aA_{rs}b A p q → a A r s b G G G
对每一个p , q , r ∈ Q p,q,r \in Q p , q , r ∈ Q A p q → A p r A r q A_{pq} \rightarrow A_{pr}A_{rq} A p q → A p r A r q G G G
最后,对每一个p ∈ Q p \in Q p ∈ Q A p p → ε A_{pp} \rightarrow \varepsilon A p p → ε G G G
对于规则A p q → A p r A r q A_{pq} \rightarrow A_{pr}A_{rq} A p q → A p r A r q
对于规则A p q → a A r s b A_{pq} \rightarrow aA_{rs}b A p q → a A r s b
下面证明A p q A_{pq} A p q x x x x x x P P P p p p q q q
断言:如果A p q A_{pq} A p q x x x x x x P P P p p p q q q
断言:如果x x x P P P p p p q q q A p q A_{pq} A p q x x x
使用归纳法可以证明上述断言
如果A A A p p p A A A p p p s s s 5 5 5 s = u v x y z s = uvxyz s = u v x y z
对于每一个i i i u v i x y i z ∈ A uv^ixy^iz \in A u v i x y i z ∈ A
∣ v y ∣ > 0 |vy| > 0 ∣ v y ∣ > 0 ∣ v x y ∣ ≤ p |vxy| \leq p ∣ v x y ∣ ≤ p
当s s s u v x y z uvxyz u v x y z
条件2 2 2 v v v y y y
条件3 3 3 v v v x x x y y y p p p
图灵机模型
储存设备:用一个无限长的带子作为无限储存,还有一个读写头,这个读写头只能在带子上读,写和移动
开始:带子上只有输入字符串,其他地方都是空的。
储存:如果需要储存信息,它可能将这个信息写在带子上
读取:为了读取已经写下的信息,它可能将读写头往回移动到这个信息所在的地方
结束:机器不停地计算直到产生输出为止
机器事先就被设置了两种状态
接受状态和拒绝状态,如果进入这两种状态,就产生输出接受或拒绝,
如果不进入任何接受状态或拒绝状态,就继续执行下去,永不停止
图灵机在带子上既能写也能读
读写头既能向左移也能向右移
带子时无限长的
进入拒绝和接收状态将立刻停机
核心时转移函数δ \delta δ Q × Γ → Q × Γ × { L , R } Q \times \Gamma \rightarrow Q \times \Gamma \times \lbrace L, R \rbrace Q × Γ → Q × Γ × { L , R }
若机器处于状态q q q a a a δ ( q , a ) = ( r , b , L ) \delta(q, a) = (r, b, L) δ ( q , a ) = ( r , b , L ) b b b a a a r r r L L L R R R
一个图灵机时一个7元组( Q , Σ , Γ , δ , q 0 , q a c c e p t , q r e j e c t ) (Q, \Sigma, \Gamma, \delta, q_0, q_{accept}, q_{reject}) ( Q , Σ , Γ , δ , q 0 , q a c c e p t , q r e j e c t ) Q , Σ , Γ Q, \Sigma, \Gamma Q , Σ , Γ
Q Q Q Σ \Sigma Σ ⊔ \sqcup ⊔ Γ \Gamma Γ ⊔ ∈ Γ , Σ ⊃ Γ \sqcup \in \Gamma, \Sigma \supset \Gamma ⊔ ∈ Γ , Σ ⊃ Γ δ \delta δ Q × Γ → Q × Γ × { L , R } Q \times \Gamma \rightarrow Q \times \Gamma \times \lbrace L, R \rbrace Q × Γ → Q × Γ × { L , R } q 0 ∈ Q q_0 \in Q q 0 ∈ Q q a c c e p t ∈ Q q_{accept} \in Q q a c c e p t ∈ Q q r e j e c t ∈ Q q_{reject} \in Q q r e j e c t ∈ Q q r e j e c t ≠ q a c c e p t q_{reject} \neq q_{accept} q r e j e c t = q a c c e p t
其计算方式为
开始:M M M n n n w = w 1 w 2 ⋅ w n ∈ Σ ∗ w = w_1w_2\cdot w_n \in \Sigma^* w = w 1 w 2 ⋅ w n ∈ Σ ∗
读写头从最左边的带方格开始运行,Σ \Sigma Σ
开始运行后,计算根据转移函数所描述的规则进行
如果M M M L L L
计算已知持续到它进入接受或拒绝状态
此时停机,如果二者都不发生,则M M M
格局 :当前状态 ,当前带内容 和读写头当前未知 会发生变化,这三项构成的整体叫做图灵机的格局
对于状态q q q u u u v v v u q v uqv u q v
当前状态是q q q
当前带内容是u v uv u v
读写头的当前未知是v v v v v v
1011 q 7 01111 1011q_701111
1 0 1 1 q 7 0 1 1 1 1
如果图灵机能合法地从格局C 1 C_1 C 1 C 2 C_2 C 2 C 1 C_1 C 1 产生 格局C 2 C_2 C 2
设a , b a, b a , b c c c Γ \Gamma Γ u u u v v v Γ ∗ \Gamma^* Γ ∗ q i q_i q i q j q_j q j u a q i b v uaq_ibv u a q i b v u q j a c v uq_jacv u q j a c v δ ( q i , b ) = ( q j , c , L ) \delta(q_i, b) = (q_j, c, L) δ ( q i , b ) = ( q j , c , L )
u a q i b v 产生 u q j a c v uaq_ibv \quad \text{产生} \quad uq_jacv
u a q i b v 产生 u q j a c v
u a q i b v 产生 u a c q j v uaq_ibv \quad \text{产生} \quad uacq_jv
u a q i b v 产生 u a c q j v
左端点
如果转移为向左移动:则格局q i b v q_ibv q i b v q j b v q_jbv q j b v
如果转移为向右移动:则格局q i b v q_ibv q i b v b q j v bq_jv b q j v
右端点
b v q i bvq_i b v q i b v q i ⊔ bvq_i\sqcup b v q i ⊔
其他情况
起始格局:q 0 w q_0w q 0 w
接受格局:状态时q a c c e p t q_{accept} q a c c e p t
拒绝格局:状态时q r e j e c t q_{reject} q r e j e c t
停机状态:接受状态和拒绝状态(不再产生新的格局)
q 1 → 0 → ⊔ , R q 2 q_1 \xrightarrow{0 \rightarrow \sqcup, R} q_2 q 1 0 → ⊔ , R q 2 δ ( q 1 , 0 ) = ( q 2 , ⊔ , R ) \delta(q_1, 0) = (q_2, \sqcup, R) δ ( q 1 , 0 ) = ( q 2 , ⊔ , R )
当状态为q 1 q_1 q 1 0 0 0
机器状态变为q 2 q_2 q 2 ⊔ \sqcup ⊔
并向右移动读写头
q 1 → 0 → R q 2 q_1 \xrightarrow{0 \rightarrow R} q_2 q 1 0 → R q 2 δ ( q 1 , 0 ) = ( q 2 , 0 , R ) \delta(q_1, 0) = (q_2, 0, R) δ ( q 1 , 0 ) = ( q 2 , 0 , R )
当状态为q 1 q_1 q 1 0 0 0
机器状态变为q 2 q_2 q 2 不改变带子
并向右移动读写头
q 1 → 0 , 1 → R q 2 q_1 \xrightarrow{0,1 \rightarrow R} q_2 q 1 0 , 1 → R q 2
当状态为q 1 q_1 q 1 0 0 0 1 1 1
机器状态变为q 2 q_2 q 2 不改变带子
并向右移动读写头
图灵机能根据输入,给出输出,并且可以再进行左右移动(不能不移动)
在开始的时候写下⊔ \sqcup ⊔ ⊔ \sqcup ⊔
在左移之前记录下当前带上位置的符号,并写下一个特殊符号#,当左移后,当前位置上带子的符号还是#的话,则左移失败,读写头已经在左端点
图灵机可以通过做记号达到一些需要记忆位置的操作,比如对于11111# 00000# 111111 这样字符串,可以将# 改写为♯ ˙ \dot{\sharp} ♯ ˙
♯ → ♯ ˙ \sharp \rightarrow \dot{\sharp}
♯ → ♯ ˙
图灵机接受输入w w w C 1 , C 2 , ⋯ C k C_1, C_2, \cdots C_k C 1 , C 2 , ⋯ C k
C 1 C_1 C 1 M M M w w w 每一个C i C_i C i C i + 1 C_{i+1} C i + 1
C k C_k C k
M M M M的语言 ,即为L ( M ) L(M) L ( M )
定义:如果有一个图灵机识别一个语言,则称语言是图灵可识别
在输入上运行一个TM时,可能出现三种结果:接受,拒绝,循环(不停机)
图灵可判定语言都是图灵可识别的,但某些图形可识别语言不是可判定的。
图灵机可以进行变形,如:多个带子,非确定性。这样的机器被称为图灵机模型的变形
原来的模型与它的所有合理的变形有着同样的能力
识别同样的语言类
这样变化中的不变性称为稳健性
图灵机有惊人的稳健性
假设图灵机可以在读取后不进行移动,则转移函数会有以下改变
Q × Γ → Q × Γ × { L , R } Q × Γ → Q × Γ × { L , R , S } \begin{aligned}
Q \times \Gamma &\rightarrow Q \times \Gamma \times \lbrace L, R \rbrace
\\
Q \times \Gamma &\rightarrow Q \times \Gamma \times \lbrace L, R, S \rbrace
\end{aligned}
Q × Γ Q × Γ → Q × Γ × { L , R } → Q × Γ × { L , R , S }
这个改变不会使图灵机能够识别更多的语言,为了证明两个模型时等价的,只要证明它们能互相模拟即可。
Q × Γ k → Q × Γ k × { L , R } k Q \times \Gamma^k \rightarrow Q \times \Gamma^k \times \lbrace L, R \rbrace^k
Q × Γ k → Q × Γ k × { L , R } k
多带图灵机还是和图灵机等价,虽然多带图灵机有多个带子,可以在单个带子上模拟出多个带子的效果,即用#分割每个带子,且对每个分割的部分多带图灵机读写头的位置的字符加上符号c ˙ \dot{c} c ˙
定理 :每一个非确定性图灵机都有一个与之等价的确定性图灵机
可以用确定性图灵机模拟非确定性图灵机的所有可能的分支,采用广度搜索的方式,若能够在某个分支中发现接受状态,则接受,否则永不停止。
可以由三带图灵机模拟非确定性图灵机,其带子分别为
输入带:不会改变
模拟带:存放非确定性图灵机中的内容,对应其某个分支
地址带:记录确定性图灵机在非确定性图灵机中的位置
推论 :一个语言时图灵可识别的,当且仅当有非确定性图灵机识别他推论 :一个语言时图灵是可判定的,当且仅当有非确定性图灵机判定他
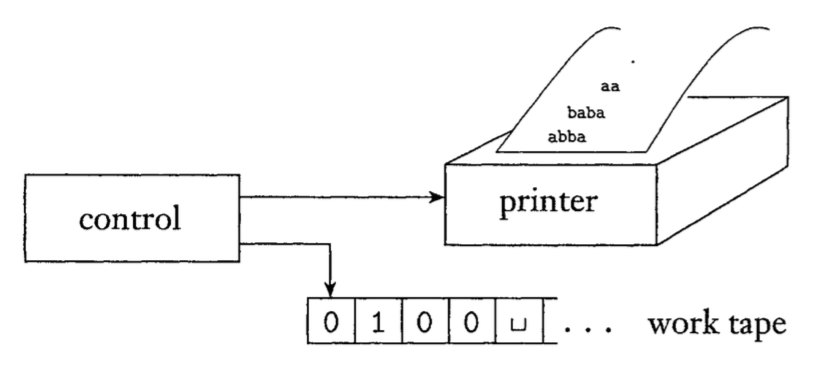
有时有些地方会使用递归可枚举语言 来替代图灵可识别语言 ,这个术语起源于称为枚举器的机器,是图灵机的一种变形,简单地说,枚举器是带有打印机的图灵机,使其为一个输出设备
定理 :一个语言是图灵可识别的,当且仅当有枚举器枚举它
考虑程序设计语言中的类似情形,现在又许多程序设计语言,但是它们都可以实现同一个算法,这意味着这两个语言描述了完全相同的算法类,即计算模型间存在着普遍的等价性。
任意两个满足合理条件的计算模型都能互相模拟,从而在能力上等价
算法的直觉概念 等于 图灵机算法 \boxed{\text{算法的直觉概念} \qquad \text{等于} \qquad \text{图灵机算法}}
算法的直觉概念 等于 图灵机算法
上述被称为丘奇-图灵论题 ,简单的来说,图灵机刻画了所有的算法。
任何计算装置:用算盘的人、超级计算机、你手中的 iPhone 等等,都不能超越图灵机模型的计算能力
形式描述:尽详细写出图灵机的状态,转移函数等, 这是最底层,最详细程度的描述
实现描述:用日常语言描述图灵机的运行,如:如何移动读写头,储存数据,没有给出转移函数等的细节
高水平描述:用日常语言进行描述,但是忽略了实现的模型,不需要提及如何移动带子或读写头
有些问题算法上能够求解,而另一些则不能,我们需要研究算法可解性的局限。
一些语言,它们都是算法上可判定的。也叫递归(Recursive)语言
图灵机识别 一门语言:当图灵机接受属于这门文法的所有语言且不接受 所有不属于这门文法的语言
A TM recognizes a language L if it accepts every x ∈ L x \in L x ∈ L not accept any x ∉ L x \notin L x ∈ / L
A language is recognizable if there is a Turing machine that recognizes it
图灵机判定 一门语言:当图灵机接受属于这门文法的所有语言且拒绝 所有不属于这门文法的语言
A TM decides a language L if it accepts every x ∈ L x \in L x ∈ L rejectst every x ∉ L x \notin L x ∈ / L
A language is decidable if there is a Turing machine that decides it
定理 :一门语言L L L L L L L ‾ \overline{L} L
下面以一个例子说明不可判定语言,假设存在M_1识别L,M_2识别L’,那么D是否判定L
1 2 3 def D (x ): if M_1(x) accepts: accepts if M_2(x) accepts: rejects
因为D可能在M_1(x)出循环,所以D不判定L,即M_1(x)可能不会停机
再来一个例子
设语言L = { < M > ∣ M 停机于 100010 } L = \lbrace <M> | M\ \text{停机于}\ 100010 \rbrace L = { < M > ∣ M 停机于 1 0 0 0 1 0 }
√
×
L L L ⚪
L ‾ \overline{L} L ⚪
因此L L L
1 2 3 def D (D ): if D(D) accepts: rejects if D(D) rejects: accepts
以上描述的是Dumaflache
很明显矛盾
因为已经建立了处理语言的术语,将用语言来表示各种计算问题,例如如下的问题
检测一个特定的自动机是否接受一个事先给定的串,此类问题可表示为语言A D F A A_{DFA} A D F A
A D F A = { < B , w > ∣ B 是 D F A , w 是串 , B 接受 w } A_{DFA} = \lbrace <B, w>\ |\ B \text{是} DFA,\ w \text{是串},\ B \text{接受} w \rbrace
A D F A = { < B , w > ∣ B 是 D F A , w 是串 , B 接受 w }
问题
DFA B是否接受输入w
< B , w > <B, w> < B , w > A D F A A_{DFA} A D F A
是相同的。类似的,其他一些计算问题也可以表示成检查语言的成员隶属关系,证明这个语言是可判定的与证明这个计算问题是可判定是同一回事
定理 :A D F A A_{DFA} A D F A
设
A N F A = { < B , w > ∣ B 是 N F A , w 是串 , B 接受 w } A_{NFA} = \lbrace <B, w>\ |\ B \text{是} NFA,\ w \text{是串},\ B \text{接受} w \rbrace
A N F A = { < B , w > ∣ B 是 N F A , w 是串 , B 接受 w }
定理 :A N F A A_{NFA} A N F A
设
A R E X = { < R , w > ∣ R 是正则表达式 , w 是串 , R 派生 w } A_{REX} = \lbrace <R, w>\ |\ R \text{是正则表达式},\ w \text{是串},\ R \text{派生} w \rbrace
A R E X = { < R , w > ∣ R 是正则表达式 , w 是串 , R 派生 w }
定理 :A R E X A_{REX} A R E X
图灵机有关的另一种问题:有穷自动机语言的空性质测试,再以前的定理中,常常必须检查一个有穷自动机是否接受一个特殊的串,在下面的证明中,要检查一个有穷自动机是否根本不接受任何串,令
E D F A = { < A > ∣ A 是 D F A , 且 L ( A ) = ∅ } E_{DFA} = \lbrace <\text{A}>\ |\ A \text{是} DFA,\ \text{且} L(A) = \varnothing \rbrace
E D F A = { < A > ∣ A 是 D F A , 且 L ( A ) = ∅ }
定理 :E D F A E_{DFA} E D F A
检查两个DFA是否识别同一个语言是可判定的,设
E Q D F A = { < A , B > ∣ A 和 B 都是 D F A , 且 L ( A ) = L ( B ) } EQ_{DFA} = \lbrace <A, B>\ |\ A \text{和} B\text{都是} DFA,\ \text{且} L(A) = L(B) \rbrace
E Q D F A = { < A , B > ∣ A 和 B 都是 D F A , 且 L ( A ) = L ( B ) }
定理 :E D F A E_{DFA} E D F A
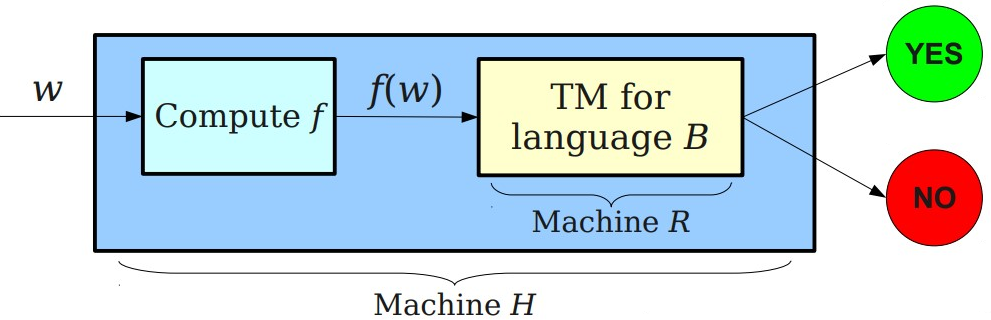
A function f : Σ 1 ∗ → Σ 2 ∗ f : \Sigma^*_1 \rightarrow \Sigma^*_2 f : Σ 1 ∗ → Σ 2 ∗
For any w ∈ Σ1*, w ∈ A iff f(w) ∈ B.
f is a computable function.
Intuitively, a mapping reduction from A to B says that a computer can transform any instance of A into an instance of B such that the answer to B is the answer to A.
1 2 3 4 5 H = “On input w: · Transform the input w into f(w). · Run machine R on f(w). · If R accepts f(w), then H accepts w. · If R rejects f(w), then H rejects w.”
R代表可以用图灵机解决的所有决定型问题问题。
也就是所有递归语言 的集合。R也等同于包含所有可计算函数的集合。
RE(Recursively Enumerable,参考递归可枚举集合)是一个决定型问题的复杂度类
RE也可以视为存在一个将问题里面"yes"的答案一一列举出来的图灵机(也就是这里所说’可枚举的’的意思)。
co-RE则是所有RE语言其补集(complement)的总集合。
某种意义上我们可以说,co-RE包含的语言,其里面的问题要证明为错误,只要有限的时间;但是可能要无限的时间,才能证明这问题正确。
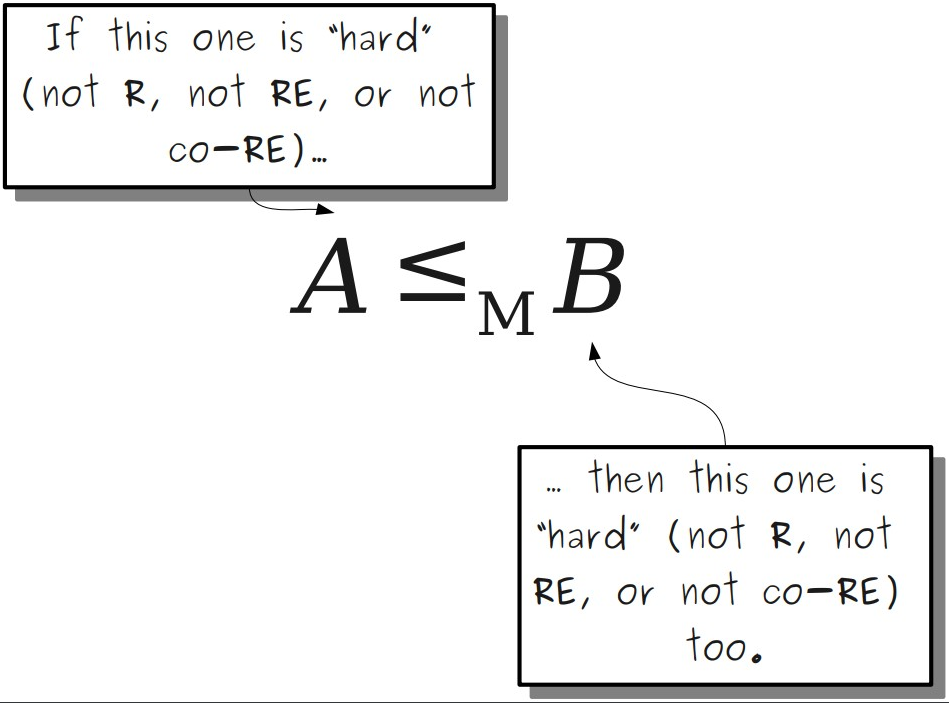
当B ∈ R B \in R B ∈ R A ≤ M B A \leq_M B A ≤ M B A ∈ R A \in R A ∈ R
当B ∈ R E B \in RE B ∈ R E A ≤ M B A \leq_M B A ≤ M B A ∈ R E A \in RE A ∈ R E
当B ∈ c o − R E B \in co-RE B ∈ c o − R E A ≤ M B A \leq_M B A ≤ M B A ∈ c o − R E A \in co-RE A ∈ c o − R E
注释: A ≤ M B A \leq_M B A ≤ M B
当A ∉ R A \notin R A ∈ / R A ≤ M B A \leq_M B A ≤ M B B ∉ R B \notin R B ∈ / R
当A ∉ R E A \notin RE A ∈ / R E A ≤ M B A \leq_M B A ≤ M B B ∉ R E B \notin RE B ∈ / R E
当A ∉ c o − R E A \notin co-RE A ∈ / c o − R E A ≤ M B A \leq_M B A ≤ M B B ∉ c o − R E B \notin co-RE B ∈ / c o − R E
定理 :每个上下文无关语言都是可判定的
检查一个CFG是否派生一个特定的串
A C F G = { < R , w > ∣ R 是 C F G , w 是串 , G 派生 w } A_{CFG} = \lbrace <R, w>\ |\ R \text{是} CFG,\ w \text{是串},\ G \text{派生} w \rbrace
A C F G = { < R , w > ∣ R 是 C F G , w 是串 , G 派生 w }
定理 :A C F G A_{CFG} A C F G
检查一个CFG是否不派生任何串
E C F G = { < G > ∣ G 是 C F G , 且 L ( G ) = ∅ } E_{CFG} = \lbrace <G>\ |\ G \text{是} CFG,\text{且}L(G) = \varnothing \rbrace
E C F G = { < G > ∣ G 是 C F G , 且 L ( G ) = ∅ }
定理 :E C F G E_{CFG} E C F G
如果两个集合都是无限的,怎么比较它们的相对规模?
VIDEO
定义 :设A A A B B B f f f A A A B B B
如果f f f a ≠ b ⇒ f ( a ) ≠ f ( b ) a \neq b \Rightarrow f(a) \neq f(b) a = b ⇒ f ( a ) = f ( b ) f f f 一对一 的
如果f f f B B B B B B b b b a ∈ A a \in A a ∈ A f ( a ) = b f(a) = b f ( a ) = b f f f 到上的
如果存在一对一且到上的函数f : A → B f: A \rightarrow B f : A → B 对应 ,称A A A B B B
关系
对应
一对一
单射
到上的
全射
一对一且到上的
全单射
定义 :称一个集合是可数的,如果它是有限的,或者它与N \mathbb{N} N 定理 :R \mathbb{R} R ∃ x ∈ R \exist x \in \mathbb{R} ∃ x ∈ R N \mathbb{N} N 推论 :存在语言不是图灵可识别的(有不可数个语言,却只有可数个图灵机)
由于图灵机只能识别一个语言,而语言比图灵机更多,故有些语言不能由任何的图灵机识别,这样的语言就不是图灵可识别的
下列语言是不可判定的
A T M = { < M , w > ∣ M 是 T M , 且 M 接受 w } A_{TM} = \lbrace <M, w>\ |\ M \text{是} TM,\text{且} M \text{接受} w \rbrace
A T M = { < M , w > ∣ M 是 T M , 且 M 接受 w }
设H H H A T M A_{TM} A T M M M M T M TM T M w w w < M , w > <M, w> < M , w > M M M w w w H H H w w w M M M w w w H H H w w w
H ( < M , w > ) = { 接受 如果 M 接受 w 拒绝 如果 M 不接受 w H(<M, w>) = \begin{cases}
\text{接受} & \text{如果}M\text{接受}w
\\
\text{拒绝} & \text{如果}M\text{不接受}w
\end{cases}
H ( < M , w > ) = { 接受 拒绝 如果 M 接受 w 如果 M 不接受 w
现在构造一个新的图灵机D D D H H H
D ( < M > ) = { 接受 如果 M 不接受 w 拒绝 如果 M 接受 w D(<M>) = \begin{cases}
\text{接受} & \text{如果}M\text{不接受}w
\\
\text{拒绝} & \text{如果}M\text{接受}w
\end{cases}
D ( < M > ) = { 接受 拒绝 如果 M 不接受 w 如果 M 接受 w
将D D D D D D
D ( < D > ) = { 接受 如果 D 不接受 D 拒绝 如果 D 接受 D D(<D>) = \begin{cases}
\text{接受} & \text{如果}D\text{不接受}D
\\
\text{拒绝} & \text{如果}D\text{接受}D
\end{cases}
D ( < D > ) = { 接受 拒绝 如果 D 不接受 D 如果 D 接受 D
因此D D D H H H
定义 :令M是一个在所有输入上都停机的确定型图灵机,M的运行时间 ,或者说时间复杂度 ,是一个函数f : N → N f: \mathcal{N} \rightarrow \mathcal{N} f : N → N f ( n ) f(n) f ( n ) f ( n ) f(n) f ( n ) f ( n ) f(n) f ( n ) f ( n ) f(n) f ( n )
大O记法 :小于等于小o记法 :小于θ \theta θ 记法 :等于Ω \Omega Ω 记法 :大于等于ω \omega ω 记法 :大于
定理 :设t ( n ) t(n) t ( n ) t ( n ) ≥ n t(n) \geq n t ( n ) ≥ n t ( n ) t(n) t ( n ) O ( t 2 ( n ) ) O(t^2(n)) O ( t 2 ( n ) ) 定理 :设t ( n ) t(n) t ( n ) t ( n ) ≥ n t(n) \geq n t ( n ) ≥ n t ( n ) t(n) t ( n ) 2 O ( t ( n ) ) 2^{O(t(n))} 2 O ( t ( n ) )
多项式时间复杂度 :算法的复杂度表示为O ( n k ) O(n^k) O ( n k ) n n n 指数型时间复杂度 :算法的复杂度表示为O ( k n ) O(k^n) O ( k n ) O ( n ! ) O(n!) O ( n ! )
所有合理的确定型计算模型都是多项式等价的,也就是,它们中任何一个模型都可以模拟另一个,而运行时间只增长多项式倍。
定义 :P是确定型单带图灵机在多项式时间内可判定的语言类
P = ⋃ k TIME ( n k ) P = \bigcup_k \text{TIME}(n^k)
P = k ⋃ TIME ( n k )
对于所有与确定型单带图灵机多项式等价的计算模型来说,P是不变的
P大致对应于在计算机上实际可解的问题类
通俗的说,P问题是可以找到一个只有多项式复杂度的算法的问题
定理 :每一个上下文无关语言都是P的成员
定义 :NP是具有多项式时间验证机的语言类,NP即非确定型多项式时间
N P = ⋃ k NTIME ( n k ) NP = \bigcup_k \text{NTIME}(n^k)
N P = k ⋃ NTIME ( n k )
通俗的说明N P NP N P P P P N P NP N P
定理 :一个语言在NP中,当且仅当它能够被某个非确定性多显示时间图灵机判定
P = 成员资格可以快速地判定的语言类 N P = 成员资格可以快速地验证的语言类 \begin{aligned}
P &= \text{成员资格可以快速地判定的语言类}
\\
NP &= \text{成员资格可以快速地验证的语言类}
\end{aligned}
P N P = 成员资格可以快速地判定的语言类 = 成员资格可以快速地验证的语言类
对于HAMPATH和CLIQUE,它们是NP成员,但是不知道是否属于P,但是还不能证明在NP中存在一个不属于P的语言。
也称NP完全,NP中某一些问题的复杂性与整个类的复杂性相关联,这些问题中任何一个如果存在多项式时间算法,那么所有NP问题都是多项式时间可解的,这类问题称为NP完全
定义 :称语言B为NP完全的,如果它满足以下的两个条件
B属于NP
NP中的每个A都多项式时间内可归约到B
定理 :若B是NP完全的,且B ∈ P B \in P B ∈ P P = N P P = NP P = N P 定理 :若B是NP完全的,且B ≤ p C B \leq_p C B ≤ p C
NPH问题 :N P NP N P 归类 为某个X X X N P NP N P X X X X X X N P NP N P
NPC问题 :N P NP N P N P H NPH N P H