理解计算机时如何生成和运行可执行文件
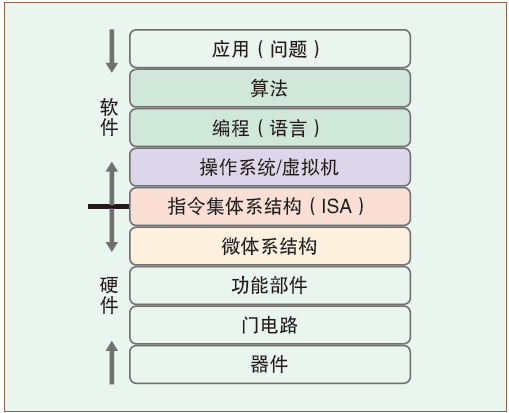
上层是下层的抽象
下层是上层的实现
要求
注:注重概念,不注重汇编等的编写和C语言的基础等
- 汇编基础
- C语言
- 计算机基本知识
冯·若依曼计算机
思想:储存程序
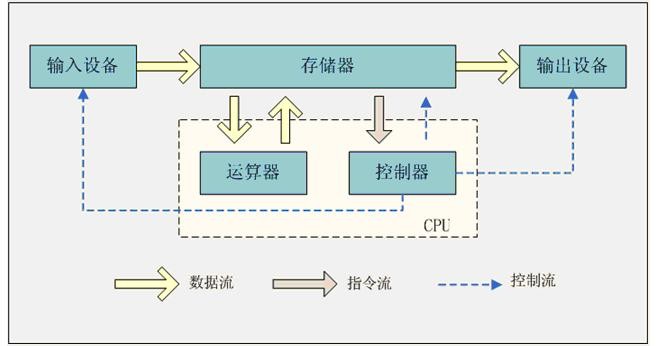
早期,部件之间采用分散方式相连
现在,部件之间大部分采用总线方式相连
- 储存器:能存数据+指令
- 控制器:能取出指令来执行
- 运算器:能进行加减乘除和一些逻辑运算和附加运输
- IO设备:与主机进行通信
内部:以二进制表示指令和数据
指令:由操作码和地址码两部分组成
- 操作码:指出操作类型
- 地址码:指出操作数的地址
现代计算机结构模型
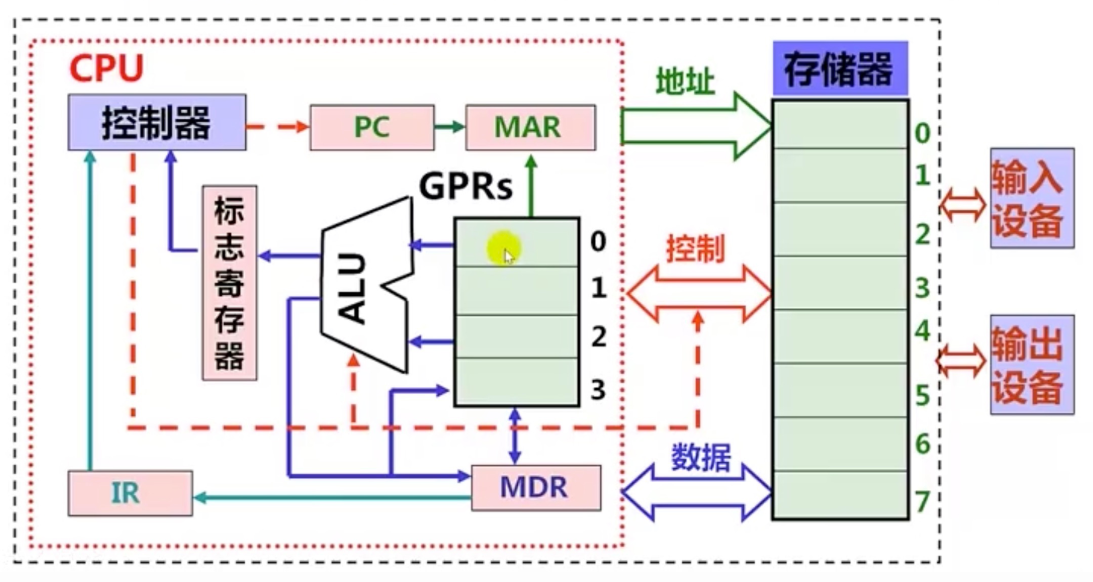
ALU:算数逻辑部件GPRs:通用寄存器组MDR:储存器数据寄存器MAR:储存器地址寄存器PC:程序计数器(寄存器)IR:指令寄存器
程序执行步骤
- 根据PC取指令
- 指令译码
- 取操作数
- 指令执行
- 回写结果
- 修改
PC的值 - 执行下一条指令
指令
- 包含操作码和操作数或地址码
- 机器指令用二进制
- 汇编指令用符号
- 只能描述
- 取/存一个数
- 两数的加减乘除与或
- 根据结果判断是否转移
具体由以下成分构成
| 名称 | 描述 |
|---|---|
| 操作性质 | 操作码 |
| 源操作数1 或(和) 2 | 立即数,寄存器编号,储存地址 |
| 谜底操作数地址 | 寄存器编号,储存地址 |
编程语言的发展
机器级语言
都是面向机器结构的语言
- 机器语言(打孔)
- 汇编语言
- 汇编指令
- 面向能力描述
高级语言
- 与具体机器结构没有关系
- 面向算法描述
- “面向过程”·"面向对象"两种类型
- 处理逻辑分为三种结构
- 顺序结构
- 选择结构
- 循环结构
- 有两种转换方式(语言处理程序)
- 编译:将高级语言源程序转换为机器级目标程序
- 预处理程序
- 编译器
- 汇编器
- 连接器
- 解释 :将高级语言语句逐条翻译为机器指令并执行,不生成目标文件
- 编译:将高级语言源程序转换为机器级目标程序
程序转换处理过程
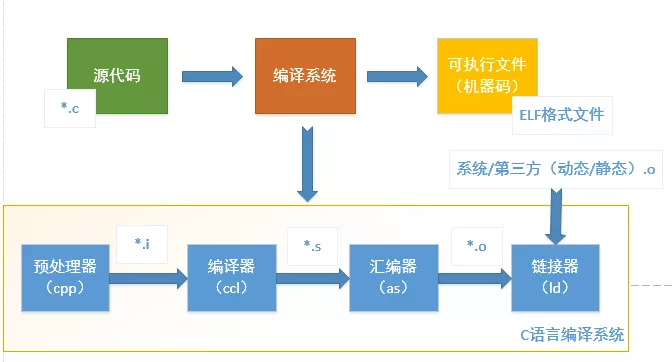
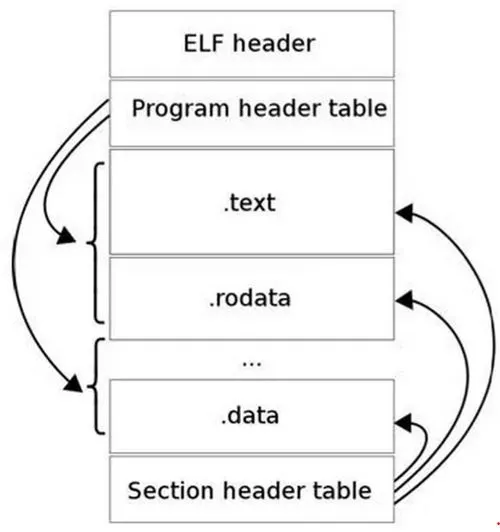
ELF文件
ELF文件格式如下图所示,位于ELF Header和Section Header Table之间的都是段(Section)。
.text:已编译程序的指令代码段。.rodata:ro代表read only,即只读数据(譬如常数const)。.data:已初始化的C程序全局变量和静态局部变量。.bss:未初始化的C程序全局变量和静态局部变量。.debug:调试符号表,调试器用此段的信息帮助调试。
早期计算机系统层次
语言的发展是一个不断"抽象"的过程
- 机器语言(第一代程序设计语言)
- 应用程序
- 指令集体系结构
- 计算机硬件
- 汇编语言(第二代程序设计语言)
- 应用程序
- 汇编程序
- 操作系统
- 指令集体系结构
- 计算机硬件
- 高级语言
- 第三代程序设计语言(如何做)
- 第四代程序设计语言(做什么)
- 应用程序
- 汇编程序
- 操作系统
- 指令集体系结构
- 计算机硬件
计算机系统的不同用户
- 最终用户(用户)
- 系统管理员(运维)
- 应用程序员(开发)
- 系统程序员(底层)
指令集体系结构ISA
规定了如何使用硬件,是对硬件的抽象,所有软件功能都建立在ISA之上,计算机组成必须实现ISA规定的功能。
- 可执行的指令的集合
- 指令格式
- 操作种类
- 每种操作对应的操作数的相应规定
- 指令可以接受的操作数的类型
- 操作数可以存放的寄存器组的结构
- 寄存器的名称
- 寄存器的编号
- 寄存器的长度
- 寄存器的用途
- 操作数存放的储存空间大小和编址方式
- 操作数在储存空间的存放顺序
- 大端
- 小端
- 寻址方式:指令获取操作数的方式
- PC、条件码定义:指令执行过程的控制方式
不同ISA规定的指令集不同,如:
- IA-32
- MIPS
- ARM
信息的二进制编码
-
数值数据
- 无符号整数
- 带符号整数
- 浮点数
-
非数值数据
- 逻辑树
- 西文字符·汉字
-
机器数:用0和1进行编码的数
-
真值:真正的值
进制转换
略,自行Google
定点数的编码
原码
- 数值部分不变
- 正:用0表示
- 负:用1表示
补码(2’s complement)
模运算系统
在一个模运算系统里,一个数与他除以"模"后的余数相等
例子: 时钟(模12)
一个负数的补码等于模减该负数的绝对值
对于某一确定的模,某数减去小于模的另一数,总可以用该数加上另外一数负数的补码来代替
变形补码
双符号位,用于存放可能溢出的中间结果
简便求法
符号为0,则为正数,数值部分相同
符号为1,则为负数,数值部分取反,末尾加1
移码
将每一个数值加上一个偏置常数
通常,当编码维数为n时,偏置常数取或
比如:
C语言数的表示
无符号整数
无符号整数就是一串数字序列,在一个数后加’U’表示无符号数,同时有无符号和带符号数时,都转换为无符号数。
-
LSB:最低有效位
-
MSB:最高有效位
-
高到低位从左到右
-
高到低位从右到左
带符号整数
一般用补码表示带符号整数
- 补码运算系统时模运算系统,加减运算统一
- 0的表示唯一
- 比原码多表示一个负数
浮点数
- 符号位(Sign):
- 0代表正
- 1代表为负
- 指数位(Exponent:用于存储科学计数法中的指数数据,并且采用移位存储
- 尾数部分(Mantissa):尾数部分
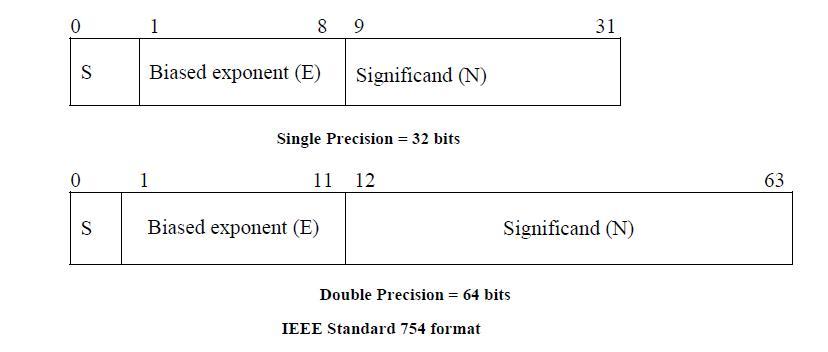
IEEE 754
数据的基本宽度
比特(bit)
计算机中处理、储存、传输信息的最小单位
字节(byte)
- 线代计算机中,存储器按字节编码
- 字节是最小可寻址单位
- 如果一个字节为一个排列单位,则
- LSB:最低有效位
- MSB:最高有效位
1 btye = 8 bit = len(0x0F) = len(0000 1111)
大端小端
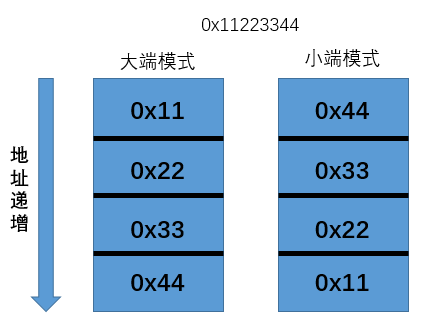
大端:MSB所在的地址时数的地址
小端:LSB所在的地址时数的地址
Intel处理器
- x86是Intel开发的一类处理器体系结构的泛称(尾数86)
- Intel 8086
- Intel 80286
- i386
- i486
- 由于数字不能注册为商标,所以就有了奔腾,Core i7等等
- 性质32位x86架构的名称x86-32改为了IA-32(Intel Architecture-32)
- AMD首先提出了一个兼容IA-32指令集的64位版本
- 扩充了指令,寄存器的个数,更新了参数传送的方式
- AMD称其为AMD64,与Intel的Intl64不同(不同于IA-64)
- 现在通称x86-64,简称x64
IA-32支持数据类型
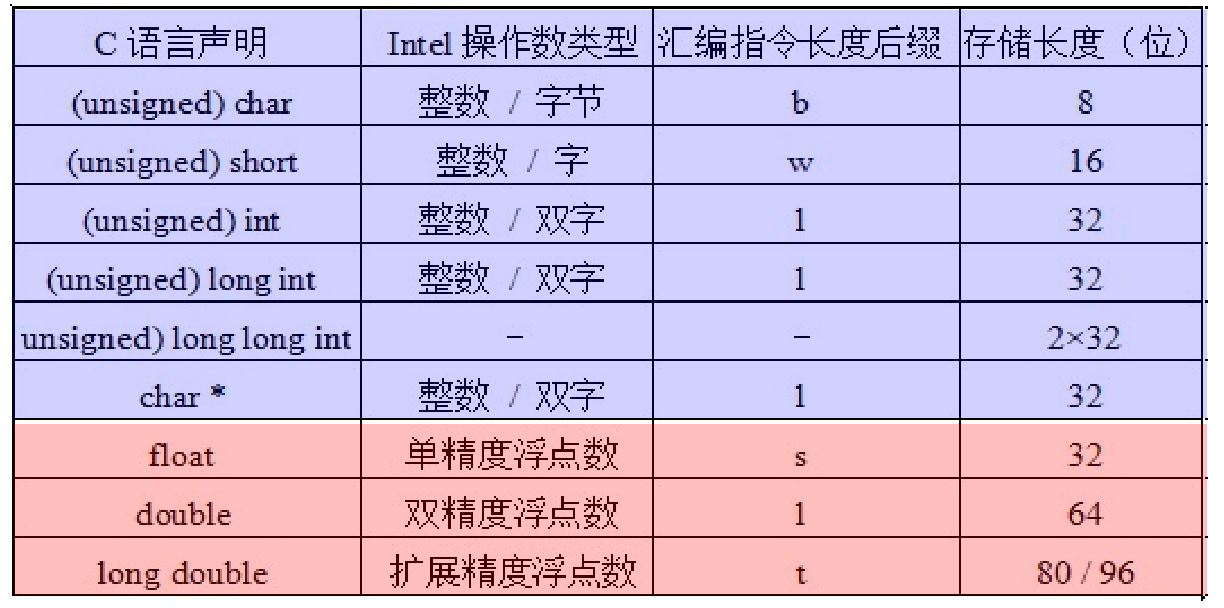
IA-32寄存器组织
ESP:堆栈指针EBP:基址指针- 调用者保存
EAX、ECX、EDX
- 被调用者保存
EBX、ESI、EDI
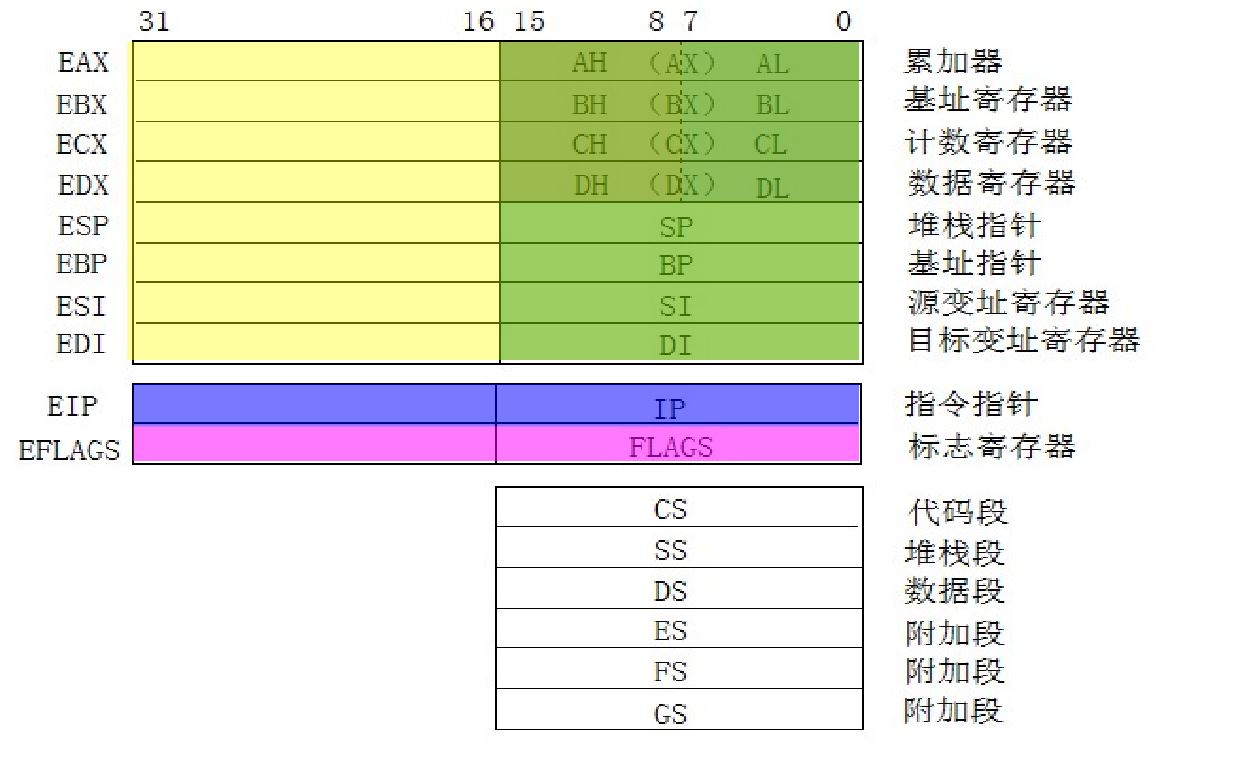
| 编号 | 8位寄存器 | 16位寄存器 | 32位寄存器 | 64位寄存器 | 128位寄存器 |
|---|---|---|---|---|---|
| 000 | AL | AX | EAX | MM0/ST(0) | XMM0 |
| 001 | CL | CX | ECX | MM1/ST(1) | XMM1 |
| 010 | DL | DX | EDX | MM0/ST(2) | XMM2 |
| 011 | BL | BX | EBX | MM0/ST(3) | XMM3 |
| 100 | AH | SP | ESX | MM0/ST(4) | XMM4 |
| 101 | CH | BP | EBP | MM0/ST(5) | XMM5 |
| 110 | DH | SI | ESI | MM0/ST(6) | XMM6 |
| 111 | BH | DI | EDI | MM0/ST(7) | XMM7 |
IA-32标志寄存器
| 31-32 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 保留 | ID | VIP | VIF | AC | VM | RF | 0 | NT | IOPL | 0 | D | I | T | S | Z | 0 | A | 0 | P | 1 | C |
6个条件标志
OF(溢出标志):用于反映有符号数加减运算所得结果是否溢出。如果运算结果超过当前运算位数所能表示的范围,则称为溢出,OF的值被置为1,否则,OF的值被清为0。SF(符号标志):用来反映运算结果的符号位,它与运算结果的最高位相同。在微机系统中,有符号数采用补码表示法,所以,SF也就反映运算结果的正负号。运算结果为正数时,SF的值为0,否则其值为1。CF(进位标志):用来反映运算是否产生进位或借位。如果运算结果的最高位产生了一个进位或借位,那么,其值为1,否则其值为0。ZF(零标志):用来反映运算结果是否为0。如果运算结果为0,则其值为1,否则其值为0。PF(奇偶标志):用于反映运算结果中“1”的个数的奇偶性。如果“1”的个数为偶数,则PF的值为1,否则其值为0。AF(辅助进位标志):在发生下列情况时,辅助进位标志AF的值被置为1,否则其值为0:- 在字操作时,发生低字节向高字节进位或借位时
- 在字节操作时,发生低4位向高4位进位或借位时
3个控制标志
DF(方向标志):来决定在串操作指令执行时有关指针寄存器发生调整的方向。在微机的指令系统中,还提供了专门的指令来改变标志位DF的值。IF(中断允许标志):中断允许标志IF是用来决定CPU是否响应CPU外部的可屏蔽中断发出的中断请求。但不管该标志为何值,CPU都必须响应CPU外部的不可屏蔽中断所发出的中断请求,以及CPU内部产生的中断请求。具体规定如下:- 当IF=1时,CPU可以响应CPU外部的可屏蔽中断发出的中断请求
- 当IF=0时,CPU不响应CPU外部的可屏蔽中断发出的中断请求。
TF(追踪标志):被置为1时,CPU进入单步执行方式,即每执行一条指令,产生一个单步中断请求。这种方式主要用于程序的调试。
IA-32寻址方式
- IA-32是典型的CISC(复杂指令集计算机)风格ISA
- 2个专用寄存器:
EIP(PC),标志寄存器EFLAGS - 6个段寄存器(间接给出段基址)
- 存储器地址空间位4GB,按字节编址,小端方式
寻址方式
如何根据指令给定信息得到操作数或操作数地址
操作数所在的位置
- 指令中:立即寻址
- 寄存器中:寄存器寻址
- 存储单元中:其他寻址方式
微处理器工作模式
寻址方式与微处理器工作模式有关
- 实地址模式(基本用不到)
- 为与8086/8088兼容而设置
- 寻址空间为1MB,20位地址:(CS)<<4+(IP)
- 保护模式
- 采用虚拟储存管理,多任务情况下隔离,保护
- 80286以上微处理器的工作模式
- 寻址空间为(4GB),32为线性地址分段
| 寻址方式 | 说明 |
|---|---|
| 立即寻址 | 指令之间给出操作数 |
| 寄存器寻址 | 指定的寄存器R的内容为操作数 |
| 位移 | LA=(SA)+A |
| 基址寻址 | LA=(SA)+(B) |
| 基址加位移 | LA=(SA)+(B)+A |
| 比例变址加位移 | LA=(SA)+(I)*S+A |
| 基址加变址加位移 | LA=(SA)+(B)+(I)+A |
| 基址加比例变址加位移 | LA=(SA)+(B)+(I)*S+A |
| 相对寻址 | LA=(PC)+A |
-
(X): X的内容
-
SR:段寄存器
-
PC:程序寄存器
-
B:基寄存器
-
I:变址寄存器
-
SR:确定操作数所在的段的段基址
-
后面部分(有效地址):给出操作数所在段的偏移地址
IA-32机器指令格式
| 指令段 | 操作码 | 寻址方式 | SIB | 位移 | 直接数据 |
|---|---|---|---|---|---|
| 字节数 | 1 or 2 | 0 or 1 | 0 or 1 | 1、2、4 | 立即数 |
寻址方式的格式
1 | ---------------------- |
- Mod:寻址方式
- Reg/OP:寄存器的编号 or 操作码扩展指令
- R/M:寄存器操作数 or 存储器操作数
SIB
1 | ---------------------- |
- 基址B和变址I都可以是8个GRS中任意一个
- SS为比例因子
操作码
- opcode
- W:与机器模式(16/32)位一起确定寄存器位数(
AL/AX/EAX) - D:操作方向(确定源和目标)
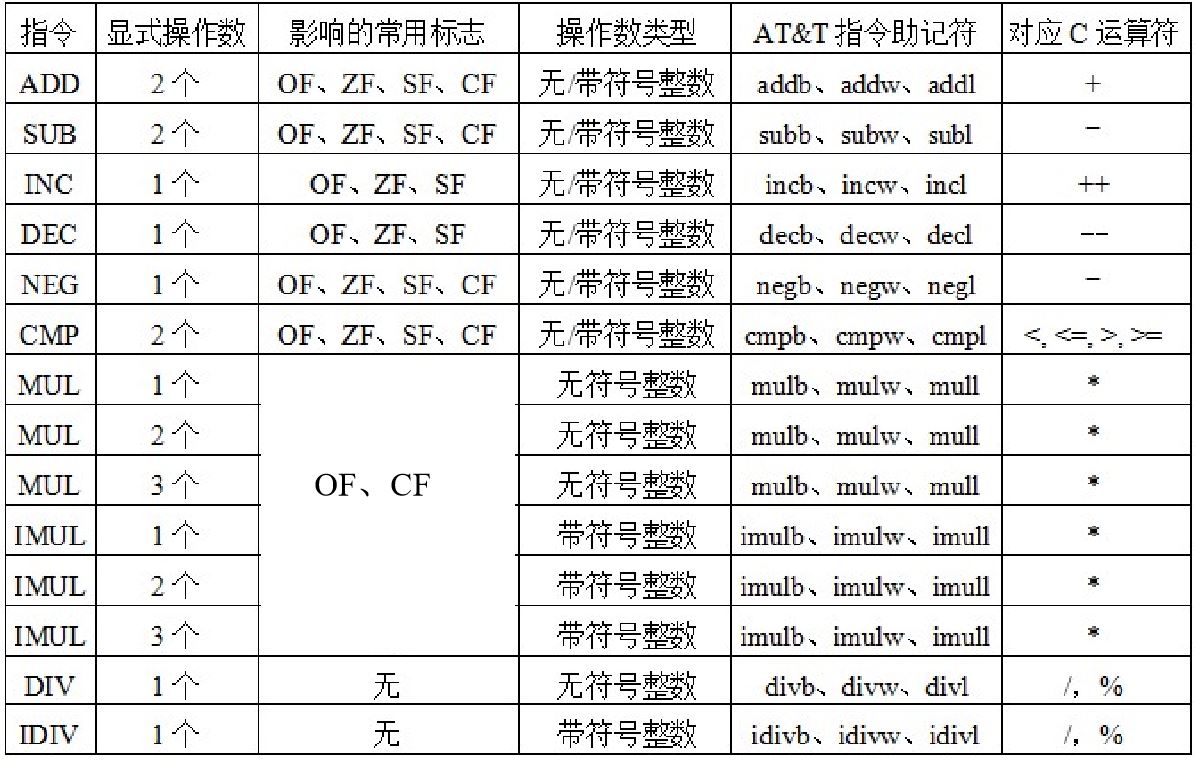
IA-32常用指令
通用数据传输指令
- MOV:一般传送,
movbmovwmovl等
- MOVS:符号扩展传送
movsbwmovswl
- MOVZ:零扩展传送
movzwlmovzbl
- XCHG:数据交换
- PUSH/POP:入栈/出栈
pushlpushwpoplpopw
定点算数运算指令
- 加/减运算
- 影响标志,不区分无/带符号
ADD:加,包括addb(8)、addw(16)、addl(32)SUB:加,包括subb(8)、subw(16)、subl(32)
- 增1/减1运算
- 影响除CF以外标志,不区分无/带符号
INC:加,包括incb、incw、inclDEC: 减,包括decb、decw、decl
- 取负运算
- 影响标志、若对0取负,则结果为0且CF清0,否则CF置1
- NEG:取负,包括
negb、negw、negl
- 比较运算
- 做减法得到标志、不区分无/带符号
CMP:比较,包括cmpb、cmpw、cmpl
- 乘/除运算
- 不影响标志,区分无/带符号
MUL/IMUL:无符号乘/带符号乘- 若给出一个操作数SRC,则另一个源操作数隐含在
AL/AX/EAX中- 结果分别放在
AX(16)或DX-AX(32)或EDX-EAX(64)中,n位*n位=2n位
- 结果分别放在
- 若指令中给出两个操作数DST和SRC,则将DST和SRC相乘,结果在DST中,n位*n位=n位
- 若指令中给出三个操作数REG、IMM和SRC,则将SRC和立即数IMM相乘,结果在REG中,n位*n位=n位
- 若给出一个操作数SRC,则另一个源操作数隐含在
DIV/IDIV:无符号除/带符号除- 只明显指出除数,用
EDX-EAX中内容除以指定的除数- 若为8位,则16位被除数在
AX寄存器中,商送回AL,余数在AH - 若为16位,则32位被除数在
DX-AX寄存器中,商送回AX,余数在DX - 若为32位,则被除数在
EDX-EAX寄存器中,商送回EAX,余数在EDX
- 若为8位,则16位被除数在
- 只明显指出除数,用
在栈里弄出一块区域:R[esp] = R[esp] - 4; M[R[esp]] = R[ebp]
按位运算指令
仅NOT不影响标志,其他指令OF=CF=0,而ZF和SF则根据结果设置
若全0,则ZF=1,若最高位位1,则SF=1
- 逻辑运算
NOT:非,包括notb、notw、notlAND:与,包括andb、andw、andlOR: 或,包括orb、orw、orlXOR:异或,包括xorb,xorw,xorlTEST:做"与"操作测试、仅影响标志
- 移位运算
- 移位运算(左/右移时,最高/最低位送CF)
SHL/SHR:逻辑左/右移,包括shlb、shrw、shrlSAL/SAR:算术左/右移,左移判溢出,右移高位补符- 移位前,后符号位发送变化,则
OF=1 - 包括
salb、sarw、sarl
- 移位前,后符号位发送变化,则
ROL/ROR:循环左/右移,包括rolb、rorw、rollRCL/RCR:带进位循环左/右移,即:将CF作为操作数,一部分循环移位- 包括
rclb、rcrw,rcll
- 包括
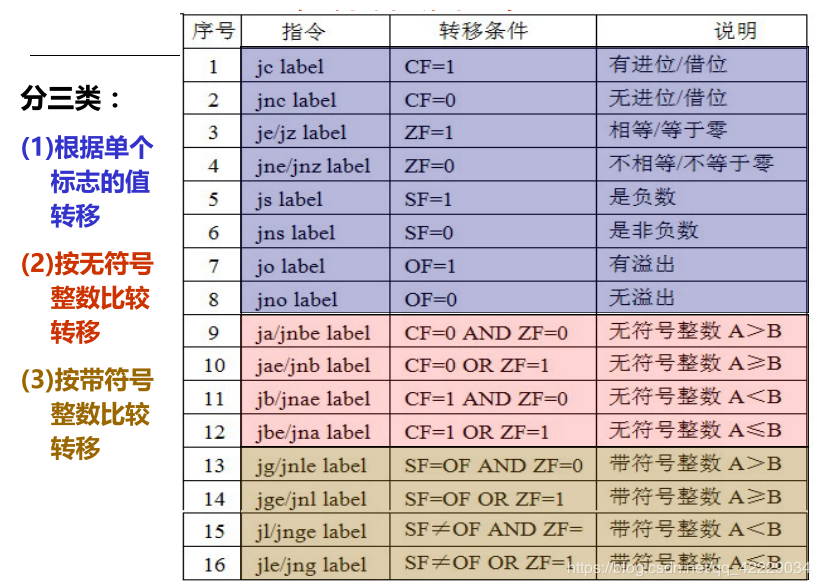
控制跳转指令
指令执行可按顺序或跳转到转移目标指令处执行
- 无条件转移指令
JMP DST:无条件转移到目标指令DST处执行
- 条件转移
Jcc DST:cc位条件码,根据条件码判断是否满足条件,若满足,则转移到目标指令DST处执行,否则按顺序执行
- 条件设置
SETcc DST:按条件码cc判断的结果保存到DST(8位寄存器)
- 调用和返回指令(用于过程调用)
CALL DST:返回地址RA入栈,转DST处执行RET:从栈中取出返回地址RA,转到RA处执行
- 中断指令
- TODO
地址传送指令
- LEA:加载有效地址
leal
输入输出指令
- IN/OUT:I/O端口与寄存器之间的交换
标志传送指令
- 将EFLAG压栈,或将栈顶内容送到EFLAG
PUSHFPOPF
指令执行过程
指令:
1 | 80483d4: 55 push %ebp |
执行过程:
1 | 1 10 |
11:控制器进行译码,得出R[esp] = R[esp] - 4; M[R[esp]] = R[ebp],(32位所以-4)
esp:堆栈指针
ebp:基址指针
12:MAR储存esp内容,写到地址线上
13:控制器发出写指令
14:把EBP内容写进MDR里面,送到数据线上
15:把数据线上的值写到地址线的地址里
16:PC加OP长度,执行下一条指令
C表达式类型转换顺序
1 | (unsigned) char/(unsigned) short -> int -> unsigned -> long long -> unsigned long long |
IA-32浮点处理架构
IA-32浮点处理架构有两种
- x87FPU指令集(gcc默认)
- SSE指令集(x86-64架构所用)
IA-32中处理浮点数有三种类型
-
float类型:32位IEEE 754 单精度格式
-
double类型:64位IEEE 754 双精度格式
-
long double类型:80位双精度扩展格式
-
早期的浮点数处理器是作为CPU的外置协处理器出现的
-
x87 FPU特指与x86处理器配套的浮点协处理器架构
- 浮点寄存器采用栈结构
- 深度为8,宽度为80位,即8个80位寄存器
- 名称位ST(0) ~ ST(7),栈顶位ST(0),编号分别为0~7
- 浮点寄存器采用栈结构
-
所有浮点运算都按80位扩展精度进行
-
浮点数在浮点寄存器和内存之间传送
- 从浮点寄存器到内存:80位扩展精度格式转换为32位或64位
- 从内存到浮点寄存器:32位或64位格式转换为80位扩展精度格式
X87 FPU指令
数据传送类
- 装入(转换为80位扩展精度)
FID:将数据从存储单元装入浮点寄存器栈顶ST(0)FILD:将数据从int型转换位浮点格式后,装入浮点寄存器栈顶
- 存储(转换位IEEE 754单精度或双精度)
- 带P结尾指令表示操作数会出栈,也即ST(1)将变为ST(0)
FSTx:x为s/l时,将栈顶ST(0)转换为单/双精度格式,然后存入存储单元FSTPx:弹出栈顶元素,并完成与FSTx相同的功能FISTx:将栈顶数据从int型转换为浮点格式后,存入存储单元FISTP:弹出栈顶元素,并完成与FISTx相同的功能
- 交换
FXCH:交换栈顶和次栈顶两元素
- 常数装载到栈顶
FLD1:装入常数1.0FLDZ:装入常数0.0FLDPI:装入常数pi(=3.1415926…)FLDL2E:装入常数log(2)eFLDL2T:装入常数log(2)10FLDLG2:装入常数log(10)2FLDLN2:装入常数Log(e)2
算术运算类
- 加法
FADD/FADDP:相加/相加后弹出栈FIADD:按int型转换后相加
- 减法
FSUB/FSUBP:相减/相减后弹出栈FSUBR/FSUBRP:调换次序相减/相减后弹出栈FISUB:按int型转换后相减FISUBR:按int型转换并调换次序相减- 若指令未带操作数,则默认操作数为ST(0)、ST(1) 带R后缀指令是指操作数顺序变反,例如: fsub执行的是x-y,fsubr执行的就是y-x
- 乘法
FMUL/FMULP: 相乘/相乘后弹出栈FIMUL:按int型转换后相乘
- 除法
FDIV/FDIVP: 相除/相除后弹出栈FIDIV:按int型转换后相除FDIVR/FDIVRP:调换次序相除/相减后弹出栈FIDIVR:按int型转换并调换次序相除
MMX/SSE指令集
由MMX发展而来的SSE架构
- MMX指令使用8个64位寄存器MM0~MM7,借用8个80位寄存 器ST(0)~ST(7)中64位尾数所占的位,可同时处理8个字节,或4 个字,或2个双字,或一个64位的数据
- MMX指令并没带来3D游戏性能的显著提升,故推出SSE指令, 并陆续推出SSE2、SSE3、SSSE3和SSE4等采用SIMD技术的指 令集,这些统称为SSE指令集
- SSE指令集将80位浮点寄存器扩充到128位多媒体扩展通用寄存 器XMM0~XMM7,可同时处理16个字节,或8个字,或4个双 字(32位整数或单精度浮点数),或两个四字的数据
- 从SSE2开始,还支持128位整数运算,或同时并行处理两个64位 双精度浮点数
SSE指令(SIMD操作)
- paddb指令(操作数在两个xmm寄存器中)
- 一条指令同时完成16个单字节数据相加
- 类似指令paddw同时完成8个单字数据相加
- 类似指令psubl同时完成4个双字数据相减
- movdqa指令
- 将双四字(128位)从源操作数处移到目标操作数处
- 用于在 XMM 寄存器与 128 位存储单元之间移入/移出双 四字,或在两个 XMM 寄存器之间移动
– 源操作数或目标操作数是存储器操作数时,操作数必须是 16 字节边界对齐,否则将发生一般保护性异常 (#GP)
- movdqu指令
- 在未对齐的存储单元中移入/移出双四字
过程调用的机器级表示
IA-32的寄存器使用约定
- 调用者保存寄存器:
EAX、EDX、ECX当过程P调用过程Q时,Q可以直接使用这三个寄存器,不用将它们的值保存到栈中。如果P在从Q返回后还要用这三个寄存器的话,P应在转到Q之前先保存,并在从Q返回后先恢复 它们的值再使用。 - 被调用者保存寄存器:
EBX、ESI、EDI Q必须先将它们的值保存到栈中再使用它们,并在P返回之前恢复它们的值。 EBP和ESP分别是帧指针寄存器和栈指针寄存器,分别用来指 向当前栈帧的底部和顶部。
为减少准备和结束阶段的开销,应先使用EAX、ECX、EDX寄存器
过程(函数)的结构
- 准备阶段
1 | ------------ - 形成帧底:`push`指令和`mov`指令 |
- 过程(函数)体
1 | 2. pushl %ebp |
- 结束阶段
- 退栈:
leave指令或pop指令 - 取返回地址返回:
ret指令
- 退栈:
数据对齐
要求数据的地址是相应的边界地址,目前机器字长为32位或64位,主存按一个传送单位(32/64/128位)进 行存取,而按字节编址。
- 按边界对齐(若一个字为32位)
- 字地址:4的倍数(低两位为0)
- 半字地址:2的倍数(低位为0)
- 字节地址:任意
- 不按边界对齐
- 坏处:可能会增加访存次数!
4字节对齐方式:
1 | 访问Z需要2次 访问Z需要一次 |
X:2bytes
O:8bytes
Y:1byte
Z:2bytes
W:1byte
最简单的对齐策略是:按其数据长度进行对齐
- Windows采用策略:
- int型地址是4的倍数
- short型地址是2的倍数
- double和long long型的是8的倍数
- float型的是4的倍数
- char不对齐
- Linux采用更宽松策略:
- short型是2的倍数
- 其他类型如int、float、double和指针等都是4的倍数
可以参见C语言的结构体的对齐进行理解
对齐方式的设定
#pragma pack(n)- 为编译器指定结构体或类内部的成员变量的对齐方式
- 当自然边界(如int型按4字节、short型按2字节、float按4字节 )比n大时,按n字节对齐
__attribute__((aligned(m)))- 为编译器指定一个结构体或类或联合体或一个单独的变量(对象)的 对齐方式
- 按m字节对齐(m必须是2的幂次方),且其占用空间大小也是m的 整数倍,以保证在申请连续存储空间时各元素也按m字节对齐
__attribute__((packed))- 不按边界对齐,称为紧凑方式
越界访问和缓冲区溢出
数组元素可使用指针来访问,因而对数组的引用没有边界约束
- C语言程序中对数组的访问可能会有意或无意地超越数组存储区范围而无法发现。
- 数组存储区可看成是一个缓冲区,超越数组存储区范围的写入操作称为缓冲区溢
- 缓冲区溢出是一种非常普遍、非常危险的漏洞,在各种操作系统、应用软件中广泛存在。
- 缓冲区溢出攻击是利用缓冲区溢出漏洞所进行的攻击。利用缓冲区溢出攻击,可导致程序运行失败、系统关机、重新启动等后果。
1 | ----------------- |
- 对上图中的buffer进行
strcpy赋值,且赋值的字符串大小为25字符 - 将hacker的首址置于结束符
'\0'前4个字节,25字符 - 赋值字符串假设为
0123456789ABCDEFXXXX\x11\x84\x04\x08\x00 0123456789ABCDEF会占据buffer的内存,XXXX会占据EBP的旧址的内存\x11\x84\x04\x08则会占据return成为0x08048411,于是返回地址成为了0x08048411- 这样就会执行在地址
0x08048411的程序
程序的加载和运行
- UNIX/Linux系统中,可通过调用
execve()函数来加载并执行程序。
1 | int execve(char *filename, char *argv[], *envp[]); |
filename是加载并运行的可执行文件名(如./hello),可带参数列表argv和环境变量列表envp。若错误(如找不到指定文件filename),则返回-1,并将控制权交给调用程序;若函数执行成功,则不返回,最终将控制权传递到可执行目标中的主函数main。
test文件
1 |
|
攻击程序
1 | // 0x08048411 |
构造出以上程序即可进行溢出攻击
x86-64架构
- Intel最早推出的64位架构是基于超长指令字VLIW技术的IA-64体系结构,Intel称其为显式并行指令计算机EPIC ( Explicitly parallel{} Instruction Computer)。
- 安腾和安腾2分别在2000年和2002年问世,它们是IA-64体系结构的最早的具体实现,因为是一种全新的、与IA-32不兼容的架构,所以,没有获得预期的市场份额。
- AMD公司利用Intel在IA-64架构上的失败,抢先在2003年 推出兼容IA-32的64位版本指令集x86-64,AMD获得了以前属于Intel的一些高端市场。AMD后来将x86-64更名为AMD64。
- Intel在2004年推出IA32-EM64T,它支持x86-64指令集。Intel为了表示EM64T的64位模式特点,又使其与IA-64有所区别,2006年开始把EM64T改名为Intel64。
x86-64中各类数据的长度
| C语言声明 | Intel操作数类型 | 汇编后缀 | x86-64(位) | IA-32(位) |
|---|---|---|---|---|
| (unsigned) char | 整数/字节 | b | 8 | 8 |
| (unsigned) short | 整数/字 | w | 16 | 16 |
| (unsigned) int | 整数/双字 | l | 32 | 32 |
| (unsigned) long int | 整数/四节 | q | 64 | 32 |
| (unsigned) long long int | 整数/四节 | q | 64 | 2*32 |
| char * | 整数/四节 | q | 64 | 32 |
| float | 单精度浮点数 | s | 32 | 32 |
| double | 双精度浮点数 | d | 64 | 64 |
| long double | 扩展精度浮点数 | t | 80/128 | 80/96 |
x86-64的通用寄存器
- 增8个64位通用寄存器(整数寄存器)
R8、R9、R10、R11、R12、R13、R14和R15- 可作为8位(
R8B`R15B`)、16位(`R8W`R15W)或32位寄存器(R8D~R15D)使用
- 所有GPRs(通用寄存器)都从32位扩充到64位
- 8个32位通用寄存器对应扩展寄存器
EAX-RAXEBX-RBXECX-RCXEDX-RDXEBP-RBPESP-RSPESI-RSIEDI-RDI
EBP、ESP、ESI和EDI的低8位寄存器分别是:EBP-BPLESP-SPLESI-SILEDI-DIL
- 可兼容使用原
AH、BH、CH和DH寄存器 - 使原来IA-32中的每个通用寄存器都可以是8位、16位、 32位和64位,如:
SIL、SI、ESI、RSI
- 8个32位通用寄存器对应扩展寄存器
- 指令可直接访问16个64位寄存器:
RAX、RBX、RCX、RDX、RBP、RSP、RSI、RDI,以及R8~R15 - 指令可直接访问16个32位寄存器:
EAX、EBX、ECX、EDX、EBP、ESP、ESI、EDI,以及R8D~R15D - 指令可直接访问16个16位寄存器:
AX、BX、CX、DX、BP、SP、SI、DI,以及R8W~R15W - 指令可直接访问16个8位寄存器:
AL、BL、CL、DL、BPL、SPL、SIL、DIL,以及R8B~R15B - 为向后兼容,指令也可直接访问
AH、BH、CH、DH– 通过寄存器传送参数,因而很多过程不用访问栈,因此,与IA-32不同,x86-64不需要帧指针寄存器,即RBP可用作普通寄存器使用 - 程序计数器为64位寄存器
RIP
x86-64的浮点寄存器
- long double型数据虽然还采用80位(10B)扩展精度格式,但所分配存储空间从12B扩展为16B,即改为16B对齐方式,但不管是分配12B还是16B,都只用到低10B
- 128位的XMM寄存器从原来的8个增加到16个
- 浮点操作指令集采用基于SSE的面向XMM寄存器的指令集,而不采用基于浮点寄存器栈的x87FPU指令集
- 浮点操作数存放在XMM寄存器中
数据传送指令
助记符q表示操作数长度为四字(即64位)
movabsq I, R:将64位立即数送64位通用寄存器movq:传送一个64位的四字movsbq、movswq、movslq:将源操作数进行符号扩展并传送 到一个64位寄存器或存储单元中movzbq、movzwq:将源操作数进行零扩展后传送到一个64位寄 存器或存储单元中movl:的功能相当于movzlq指令pushq S:R[rsp]←R[rsp]-8; M[R[rsp]] ←Spopq D: D← M[R[rsp]]; R[rsp]←R[rsp]-8
常规的算术逻辑运算指令
只要将原来IA-32中的指令扩展到64位即可。例如:
addq(四字相加)subq(四字相减)incq(四字加1)decq(四字减1)imulq(带符号整数四字相乘)orq(64位相或)salq(64位算术左移)leaq(有效地址加载到64位寄存器)
特殊的算术逻辑运算指令
对于x86-64,还有一些特殊的算术逻辑运算指令。例如:
imulq S:R[rdx]:R[rax]← S * R[rax] (64位*64位带符号整数)mulq S:R[rdx]:R[rax]← S * R[rax] (64位*64位无符号整数)cltq:R[rax] ← SignExtend(R[eax]) (将EAX内容符号扩展为四字)clto: R[rdx]:R[rax]← SignExtend(R[rax]) (符号扩展为八字)idivq S:- R[rdx] ← R[rdx]:R[rax] mod S (带符号整数相除、余数)
- R[rax] ← R[rdx]:R[rax]÷S (带符号整数相除、商)
divq S:- R[rdx] ← R[rdx]:R[rax] mod S (无符号整数相除、余数)
- R[rax] ← R[rdx]:R[rax]÷S (无符号整数相除、商)
x86-64过程调用的参数传递
在过程(函数) 中尽量使用寄 存器RAX、 R10和R11。 若使用RBX、RBP、R12、R13、R14和R15,则需要将它们先保存在栈中再使用 ,最后返回前再恢复其值
- 通过通用寄存器传送参数,很多过程不用访问栈,故执行时间 比IA-32代码更短
- 最多可有6个整型或指针型参数通过寄存器传递
- 超过6个入口参数时,后面的通过栈来传递
- 在栈中传递的参数若是基本类型,则都被分配8个字节
- call(或callq)将64位返址保存在栈中之前,执行R[rsp]←R[rsp]-8
- ret从栈中取出64位返回地址后,执行R[rsp]←R[rsp]+8
可执行文件生成过程
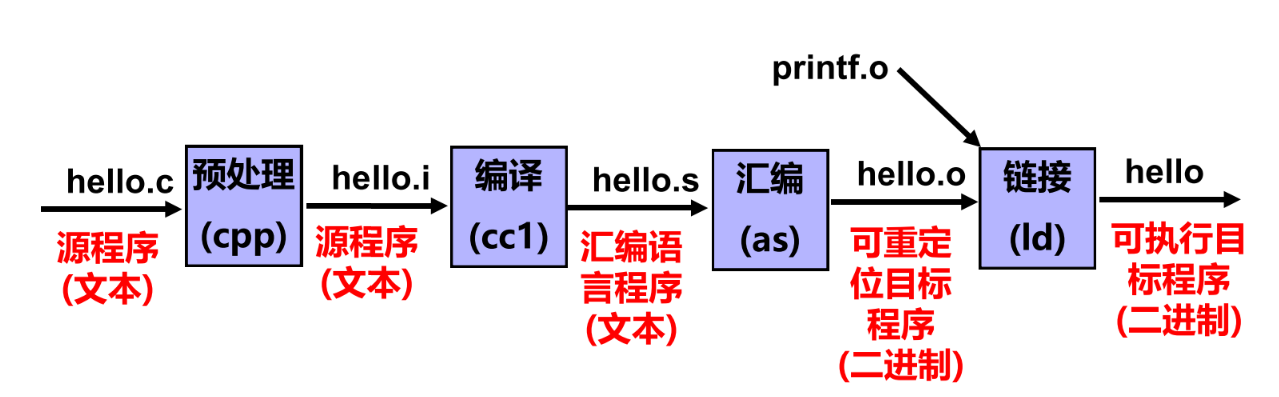
预处理
- 预处理命令
gcc –E hello.c –o hello.icpp hello.c > hello.i
- 处理源文件中以“#”开头的预编译指令,包括:
- 删除
#define并展开所定义的宏 - 处理所有条件预编译指令,如
#if、#ifdef、#endif等 - 插入头文件到
#include处,可以递归方式进行处理 - 删除所有的注释
//和/* */ - 添加行号和文件名标识,以便编译时编译器产生调试用的行号信息
- 保留所有
#pragma编译指令(编译器需要用)
- 删除
经过预编译处理后,得到的是预处理文件(如,hello.i) ,它还是一个可读的文本文件 ,但不包含任何宏定义
编译
- 编译过程就是将预处理后得到的预处理文件(如 hello.i)进行词法分析、语法分析、语义分析、优化后,生成汇编代码文件
- 来进行编译处理的程序称为编译程序(编译器,Compiler)
- 编译命令
gcc –S hello.i –o hello.s(编译)gcc –S hello.c –o hello.s(预处理并且编译)/user/lib/gcc/i486-linux-gnu/4.1/cc1 hello.c
- 经过编译后,得到的汇编代码文件(如 hello.s)还是可读的文 本文件,CPU无法理解和执行它
gcc命令实际上是具体程序(如ccp、cc1、as等)的包装命令,用户通过gcc命令来使用具体的预处理程序ccp、编译程序cc1和汇编程序as等
汇编
- 汇编代码文件(由汇编指令构成)称为汇编语言源程序
- **汇编程序(汇编器)**用来将汇编语言源程序转换为机器指令序列(机器语言程序)
- 汇编指令和机器指令一一对应,前者是后者的符号表示,它们都属于机器级指令,所构成的程序称为机器级代码
- 汇编命令
gcc –c hello.s –o hello.ogcc –c hello.c –o hello.oas hello.s -o hello.o(as是一个汇编程序)
- 汇编结果是一个可重定位目标文件(如,hello.o),其中包含的是不可读的二进制代码,必须用相应的工具软件来查看其内容
链接
- 预处理、编译和汇编三个阶段针对一个模块(一个
*.c文件)进行处理,得到对应的一个可重定位目标文件(一个*.o文件) - 链接过程将多个可重定位目标文件合并以生成可执行目标文件
- 链接命令
gcc –static –o myproc main.o test.old –static –o myproc main.o test.o-static表示静态链接,如果不指定-o选项,则可执行文件名 为a.out
链接带来的好处:
- 模块化
- 一个程序可以分成很多源程序文件
- 可构建公共函数库,如数学库,标准C库等
- 效率高
- 时间上,可分开编译
- 空间上,无需包含共享库所有代码
链接过程的本质
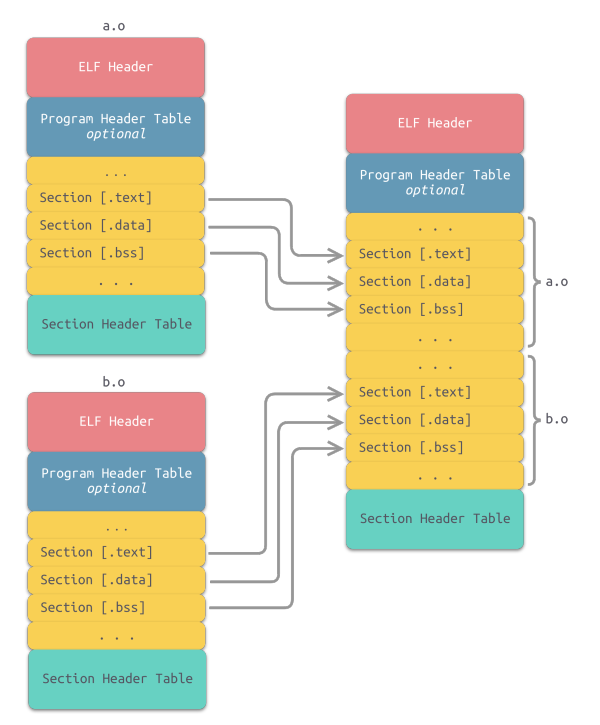
个个节合并到虚拟地址空间中
符号解析
目的:将每个模块中引用的符号与某个目标模块中的定义符号建立关联
每个定义符号在代码段或数据段中都被分配了存储空间,将引用符号与定义符号建立关联后,就可在重定位时将引用符号的地址重定位为相关联的定义符号的地址。
- 符号解析
- 程序中有定义和引用的符号(包括变量和函数等)
void swap() {…} /* 定义符号swap */swap(); /* 引用符号swap */swap(); /* 引用符号swap */
- 编译器将定义的符号存放在一个符号表(symbol table)中.
- 符号表是一个结构数组
- 每个表项包含符号名、长度和位置等信息
- 链接器将每个符号的引用都与一个确定的符号定义建立关联
- 程序中有定义和引用的符号(包括变量和函数等)
- 重定位
- 将多个代码段与数据段分别合并为一个单独的代码段和数据段
- 计算每个定义的符号在虚拟地址空间中的绝对地址
- 将可执行文件中符号引用处的地址修改为重定位后的地址信息
符号的定义和引用
- 说明符号类型的一般是定义
- 函数内部的局部变量,不是符号
- 其他都属于定义
符号的定义实质:指被分配了存储空间。为函数名即指其代码所在区;为变量名即指其所占的静态数据区。所有定义符号的值就是其目标所在的首地址
链接符号的类型
每个可重定位目标模块m都有一个符号表,它包含了在m中定义和引用的符号。有三种链接器符号:
Global symbols(模块内部定义的全局符号)- 由模块m定义并能被其他模块引用的符号。例如,非static C函数和非static的C全局变量(指不带static的全局变量)
External symbols(外部定义的全局符号)- 由其他模块定义并被模块m引用的全局符号
Local symbols(本模块的局部符号)- 仅由模块m定义和引用的本地符号。例如,在模块m中定义的带static的C函数和全局变量
- 链接器局部符号不是指程序中的局部变量(分配在栈中的临时性变量),链接器不关心这种局部变量
本地符号在本模块内定义并引用,因此,其解析较简单,只要与本模块内唯一的定 义符号关联即可。
全局符号(外部定义的、内部定义的)的解析涉及多个模块,故较复杂。
- 可重定位目标文件 (
.o)- 其代码和数据可和其他可重定位文件合并为可执行文件
- 每个.o 文件由对应的.c文件生成
- 每个.o文件代码和数据地址都从0开始
- 可执行目标文件 (默认为
a.out)- 包含的代码和数据可以被直接复制到内存并被执行
- 代码和数据地址为虚拟地址空间中的地址
- 共享的目标文件 (
.so)- 特殊的可重定位目标文件,能在装入或运行时被装入到内存并自动被链接,称为共享库文件
- Windows中称其为Dynamic Link Libraries(DLLs)
- Linux等类UNIX:ELF格式(COFF的变种),称为可执行可链接(Executable and Linkable Format,简称ELF)
全局符号的强、弱
- 函数名和已初始化的全局变量名是强符号
- 未初始化的全局变量名是弱符号
多重定义符号的处理规则
- 强符号不能多次定义
- 强符号只能被定义一次,否则链接错误
- 若一个符号被定义为一次强符号和多次弱符号,则 按强定义为准
- 对弱符号的引用被解析为其强定义符号
- 若有多个弱符号定义,则任选其中一个
- 使用命令 gcc –fno-common链接时,会告诉链接器在遇到多个弱定义的全局符号时输出一条警告信息。
符号解析时只能有一个确定的定义(即每个符号仅占一处存储空间)
多重定义全局符号的问题
- 尽量避免使用全局变量
- 一定需要用的话,就按以下规则使用
- 尽量使用本地变量(static),模块内引用不大会出错
- 全局变量要赋初值,使成为强符号,易查出链接错误
- 外部全局变量要使用extern,以示其引用的定义在其他模块
多重定义全局变量会造成一些意想不到的错误,而且是默默发生的,编译系统不会警告,并会在程序执行很久后才能表现出来,且远离错误引发处。特别是在一个具有几百个模块的大型软件中,这类错误很难修正。大部分程序员并不了解链接器如何工作,因而养成良好的编程习惯是非常重要的。
目标文件中的符号表
.symtab节记录符号表信息,是一个结构数组,符号表(symtab)中每个表项(16B)的结构如下:
1 | typedef struct { |
- 符号类型(Type):数据、函数、源文件、节、未知
- 绑定属性(Bind):全局符号、局部符号、弱符号
其他情况:ABS表示不该被重定位;UND表示未定义;COM表示未初始化数据(.bss),此时,value表示对齐要求,size给出最小大小
main.o中的符号表中最后三个条目(共10个)
举例:
1 | Num: value Size Type Bind Ot Ndx Name |
- buf是main.o中第3节(
.data)偏移为0的符号,是全局变量,占8B - main是第1节(
.text)偏移为0的符号,是全局函数,占33B - swap是未定义的符号,不知道类型和大小,全局的(在其他模块定义)
swap.o中的符号表中最后4个条目(共11个)
1 | Num: value Size Type Bind Ot Ndx Name |
bufp1是未分配地址且未初始化的本地变量(ndx=COM), 按4B对齐且占4B
链接器中符号解析的全过程
- E 将被合并以组成可执行文件的所有目标文件集合
- U 当前所有未解析的引用符号的集合
- D 当前所有定义符号的集合
- 开始E、U、D为空,首先扫描main.o,把它加入E,同时把myfun1加入U,main加入D。
- 接着扫描到mylib.a,将U中所有符号(本例中为myfunc1)与 mylib.a中所有目标模块(myproc1.o和myproc2.o )依次匹配,发现在myproc1.o中定义了myfunc1,故myproc1.o加入E,myfunc1从U转移到D。
- myproc1.o中发现还有未解析符号printf,将其加到 U
- 不断在mylib.a的各模块上进行迭代以匹配U中的符号,直到U、D都不再变化。
- 此时U中只有一个未解 析符号printf,而D中有main和myfunc1。因为模块 myproc2.o没有被加入E中,因而它被丢弃。
- 接着,扫描默认的库 文件libc.a,发现其目标模块printf.o定义了printf,于是printf也从U移到D,并将 printf.o加入E,同时把它定义的所有符号 加入D,而所有未解析符号加入U。
- 处理完libc.a时,U一定是空的。
链接器对外部引用的解析算法要点如下:
- 按照命令行给出的顺序扫描.o 和.a 文件
- 扫描期间将当前未解析的引用记录到一个列表U中
- 每遇到一个新的.o 或 .a 中的模块,都试图用其来解析U中的符号
- 如果扫描到最后,U中还有未被解析的符号,则发生错误
重定位
符号解析完成后,可进行重定位工作,分三步
- 合并相同的节
- 将集合E的所有目标模块中相同的节合并成新节
- 对定义符号进行重定位(确定地址)
- 确定新节中所有定义符号在虚拟地址空间中的地址
- 完成这一步后,每条指令和每个全局或局部变量都可确定地址
- 对引用符号进行重定位(确定地址)
- 修改.text节和.data节中对每个符号的引用(地址)
重定位信息
- 汇编器遇到引用时,生成一个重定位条目
- 数据引用的重定位条目在.rel_data节中
- 指令中引用的重定位条目在.rel_text节中
- IA-32有两种最基本的重定位类型
- R_386_32: 绝对地址
- R_386_PC32: PC相对地址
- ELF中重定位条目格式如下:
1 | typedef struct { |
Executable and Linkable Format(ELF)
两种视图
- 链接视图(被链接):可重定位目标文件(Relocatable object files)
- 节(section)是 ELF 文件中具有相同特征的最小可处理单位
- 执行视图(被执行):可执行目标文件(Executable object files)
- 由不同的段(segment)组成,描述节如何映射到存储段中,可多个节映射到同一段
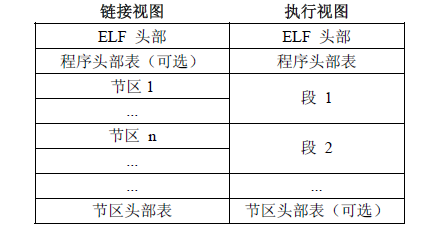
链接视图
可重定位目标文件
-
可被链接(合并)生成可执行文件或共享目标文件
-
静态链接库文件由若干个可重定位目标文件组成
-
包含代码、数据
- 已初始化全局变量和局部静态变量
.data - 未初始化的全局变量和局部静态变量
.bss
- 已初始化全局变量和局部静态变量
-
包含重定位信息(指出哪些符号引用处需要重定位)
-
文件扩展名为.o(相当于Windows中的.obj文件)
-
ELF头- 包括16字节标识信息、文件类型(.o, exec, .so)、机器类型(如 IA-32)、节头表的偏移、节头表的表项大小以及表项个数
-
.text节- 编译后的代码部分
-
.rodata节- 只读数据,如printf格式串、switch跳转表等
-
.data节- 已初始化的全局变量
-
.bss节- 未初始化全局变量,仅是占位符,不占据任何实际磁盘空间。区分初始化和非初始化是为了空间效率
-
.symtab节- 存放函数和全局变量(符号表)信息,它不包括局部变量
-
.rel.text节.text节的重定位信息,用于重新修改代码段的指令中的地址信息
-
.rel.data节.data节的重定位信息,用于对被模块使用或定义的全局变量进行重定位的信息
-
.debug节- 调试用符号表 (gcc -g)
-
strtab节- 含symtab和debug节中符号及节名
-
Section header table(节头表)- 每个节的节名、偏移和大小

- C语言规定
- 未初始化的全局变量和局部静态变量的默认初始值为0
- 将未初始化变量(
.bss节)与已初始化变量(.data节)分开的 好处.data节中存放具体的初始值,需要占磁盘空间.bss节中无需存放初始值,只要说明.bss中的每个变量将来在执行时占用几个字节即可,因此.bss节实际上不占用磁盘空间,提高了磁盘空间利用率
- BSS(Block Started by Symbol)最初是UA-SAP汇编程序中所用的一个伪指令,用于为符号预留一块内存空间
- 所有未初始化的全局变量和局部静态变量都被汇总到
.bss节中,通过专门的"节头表(Section header table)"来说明应该为.bss节预留多大的空间
可重定位目标文件ELF头
- ELF头位于ELF文件开始,包含文件结构说明信息。分32位系统对应结构 和64位系统对应结构(32位版本、64位版本)
- 以下是32位系统对应的数据结构
定义了
- ELF魔数
- 魔数:文件开头几个字节通常用来确定文件的类型或格式
- a.out的魔数:
01H 07H - PE格式魔数:
4DH 5AH - 加载或读取文件时,可用魔数确认文件类型是否正确
- 版本
- 小端/大端
- 操作系统平台
- 目标文件的类型
- 机器结构类型
- 程序执行的入口地址
- 程序头表(段头表)的起始位置和长度
- 节头表的起始位置和长度等
1 | // size 52B |
读取ELF头信息
1 | > readelf -h main.o |
节头表
- 除ELF头之外,节头表是ELF可重定位目标文件中最重要的部分内容
- 描述每个节的节名、在文件中的偏移、大小、访问属性、对齐方式等
- 以下是32位系统对应的数据结构(每个表项占40B)
1 | typedef struct { |
读取节头表信息
1 | readelf -S test.o |
可重定位目标文件中,每个可装入节的起始地址总是0
执行视图
可执行目标文件
- 包含代码、数据(已初始化.data和未初始化.bss)
- 定义的所有变量和函数已有确定地址(虚拟地址空间中的地址)
- 符号引用处已被重定位,以指向所引用的定义符号
- 没有文件扩展名或默认为a.out(相当于Windows中的 .exe文件)
- 可被CPU直接执行,指令地址和指令给出的操作数地址都是虚拟地址
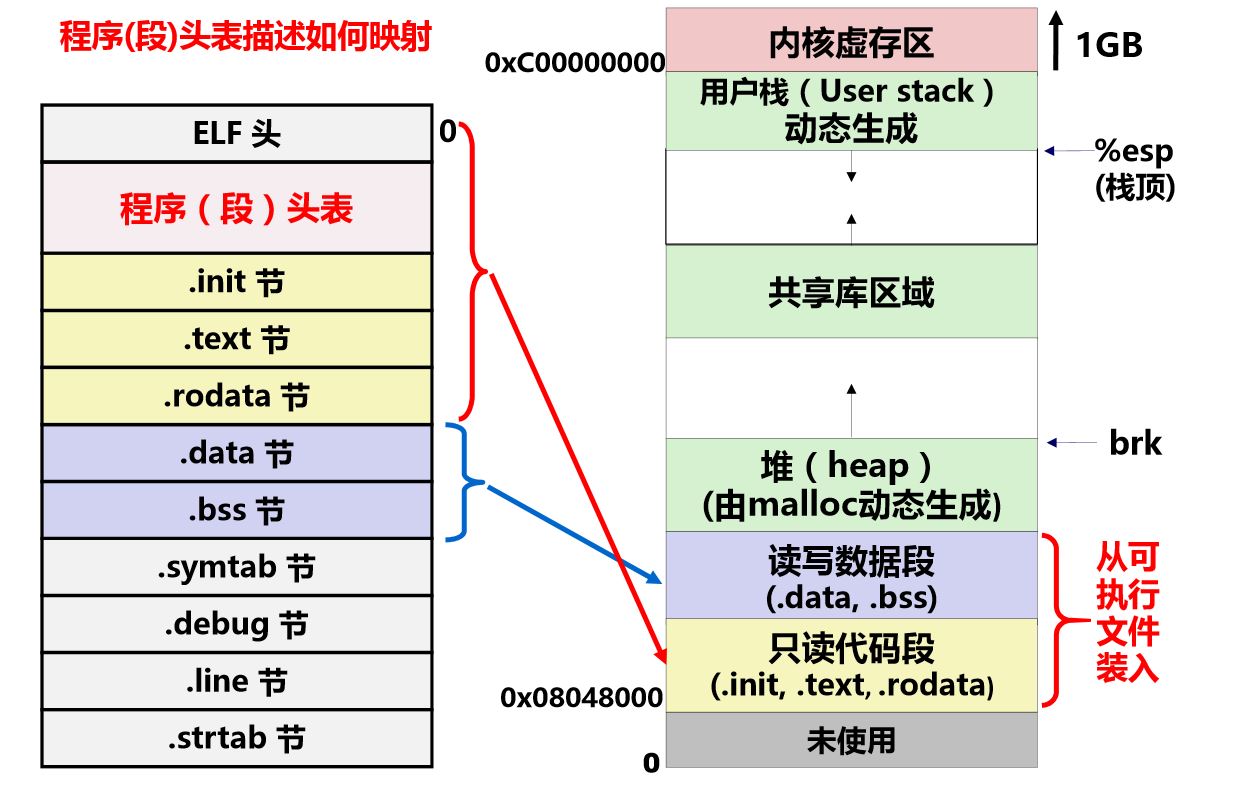
为了能执行,还需将具相同访问属性的节合并成段(Segment),并说明每个段的属性, 如:在可执行文件中的位移、大小、在虚拟空间中的位置、对齐方式、访问属性等
可执行目标文件格式
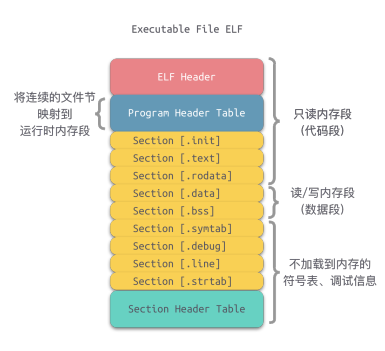
与可重定位文件有不同之处:
- ELF头中字段
e_entry给出执行程序时第一条指令的地址,而在可重定位文件中,此字段为0 - 多一个程序头表,也称段头表(segment header table),是一个结构数组
- 多一个
.init节,用于定义_init函数,该函数用来进行可执行目标文件开始执行时的初始化工作 - 少两个.rel节(无需重定位)
可执行目标文件ELF头
读取ELF头信息
1 | > readelf -h main.o |
可执行文件中的程序头表
- 序头表描述可执行文件中的节与虚拟 空间中的存储段之间的映射关系
- 一个表项(32B)说明虚拟地址空间中一个连续的段或一个特殊的节
1 | typedef struct { |
静态共享库
静态链接对象:
多个可重定位目标模块(.o文件)+ 静态库(标准库、自定义库)(.a文件,其中包含多个.o模块)
- 库函数模块:许多函数无需自己写,可使用共享的库函数
- 如数学库, 输入/输出库, 存储管理库,字符串处理等
- 对于自定义模块,避免以下两种极端做法
- 将所有函数都放在一个源文件中
- 修改一个函数需要对所有函数重新编译
- 时间和空间两方面的效率都不高
- 一个源文件中仅包含一个函数
- 需要程序员显式地进行链接
- 效率高,但模块太多,故太繁琐
- 将所有函数都放在一个源文件中
- 将所有相关的目标模块(.o)打包为一个单独的库文件(.a),称为静态库文件,也称存档文件(archive)
- 使用静态库,可增强链接器功能,使其能通过查找一个或多个库文件中定义的符号来解析符号
- 在构建可执行文件时,只需指定库文件名,链接器会自动到库中寻找那些应用程序用到的目标模块,并且只把用到的模块从库中拷贝出来
- 在gcc命令行中无需明显指定C标准库libc.a(默认库)
静态库的创建
打包指令:
1 | ar rs libc.a \ |
Archiver(归档器)允许增量更新,只要重新编译需修改的源码并将其.o文件替换到静态库中。
常用静态库
- libc.a ( C标准库 )
- 1392个目标文件(大约8 MB)
- 包含I/O、存储分配、信号处理、字符串处理、时间和日期、随机 数生成、定点整数算术运算
- libm.a (the C math library)
- 401 个目标文件(大约 1 MB)
- 浮点数算术运算(如sin, cos, tan, log, exp, sqrt, …)